VITS Pytorch
1.0.0
تبسيط الصينية | إنجليزي
هذا المشروع هو مشروع تخليق الكلام يعتمد على Pytorch ، باستخدام Vits. تعد Vits (الاستدلال المتغير مع التعلم العدائي للرسائل النصية من طرف إلى طرف) طريقة توليف الكلام. هذا النموذج من طرف إلى طرف سهل الاستخدام ولا يتطلب عمليات معقدة للغاية مثل محاذاة النص. يتم تدريبه مباشرة وتوليده بنقرة واحدة ، مما يقلل بشكل كبير من عتبة التعلم.
الجميع مرحب بهم لمسح الكود لإدخال كوكب المعرفة أو مجموعة QQ لمناقشة. يوفر Knowledge Planet ملفات طراز المشروع والمدونين المدونين الأخرى ملفات طرازات المشاريع ذات الصلة ، وكذلك الموارد الأخرى.
| مجموعة البيانات | اللغة (لهجة) | عدد المتحدثين | اسم المتحدث | تنزيل عنوان |
|---|---|---|---|---|
| bznsyp | الماندرين | 1 | صوت أنثى قياسي | انقر لتنزيل |
| مجموعة البيانات الكانتونية | الكانتونية | 10 | صوت الذكور 1 الفتيات 1 ··· | انقر لتنزيل |
conda install pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.6 -c pytorch -c nvidiaاستخدم PIP لتثبيت الأمر على النحو التالي:
python -m pip install mvits -U -i https://pypi.tuna.tsinghua.edu.cn/simpleيوصى بتثبيت الكود المصدري ، والذي يمكن أن يضمن استخدام أحدث التعليمات البرمجية.
git clone https://github.com/yeyupiaoling/VITS-Pytorch.git
cd VITS-Pytorch/
pip install . يدعم المشروع الجيل المباشر من قوائم بيانات BZNSYP و AISHELL3. أخذ BZNSYP كمثال ، قم بتنزيل BZNSYP إلى دليل dataset وإلغاء الضغط. ثم قم بتنفيذ برنامج create_list.py وقم بإنشاء جدول بيانات بالتنسيق التالي ، فإن التنسيق هو <音频路径>|<说话人名称>|<标注数据> . لاحظ أن بيانات وضع العلامات تتطلب لغة وضع العلامات. على سبيل المثال ، في الماندرين ، يجب عليك لف النص في [ZH] . تدعم اللغات الأخرى اليابانية: [JA] ، الإنجليزية: [EN] ، 한국어: [KO]. يمكن إنشاء مجموعات البيانات المخصصة في هذا التنسيق.
يوفر المشروع طريقتين لمعالجة النص ، وطرق معالجة النص المختلفة ، ويدعم لغات مختلفة ، وهما cjke_cleaners2 و chinese_dialect_cleaners . يتم تعديل هذا التكوين على dataset_conf.text_cleaner . يدعم cjke_cleaners2 اللغات {"普通话": "[ZH]", "日本語": "[JA]", "English": "[EN]", "한국어": "[KO]"} " chinese_dialect_cleaners {"普通话": "[ZH]", "日本語": "[JA]", "English": "[EN]", "粤语": "[GD]", "上海话": "[SH]", "苏州话": "[SZ]", "无锡话": "[WX]", "常州话": "[CZ]", "杭州话": "[HZ]", ·····}
dataset/BZNSYP/Wave/000001.wav|标准女声|[ZH]卡尔普陪外孙玩滑梯。[ZH]
dataset/BZNSYP/Wave/000002.wav|标准女声|[ZH]假语村言别再拥抱我。[ZH]
dataset/BZNSYP/Wave/000003.wav|标准女声|[ZH]宝马配挂跛骡鞍,貂蝉怨枕董翁榻。[ZH]
بعد الحصول على قائمة البيانات ، تحتاج إلى إنشاء قائمة بيانات صوتية. ما عليك سوى تنفيذ preprocess_data.py --train_data_list=dataset/bznsyp.txt لإنشاء قائمة بيانات phoneme. في هذه المرحلة ، تكون البيانات جاهزة.
dataset/BZNSYP/Wave/000001.wav|0|kʰa↓↑əɹ`↓↑pʰu↓↑ pʰeɪ↑ waɪ↓swən→ wan↑ xwa↑tʰi→.
dataset/BZNSYP/Wave/000002.wav|0|tʃ⁼ja↓↑ɥ↓↑ tsʰwən→jɛn↑p⁼iɛ↑ ts⁼aɪ↓ jʊŋ→p⁼ɑʊ↓ wo↓↑.
dataset/BZNSYP/Wave/000003.wav|0|p⁼ɑʊ↓↑ma↓↑ pʰeɪ↓k⁼wa↓ p⁼wo↓↑ lwo↑an→, t⁼iɑʊ→ts`ʰan↑ ɥæn↓ ts`⁼ən↓↑ t⁼ʊŋ↓↑ʊŋ→ tʰa↓.
