react native spokestack tray
Release 0.9.1

Un composant natif React pour ajouter Spokestack à toute application native React.
Installez cette bibliothèque avec les dépendances par les pairs
Un seul liner pour installer toutes les dépendances
npm install react-native-spokestack-tray react-native-spokestack @react-native-community/async-storage react-native-video react-native-haptic-feedback react-native-linear-gradient react-native-permissions$ npm install react-native-spokestack-tray react-native-spokestack
# Used for storing a simple boolean to turn on/off sound
$ npm install @react-native-community/async-storage
# Used to play TTS audio prompts.
# Despite its name, we think this is one of the best
# plugins (if not the best) for playing audio.
# In iOS, Audio and Video are intertwined anyway.
$ npm install react-native-video
# Used to show an animating gradient when Spokestack listens
$ npm install react-native-linear-gradient
# Used to check microphone and speech recognition permissions
$ npm install react-native-permissions
# Used to generate a haptic whenever Spokestack listens.
# This can be turned off, but the dependency is still needed.
$ npm install react-native-haptic-feedbackSuivez ensuite les instructions pour chaque plate-forme afin de relier React-Native-Spokestack à votre projet:
React-Native-Spokestack utilise des API relativement nouvelles uniquement disponibles dans iOS 13+. Assurez-vous de définir votre objectif de déploiement sur iOS 13.
Tout d'abord, ouvrez Xcode et allez dans Project -> Info pour définir l'objectif de déploiement iOS à 13,0 ou plus.
Définissez également le déploiement sur 13.0 sous Target -> Général -> Informations de déploiement.
Lorsque Flipper a été initié à React Native, certains chemins de recherche de bibliothèque ont été définis pour Swift. Il y a eu un problème de longue date avec les chemins de recherche par défaut dans les projets natifs React, car un chemin de recherche a été ajouté pour Swift 5.0 qui a empêché toute autre bibliothèque native React d'utiliser les API disponibles uniquement dans SWIFT 5.2 ou ultérieure. SpokeStack-IOS, une dépendance de React-Native-Spokestack utilise ces API et Xcode ne parviendra pas à construire.
Heureusement, le correctif est assez simple. Accédez à votre cible -> Créer des paramètres et recherchez des "chemins de recherche de bibliothèque".
Supprimez ""$(TOOLCHAIN_DIR)/usr/lib/swift-5.0/$(PLATFORM_NAME)"" de la liste.
Avant d'exécuter pod install , assurez-vous de faire les modifications suivantes.
platform :ios , '13.0' Nous devons également utiliser use_frameworks! dans notre podfile afin de soutenir les dépendances écrites dans Swift.
target 'SpokestackExample' do
use_frameworks!
#... Pour le moment, use_frameworks! Ne fonctionne pas avec les flipper, nous devons donc également désactiver les flipper. Retirez toutes les lignes liées aux flipper dans votre podfile. Dans React Native 0.63.2, ils ressemblent à ceci:
# X Remove or comment out these lines X
# use_flipper!
# post_install do |installer|
# flipper_post_install(installer)
# end
# XX Nous utilisons des permissions réactions-natives pour vérifier et demander l'autorisation du microphone (iOS et Android) et l'autorisation de reconnaissance vocale (iOS uniquement). Cette bibliothèque sépare chaque autorisation dans son propre pod pour éviter de gonfler votre application avec du code que vous n'utilisez pas. Ajoutez les pods suivants à votre podfile:
target 'SpokestackTrayExample' do
# ...
permissions_path = '../node_modules/react-native-permissions/ios'
pod 'Permission-Microphone' , :path => " #{ permissions_path } /Microphone.podspec"
pod 'Permission-SpeechRecognition' , :path => " #{ permissions_path } /SpeechRecognition.podspec" React Native 0.64.0 a cassé tous les projets utilisant use_frameworks! dans leurs podfiles.
Pour plus d'informations sur ce bogue, voir Facebook / React-Native # 31149.