الآن يمكنك البدء في تدريب النموذج. لا تحتاج المعلمات في ملف التكوين عمومًا إلى تعديلها. سيتم تعديل عدد المتحدثين واسم السماعة بواسطة preprocess_data.py . الشيء الوحيد الذي قد تحتاج إلى تعديله هو train.batch_size . إذا كانت ذاكرة الفيديو غير كافية ، فيمكن تقليل هذه المعلمة.
# 单卡训练
CUDA_VISIBLE_DEVICES=0 python train.py
# 多卡训练
CUDA_VISIBLE_DEVICES=0,1 torchrun --standalone --nnodes=1 --nproc_per_node=2 train.pyسجل إخراج التدريب:
[2023-08-28 21:04:42.274452 INFO ] utils:print_arguments:123 - ----------- 额外配置参数 -----------
[2023-08-28 21:04:42.274540 INFO ] utils:print_arguments:125 - config: configs/config.yml
[2023-08-28 21:04:42.274580 INFO ] utils:print_arguments:125 - epochs: 10000
[2023-08-28 21:04:42.274658 INFO ] utils:print_arguments:125 - model_dir: models
[2023-08-28 21:04:42.274702 INFO ] utils:print_arguments:125 - pretrained_model: None
[2023-08-28 21:04:42.274746 INFO ] utils:print_arguments:125 - resume_model: None
[2023-08-28 21:04:42.274788 INFO ] utils:print_arguments:126 - ------------------------------------------------
[2023-08-28 21:04:42.727728 INFO ] utils:print_arguments:128 - ----------- 配置文件参数 -----------
[2023-08-28 21:04:42.727836 INFO ] utils:print_arguments:131 - dataset_conf:
[2023-08-28 21:04:42.727909 INFO ] utils:print_arguments:138 - add_blank: True
[2023-08-28 21:04:42.727975 INFO ] utils:print_arguments:138 - batch_size: 16
[2023-08-28 21:04:42.728037 INFO ] utils:print_arguments:138 - cleaned_text: True
[2023-08-28 21:04:42.728097 INFO ] utils:print_arguments:138 - eval_sum: 2
[2023-08-28 21:04:42.728157 INFO ] utils:print_arguments:138 - filter_length: 1024
[2023-08-28 21:04:42.728204 INFO ] utils:print_arguments:138 - hop_length: 256
[2023-08-28 21:04:42.728235 INFO ] utils:print_arguments:138 - max_wav_value: 32768.0
[2023-08-28 21:04:42.728266 INFO ] utils:print_arguments:138 - mel_fmax: None
[2023-08-28 21:04:42.728298 INFO ] utils:print_arguments:138 - mel_fmin: 0.0
[2023-08-28 21:04:42.728328 INFO ] utils:print_arguments:138 - n_mel_channels: 80
[2023-08-28 21:04:42.728359 INFO ] utils:print_arguments:138 - num_workers: 4
[2023-08-28 21:04:42.728388 INFO ] utils:print_arguments:138 - sampling_rate: 22050
[2023-08-28 21:04:42.728418 INFO ] utils:print_arguments:138 - speakers_file: dataset/speakers.json
[2023-08-28 21:04:42.728448 INFO ] utils:print_arguments:138 - text_cleaner: cjke_cleaners2
[2023-08-28 21:04:42.728483 INFO ] utils:print_arguments:138 - training_file: dataset/train.txt
[2023-08-28 21:04:42.728539 INFO ] utils:print_arguments:138 - validation_file: dataset/val.txt
[2023-08-28 21:04:42.728585 INFO ] utils:print_arguments:138 - win_length: 1024
[2023-08-28 21:04:42.728615 INFO ] utils:print_arguments:131 - model:
[2023-08-28 21:04:42.728648 INFO ] utils:print_arguments:138 - filter_channels: 768
[2023-08-28 21:04:42.728685 INFO ] utils:print_arguments:138 - gin_channels: 256
[2023-08-28 21:04:42.728717 INFO ] utils:print_arguments:138 - hidden_channels: 192
[2023-08-28 21:04:42.728747 INFO ] utils:print_arguments:138 - inter_channels: 192
[2023-08-28 21:04:42.728777 INFO ] utils:print_arguments:138 - kernel_size: 3
[2023-08-28 21:04:42.728808 INFO ] utils:print_arguments:138 - n_heads: 2
[2023-08-28 21:04:42.728839 INFO ] utils:print_arguments:138 - n_layers: 6