Pour contourner ce problème, ajoutez ce qui suit à votre podfile:
# Moves 'Generate Specs' build_phase to be first for FBReactNativeSpec
post_install do | installer |
installer . pods_project . targets . each do | target |
if ( target . name &. eql? ( 'FBReactNativeSpec' ) )
target . build_phases . each do | build_phase |
if ( build_phase . respond_to? ( :name ) && build_phase . name . eql? ( '[CP-User] Generate Specs' ) )
target . build_phases . move ( build_phase , 0 )
end
end
end
end
end Retirez votre dossier PodFile.loc et pods existant pour assurer aucun conflit, puis installez les pods:
$ npx pod-installAjoutez ce qui suit à votre info.plist pour activer les autorisations. Dans Xcode, assurez-vous également que votre objectif de déploiement iOS est fixé à 13,0 ou plus.
< key >NSMicrophoneUsageDescription</ key >
< string >This app uses the microphone to hear voice commands</ string >
< key >NSSpeechRecognitionUsageDescription</ key >
< string >This app uses speech recognition to process voice commands</ string > Tandis que Flipper travaille sur la réparation de leur pod pour use_frameworks! , nous devons désactiver les flipper. Nous avons déjà supprimé les dépendances des flipper des pods ci-dessus, mais il reste un code dans appdelegate.m qui importe des flipper. Il y a deux façons de résoudre ce problème.
-DFB_SONARKIT_ENABLED=1 des drapeaux.Dans notre exemple d'application, nous avons fait l'option 1 et nous sommes partis dans le code Flipper au cas où ils fonctionnent à l'avenir et nous pouvons l'ajouter.
# import < AVFoundation/AVFoundation.h > Définissez la catégorie Audiossession. Il existe plusieurs configurations qui fonctionnent.
Ce qui suit est une suggestion qui devrait s'adapter à la plupart des cas d'utilisation:
- ( BOOL )application:(UIApplication *)application didFinishLaunchingWithOptions:( NSDictionary *)launchOptions
{
AVAudioSession *session = [AVAudioSession sharedInstance ];
[session setCategory: AVAudioSessionCategoryPlayAndRecord
mode: AVAudioSessionModeDefault
options: AVAudioSessionCategoryOptionDefaultToSpeaker | AVAudioSessionCategoryOptionAllowAirPlay | AVAudioSessionCategoryOptionAllowBluetoothA2DP | AVAudioSessionCategoryOptionAllowBluetooth
error: nil ];
[session setActive: YES error: nil ];
// ... L'utilisation de l'exemple utilise les ASR fournies par le système ( AndroidSpeechRecognizer et AppleSpeechRecognizer ). Cependant, AndroidSpeechRecognizer n'est pas disponible sur 100% des appareils. Si votre application prend en charge un appareil qui n'a pas de reconnaissance vocale intégrée, utilisez à la place SpokeStack ASR en définissant le profile sur un profil Spokestack à l'aide de l'hélice profile .
Voir notre documentation ASR pour plus d'informations.
// ...
ext {
// Minimum SDK is 21
minSdkVersion = 21
// ...
dependencies {
// Minimium gradle is 3.0.1+
// The latest React Native already has this
classpath( " com.android.tools.build:gradle:3.5.3 " ) Ajoutez les autorisations nécessaires à votre AndroidManifest.xml . La première autorisation est déjà là déjà. La seconde est nécessaire pour utiliser le microphone.
<!-- For TTS -->
< uses-permission android : name = " android.permission.INTERNET " />
<!-- For wakeword and ASR -->
< uses-permission android : name = " android.permission.RECORD_AUDIO " />
<!-- For ensuring no downloads happen over cellular, unless forced -->
< uses-permission android : name = " android.permission.ACCESS_NETWORK_STATE " /> import SpokestackTray , { listen } from 'react-native-spokestack-tray'
// ...
export default function ConversationHandler ( { navigation } ) {
return (
< SpokestackTray
clientId = { process . env . SPOKESTACK_CLIENT_ID }
clientSecret = { process . env . SPOKESTACK_CLIENT_SECRET }
handleIntent = { ( intent , slots , utterance ) => {
switch ( intent ) {
// These cases would be for all
// the possible intents defined in your NLU.
case 'request.select' :
// As an example, search with some service
// with the given value from the NLU
const recipe = SearchService . find ( slots . recipe ?. value )
// An example of navigating to some scene to show
// data, a recipe in our example.
navigation . navigate ( 'Recipe' , { recipe } )
return {
node : 'info.recipe' ,
prompt : 'We found your recipe!'
}
default :
return {
node : 'welcome' ,
prompt : 'Let us help you find a recipe.'
}
}
} }
// The NLU models are downloaded and then cached
// when the app is first installed.
// See https://spokestack.io/docs/concepts/nlu
// for more info on NLU.
nlu = { {
nlu : 'https://somecdn/nlu.tflite' ,
vocab : 'https://somecdn/vocab.txt' ,
metadata : 'https://somecdn/metadata.json'
} }
/>
)
} Pour inclure des fichiers de modèle localement dans votre application (plutôt que de les télécharger à partir d'un CDN), vous devez également ajouter les extensions nécessaires afin que les fichiers puissent être inclus par Babel. Pour ce faire, modifiez votre metro.config.js .
const defaults = require ( 'metro-config/src/defaults/defaults' )
module . exports = {
resolver : {
// json is already in the list
assetExts : defaults . assetExts . concat ( [ 'tflite' , 'txt' , 'sjson' ] )
}
}Incluez ensuite les fichiers du modèle à l'aide d'objets source:
< SpokestackTray
clientId = { process . env . SPOKESTACK_CLIENT_ID }
clientSecret = { process . env . SPOKESTACK_CLIENT_SECRET }
handleIntent = { handleIntent }
wakeword = { {
filter : require ( './filter.tflite' ) ,
detect : require ( './detect.tflite' ) ,
encode : require ( './encode.tflite' )
} }
nlu = { {
model : require ( './nlu.tflite' ) ,
vocab : require ( './vocab.txt' ) ,
// Be sure not to use "json" here.
// We use a different extension (.sjson) so that the file is not
// immediately parsed as json and instead
// passes a require source object to Spokestack.
// The special extension is only necessary for local files.
metadata : require ( './metadata.sjson' )
} }
/> Ce n'est pas nécessaire. Passez les URL distantes aux mêmes options de configuration et les fichiers seront téléchargés et mis en cache lors de l'appel pour la première fois initialize .
Voir le guide contribuant pour apprendre à contribuer au référentiel et au flux de travail de développement.
<SpokestackTray /> • Buttonwidth Optional : number (par défaut: 60 )
Largeur (et hauteur) du bouton micro
src / spokestacktray.tsx: 132
• ClientId : string
Vos jetons de spokestack générés dans votre compte Spokestack à https://spokestack.io/Account. Créez un compte gratuit puis générez un jeton. Ceci provient du champ "ID".
src / spokestacktray.tsx: 74
• Clientscret : string
Vos jetons de spokestack générés dans votre compte Spokestack à https://spokestack.io/Account. Créez un compte gratuit puis générez un jeton. Ceci provient du domaine "secret".
src / spokestacktray.tsx: 81
• CloseLay Optional : number (par défaut: 0 )
Combien de temps à attendre pour fermer le plateau après avoir parlé (MS)
src / spokestacktray.tsx: 134
• Débogue Optional : boolean
Afficher les messages de débogage de React-Native-Spokestack
src / spokestacktray.tsx: 136
• Durée Optional : number (par défaut: 500 )
Durée de l'animation du plateau (MS)
src / spokestacktray.tsx: 138
• Emplacement Optional : EasingFunction (par défaut: SEMING.BEZIER (0,77, 0,41, 0,2, 0,84) )
Fonction d'assouplissement pour l'animation du plateau
src / spokestacktray.tsx: 140
• Optional OPTIONNELS : string []
Tous les nœuds de ce tableau devraient mettre fin à la conversation et fermer le plateau
src / spokestacktray.tsx: 150
• Fontfamily Optional : string
Police à utiliser pour "écouter ...", "Chargement ...", et le texte de bulle de chat.