[2023-08-28 21:04:42.728870 INFO ] utils:print_arguments:138 - n_layers_q: 3
[2023-08-28 21:04:42.728902 INFO ] utils:print_arguments:138 - p_dropout: 0.1
[2023-08-28 21:04:42.728933 INFO ] utils:print_arguments:138 - resblock: 1
[2023-08-28 21:04:42.728965 INFO ] utils:print_arguments:138 - resblock_dilation_sizes: [[1, 3, 5], [1, 3, 5], [1, 3, 5]]
[2023-08-28 21:04:42.728997 INFO ] utils:print_arguments:138 - resblock_kernel_sizes: [3, 7, 11]
[2023-08-28 21:04:42.729027 INFO ] utils:print_arguments:138 - upsample_initial_channel: 512
[2023-08-28 21:04:42.729058 INFO ] utils:print_arguments:138 - upsample_kernel_sizes: [16, 16, 4, 4]
[2023-08-28 21:04:42.729089 INFO ] utils:print_arguments:138 - upsample_rates: [8, 8, 2, 2]
[2023-08-28 21:04:42.729119 INFO ] utils:print_arguments:138 - use_spectral_norm: False
[2023-08-28 21:04:42.729150 INFO ] utils:print_arguments:131 - optimizer_conf:
[2023-08-28 21:04:42.729184 INFO ] utils:print_arguments:138 - betas: [0.8, 0.99]
[2023-08-28 21:04:42.729217 INFO ] utils:print_arguments:138 - eps: 1e-09
[2023-08-28 21:04:42.729249 INFO ] utils:print_arguments:138 - learning_rate: 0.0002
[2023-08-28 21:04:42.729280 INFO ] utils:print_arguments:138 - optimizer: AdamW
[2023-08-28 21:04:42.729311 INFO ] utils:print_arguments:138 - scheduler: ExponentialLR
[2023-08-28 21:04:42.729341 INFO ] utils:print_arguments:134 - scheduler_args:
[2023-08-28 21:04:42.729373 INFO ] utils:print_arguments:136 - gamma: 0.999875
[2023-08-28 21:04:42.729404 INFO ] utils:print_arguments:131 - train_conf:
[2023-08-28 21:04:42.729437 INFO ] utils:print_arguments:138 - c_kl: 1.0
[2023-08-28 21:04:42.729467 INFO ] utils:print_arguments:138 - c_mel: 45
[2023-08-28 21:04:42.729498 INFO ] utils:print_arguments:138 - enable_amp: True
[2023-08-28 21:04:42.729530 INFO ] utils:print_arguments:138 - log_interval: 200
[2023-08-28 21:04:42.729561 INFO ] utils:print_arguments:138 - seed: 1234
[2023-08-28 21:04:42.729592 INFO ] utils:print_arguments:138 - segment_size: 8192
[2023-08-28 21:04:42.729622 INFO ] utils:print_arguments:141 - ------------------------------------------------
[2023-08-28 21:04:42.729971 INFO ] trainer:__init__:53 - [cjke_cleaners2]支持语言:['日本語', '普通话', 'English', '한국어', "Mix": ""]
[2023-08-28 21:04:42.795955 INFO ] trainer:__setup_dataloader:119 - 训练数据:9984
epoch [1/10000]: 100%|██████████| 619/619 [05:30<00:00, 1.88it/s]]
[2023-08-25 16:44:25.205557 INFO ] trainer:train:168 - ======================================================================
epoch [2/10000]: 100%|██████████| 619/619 [05:20<00:00, 1.93it/s]s]
[2023-08-25 16:49:54.372718 INFO ] trainer:train:168 - ======================================================================
epoch [3/10000]: 100%|██████████| 619/619 [05:19<00:00, 1.94it/s]
[2023-08-25 16:55:21.277194 INFO ] trainer:train:168 - ======================================================================
epoch [4/10000]: 100%|██████████| 619/619 [05:18<00:00, 1.94it/s]
سيتم حفظ سجلات التدريب باستخدام VisualDL. يمكنك استخدام هذه الأداة لعرض تغييرات الخسارة وتأثيرات التوليف في الوقت الفعلي. ما عليك سوى تنفيذ visualdl --logdir=log/ --host=0.0.0.0 في الدليل الجذر للمشروع ، وزيارة http://<IP地址>:8040 لفتح الصفحة. التأثير كما يلي.