src / spokestacktray.tsx: 155
• GradientColors Optional : string [] (par défaut: ["# 61FAE9", "# 2F5BEA"] )
Couleurs pour le gradient linéaire montré lors de l'écoute peut être n'importe quel nombre de couleurs (recommandée: 2-3)
src / spokestacktray.tsx: 160
• Greclement Optional : boolean (par défaut: false )
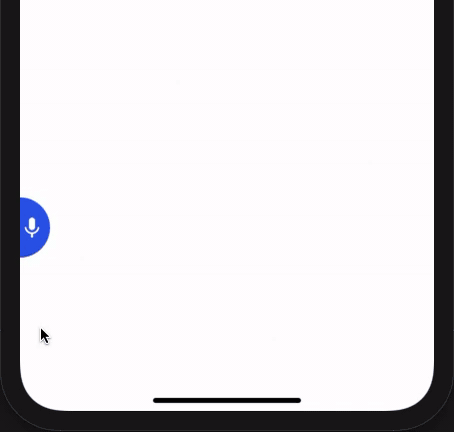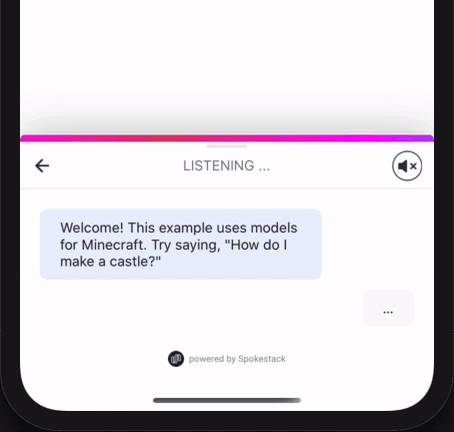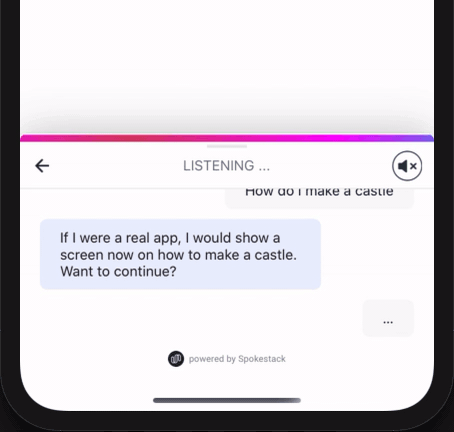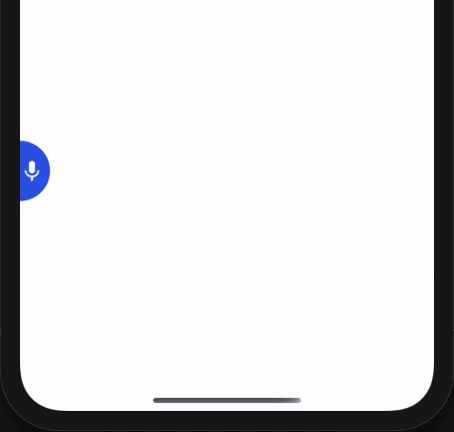
Que ce soit pour saluer l'utilisateur avec un message de bienvenue lorsque le plateau s'ouvre. Remarque: handleIntent doit répondre à l'intention de "saluer".
src / spokestacktray.tsx: 166
• Haptique Optional : boolean (par défaut: true )
Réglez ceci sur False pour désactiver l'haptique qui est joué chaque fois que le plateau commence à écouter.
src / spokestacktray.tsx: 171
• Mot-clé Optional : KeywordConfig
Configuration de la reconnaissance des mots clés
Les champs de filtre, de détection, d'encodage et de métadonnées acceptent 2 types de valeurs.
require ou import (par exemple model: require('./nlu.tflite') ))Voir https://www.spokestack.io/docs/concepts/keywords pour en savoir plus sur la reconnaissance des mots clés.
example
// ...
keyword = { {
detect : 'https://s.spokestack.io/u/UbMeX/detect.tflite' ,
encode : 'https://s.spokestack.io/u/UbMeX/encode.tflite' ,
filter : 'https://s.spokestack.io/u/UbMeX/filter.tflite' ,
metadata : 'https://s.spokestack.io/u/UbMeX/metadata.json'
} }Vous pouvez également télécharger des modèles à l'avance et les inclure à partir de fichiers locaux. Remarque: Cela nécessite une modification de votre métro.config.js. Pour plus d'informations, voir "Inclure des fichiers de modèle dans votre bundle d'applications" dans le Readme.md.
// ...
keyword = { {
detect : require ( './detect.tflite' ) ,
encode : require ( './encode.tflite' ) ,
filter : require ( './filter.tflite' ) ,
// IMPORTANT: a special extension is used for local metadata JSON files (`.sjson`) when using `require` or `import`
// so the file is not parsed when included but instead imported as a source object. This makes it so the
// file is read and parsed by the underlying native libraries instead.
metadata : require ( './metadata.sjson' )
} }La configuration des mots clés accepte également un champ de classes pour le moment où les métadonnées ne sont pas spécifiées.
// ...
keyword = { {
detect : require ( './detect.tflite' ) ,
encode : require ( './encode.tflite' ) ,
filter : require ( './filter.tflite' ) ,
classes : [ 'one' , 'two' , 'three]
} } src / spokestacktray.tsx: 221
• Minheight Optional : number (par défaut: 170 )
Hauteur minimale pour le plateau
src / spokestacktray.tsx: 223
• NLU : NLUConfig
Le modèle NLU TensorFlow Lite (.tflite), les métadonnées JSON et le vocabulaire NLU (.txt)
Les 3 champs acceptent 2 types de valeurs.
require ou import (par exemple model: require('./nlu.tflite') ))Voir https://spokestack.io/docs/concepts/nlu pour en savoir plus sur NLU.
// ...
nlu = { {
model : 'https://somecdn.com/nlu.tflite' ,
vocab : 'https://somecdn.com/vocab.txt' ,
metadata : 'https://somecdn.com/metadata.json'
} }Vous pouvez également transmettre des fichiers locaux. Remarque: Cela nécessite une modification de votre métro.config.js. Pour plus d'informations, voir "Inclure des fichiers de modèle dans votre bundle d'applications" dans le Readme.md.
// ...
nlu = { {
model : require ( './nlu.tflite' ) ,
vocab : require ( './vocab.txt' ) ,
// IMPORTANT: a special extension is used for local metadata JSON files (`.sjson`) when using `require` or `import`
// so the file is not parsed when included but instead imported as a source object. This makes it so the
// file is read and parsed by the underlying native libraries instead.
metadata : require ( './metadata.sjson' )
} } src / spokestacktray.tsx: 130
• Orientation Optional : "left" | "right" (par défaut: "gauche" )
Le bouton du plateau peut être orienté de chaque côté de l'écran
src / spokestacktray.tsx: 235
• PrimatingColor Optional : string (par défaut: "# 2f5bea" )
Cette couleur est utilisée pour thème le plateau et est utilisée dans le bouton micro et les bulles de la parole.
src / spokestacktray.tsx: 240
• Profil Optional : PipelineProfile
Le profil de configuration de Spokestack à passer pour réagir-Native-Spokestack. Ceux-ci sont disponibles auprès de React-Native-Spokestack à partir de la version 4.0.0.
Si les fichiers de configuration de wakeword sont spécifiés, la valeur par défaut sera TFLITE_WAKEWORD_NATIVE_ASR . Sinon, la valeur par défaut est PTT_NATIVE_ASR .
import SpokestackTray from 'react-native-spokestack-tray'
import { PipelineProfile } from 'react-native-spokestack'
// ...