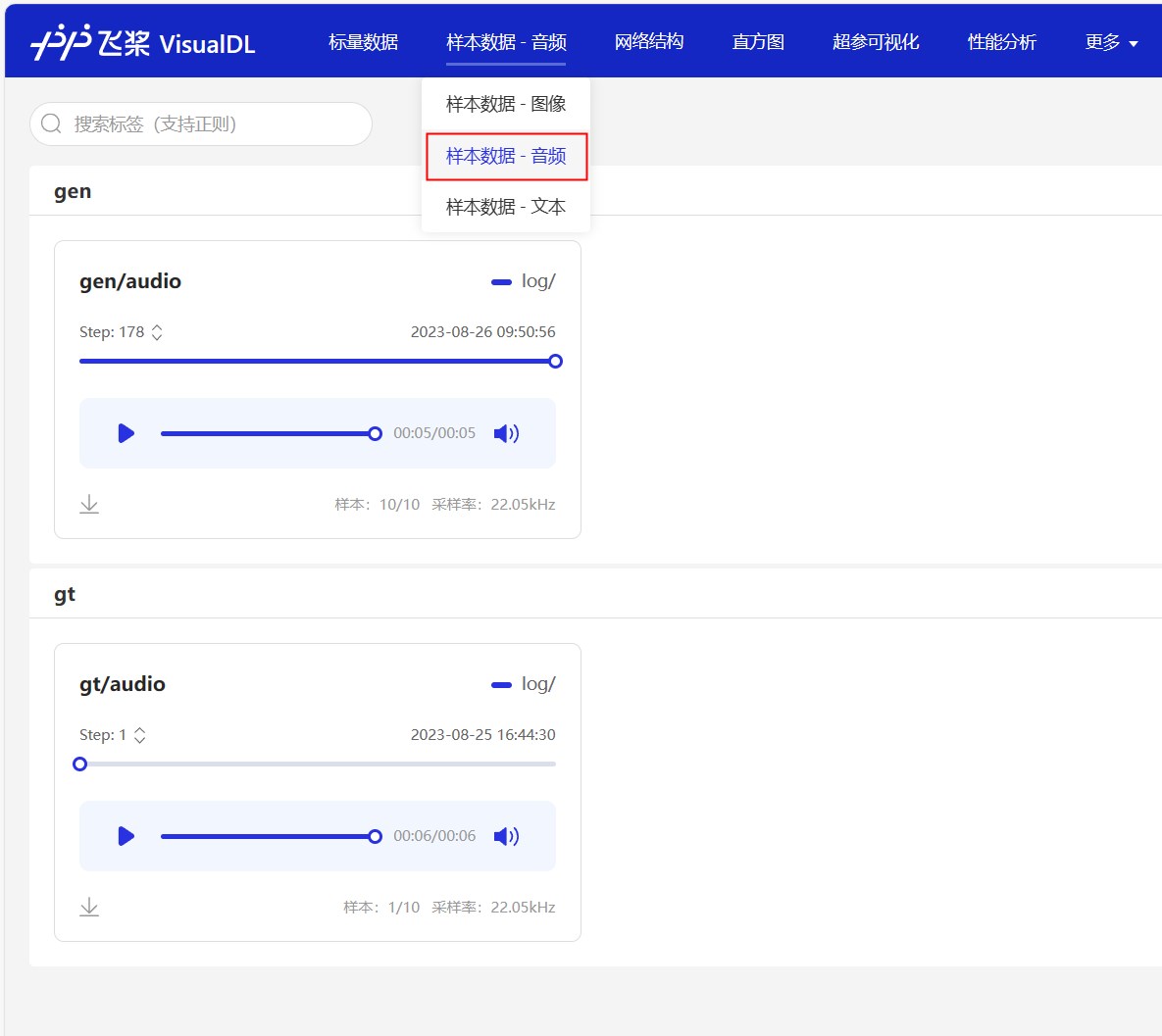
بعد التدريب على مستوى معين ، يمكنك البدء في استخدام النموذج للنطق. الأمر كما يلي. هناك ثلاثة معلمات رئيسية ، وهي --text يحدد النص الذي يجب توليفه. --language تحدد لغة النص المركب. إذا تم تحديد اللغة على أنها Mix ، فهي في وضع مختلط. يحتاج المستخدم إلى لف نص الدخل يدويًا بعلامة لغة. أخيرًا ، حدد معلمة مكبر --spk . اذهب وجربها بسرعة.
python infer.py --text= "你好,我是智能语音助手。 " --language=普通话 --spk=标准女声مكافأة دولار واحد لدعم المؤلف