< SpokestackTray
profile = { PipelineProfile . TFLITE_WAKEWORD_SPOKESTACK_ASR }
// ... src / spokestacktray.tsx: 261
• Refreshmodels Optional : boolean
Utilisez ceci pour actualiser les modèles Wakeword, Keyword et NLU sur l'appareil (Force l'écrasement). <SpokestackTray refreshModels={process.env.NODE_ENV !== 'production'} ... />
src / spokestacktray.tsx: 268
• SayGreeting Optional : boolean (par défaut: true )
Que ce soit pour parler la salutation ou afficher uniquement une bulle de chat avec le message de salut, même si le son est allumé.
src / spokestacktray.tsx: 274
• Optional SoundOffImage : ReactNode (par défaut: (<Image Source = {SoundOffImage} Style = {{Width: 30, Height: 30}} />) )
Remplacez l'image sonore en passant un composant d'image React
src / spokestacktray.tsx: 278
• Optional SoundOnImage : ReactNode (par défaut: (<Image Source = {SoundOnImage} Style = {{Width: 30, Height: 30}} />) )
Remplacez le son sur l'image en passant un composant d'image React
src / spokestacktray.tsx: 276
• SpokestackConfig Optional : Partial SpokestackConfig
Passer des options directement à la fonction spokestack.Initialize () à partir de React-Native-Spokestack. Voir https://github.com/spokestack/react-native-pokestack pour les options disponibles.
src / spokestacktray.tsx: 285
• StarTheight Optional : number (par défaut: 220 )
Hauteur de départ pour le plateau
src / spokestacktray.tsx: 287
• Style Optional : false | RegisteredStyle ViewStyle | Value | AnimatedInterpolation | WithAnimatedObject ViewStyle | WithAnimatedArray < false | ViewStyle | RegisteredStyle ViewStyle | RecursiveArray < false | ViewStyle | RegisteredStyle < ViewStyle >> | readonly ( false | ViewStyle | RegisteredStyle ViewStyle ) []>
Cet accessoire de style est passé au conteneur du plateau
src / spokestacktray.tsx: 289
• TTSformat Optional : TTSFormat (par défaut: TTSformat.Text )
Le format du texte transmis à Spokestack.SyntheSize
src / spokestacktray.tsx: 291
• Voix Optional : string (par défaut: "démo" )
Une clé pour une voix dans Spokestack TTS, passée à Spokestack.SyntheSize. Cela ne peut être modifié que si vous avez créé une voix personnalisée à l'aide d'un compte Spokestack Maker. Voir https://spokestack.io/pricing#maker. S'il n'est pas spécifié, la voix "démo" gratuite de Spokestack est utilisée.
src / spokestacktray.tsx: 298
• Wakeword Optional : WakewordConfig
Les modèles NLU TensorFlow Lite (.tflite) pour Wakeword.
Les 3 champs acceptent 2 types de valeurs.
require ou import (par exemple model: require('./nlu.tflite') ))Voir https://spokestack.io/docs/concepts/wakeword-models pour en savoir plus sur le wakeword
SpokeStack propose des exemples de fichiers de modèle de wakeword ("Spokestack"):
// ...
wakeword = { {
detect : 'https://s.spokestack.io/u/hgmYb/detect.tflite' ,
encode : 'https://s.spokestack.io/u/hgmYb/encode.tflite' ,
filter : 'https://s.spokestack.io/u/hgmYb/filter.tflite'
} }Vous pouvez également télécharger ces modèles à l'avance et les inclure à partir de fichiers locaux. Remarque: Cela nécessite une modification de votre métro.config.js. Pour plus d'informations, voir "Inclure des fichiers de modèle dans votre bundle d'applications" dans le Readme.md.
// ...
wakeword = { {
detect : require ( './detect.tflite' ) ,
encode : require ( './encode.tflite' ) ,
filter : require ( './filter.tflite' )
} } src / spokestacktray.tsx: 332
▸ EDITTRANScript Optional ( transcript ): string
Modifiez la transcription avant la classification et avant que la bulle de la réponse de l'utilisateur ne soit affichée.
| Nom | Taper |
|---|---|
transcript | string |
string
src / spokestacktray.tsx: 145
▸ HandleIntent ( intent , slots? utterance? ): [IntentResult](#IntentResult)
Cette fonction tire une intention du NLU et renvoie un objet avec un nom de nœud de conversation unique (que vous définissez) et une invite à être traitée par TTS et parlé.
Remarque: l'invite n'est affichée que dans une bulle de chat si le son a été désactivé.
| Nom | Taper |
|---|---|
intent | string |
slots? | SpokestackNLUSlots |
utterance? | string |
[IntentResult](#IntentResult)
src / spokestacktray.tsx: 91
▸ Optional OnClose (): void
Appelé chaque fois que le plateau a fermé
void
src / spokestacktray.tsx: 227
▸ Optional FACTIONNELLE ( e ): void
Appelé chaque fois qu'il y a une erreur de Spokestack
| Nom | Taper |
|---|---|
e | SpokestackErrorEvent |
void
src / spokestacktray.tsx: 229
▸ Optional Onopen (): void
Appelé chaque fois que le plateau s'est ouvert
void
src / spokestacktray.tsx: 231
• Données Optional : any
Toutes les autres données que vous voudrez peut-être ajouter
src / spokestacktray.tsx: 64
• Optional sans interruption : boolean
Réglé sur true pour arrêter le Wakeword Recognizer lors de la lecture de l'invite.
src / spokestacktray.tsx: 62
• Node : string
Une clé définie par l'utilisateur pour indiquer où l'utilisateur se trouve dans la conversation inclut cela dans l'hélice exitNodes si Spokestack ne doit pas écouter après avoir dit l'invite.
src / spokestacktray.tsx: 55
• Invite : string
Sera transformé en discours à moins que le plateau ne soit en mode silencieux
src / spokestacktray.tsx: 57
<SpokestackTray />Ces méthodes sont disponibles à partir du composant SpokeStackTray. Utilisez une réaction React pour accéder à ces méthodes.
const spokestackTray = useRef ( null )
// ...
< SpokestackTray ref = { spokestackTray }
// ...
spokestackTray . current . say ( 'Here is something for Spokestack to say' ) Remarque : Dans la plupart des cas, vous devez appeler listen au lieu open .
▸ Open (): void
Ouvrez le plateau, saluez (le cas échéant) et écoutez
void
src / spokestacktray.tsx: 743
▸ Close (): void
Fermez le plateau, arrêtez d'écouter et redémarrez le wakeword
void
src / spokestacktray.tsx: 754
▸ Dites ( input ): Promise void
Passe l'entrée de SpokeStack.SyntheSize (), joue l'audio et ajoute une bulle de la parole.
| Nom | Taper |
|---|---|
input | string |
Promise void
src / spokestacktray.tsx: 766
▸ AddBubble ( bubble ): void
Ajouter une bulle (système ou utilisateur) à l'interface de chat
| Nom | Taper |
|---|---|
bubble | Bubble |
void
src / spokestacktray.tsx: 799
• Isleft : boolean
src / composants / discoursbubbles.tsx: 9
• Texte : string
src / composants / discoursbubbles.tsx: 8
▸ toggleSilent (): Promise boolean
Basquer le mode silencieux
Promise boolean
src / spokestacktray.tsx: 816
▸ Issilent (): boolean
Renvoie si le plateau est en mode silencieux
boolean
src / spokestacktray.tsx: 828
Ces fonctions sont disponibles en tant qu'exportations de React-Native-Spokestack-Tray
▸ écouter (): Promise void
Dit au pipeline de discours de Spokestack pour commencer à écouter. Demande également l'autorisation d'écouter si nécessaire. Il tentera de démarrer le pipeline avant de l'activer s'il n'est pas déjà démarré. Cette fonction ne fera rien si l'application est en arrière-plan.
import { listen } from 'react-native-spokestack-tray'
try {
await listen()
} catch (error) {
console.error(error)
}
Promise void
src / spokestack.ts: 21
▸ stopShetening (): Promise void
Promise void
src / spokestack.ts: 30
▸ Const isidening (): Promise boolean
Renvoie si Spokestack écoute actuellement
console . log ( `isListening: ${ await isListening ( ) } ` ) Promise boolean
src / index.ts: 19
▸ Const isInitialized (): Promise boolean
Renvoie si le spokestack a été initialisé
console . log ( `isInitialized: ${ await isInitialized ( ) } ` ) Promise boolean
src / index.ts: 27
▸ Const isstarted (): Promise boolean
Renvoie si le pipeline de discours a été démarré
console . log ( `isStarted: ${ await isStarted ( ) } ` ) Promise boolean
src / index.ts: 35
▸ Const AddeventListener ( eventType , listener , context? ): EmitterSubscription
Bind à tout événement émis par les bibliothèques natives Les événements sont: "reconnaître", "partial_recognise", "erreur", "activer", "désactiver" et "délai d'expiration". Voir le bas du Readme.md pour les descriptions des événements.
useEffect ( ( ) => {
const listener = addEventListener ( 'recognize' , onRecognize )
// Unsubscribe by calling remove when components are unmounted
return ( ) => {
listener . remove ( )
}
} , [ ] ) | Nom | Taper |
|---|---|
eventType | string |
listener | ( event : any ) => void |
context? | Object |
EmitterSubscription
src / index.ts: 51
▸ Const RoveenEventListener ( eventType , listener ): void
Supprimer un écouteur d'événements
removeEventListener ( 'recognize' , onRecognize ) | Nom | Taper |
|---|---|
eventType | string |
listener | (... args : any []) => any |
void
src / index.ts: 59
▸ Const RemovealLListeners (): void
Supprimer tous les auditeurs existants
componentWillUnmount ( ) {
removeAllListeners ( )
} void
src / index.ts: 69
Utilisez addEventListener() , removeEventListener() et removeAllListeners() pour ajouter et supprimer les gestionnaires d'événements. Tous les événements sont disponibles dans iOS et Android.
| Nom | Données | Description |
|---|---|---|
| reconnaître | { transcript: string } | Tiré chaque fois que la reconnaissance de la parole se termine avec succès. |
| partial_recognise | { transcript: string } | Tiré chaque fois que la transcription change pendant la reconnaissance vocale. |
| commencer | null | Tiré lorsque le pipeline de la parole commence (qui commence à écouter le wakeword ou commence VAD). |
| arrêt | null | Tiré lorsque le pipeline de discours s'arrête. |
| activer | null | Tiré lorsque le pipeline de la parole s'active, soit via le VAD, Wakeword, soit lors de l'appel .activate() . |
| désactiver | null | Tiré lorsque le pipeline de discours désactive. |
| jouer | { playing: boolean } | Tiré lorsque la lecture TTS commence et s'arrête. Voir la fonction speak() . |
| temps mort | null | Tiré lorsqu'un pipeline actif époque le manque de reconnaissance. |
| tracer | { message: string } | Tiré pour les messages de trace. La verbosité est déterminée par l'option traceLevel . |
| erreur | { error: string } | Tiré lorsqu'il y a une erreur dans Spokestack. |
Lorsqu'un événement d'erreur est déclenché, toutes les promesses existantes sont rejetées.
Ces fonctions d'utilité sont utilisées par Spokestack pour vérifier l'autorisation des microphones sur iOS et l'autorisation de reconnaissance Android et de la parole sur iOS.
▸ CHECKSPEECH (): Promise boolean
Cette fonction peut être utilisée pour vérifier si l'utilisateur a donné l'autorisation nécessaire pour la parole. Sur iOS, cela comprend à la fois le microphone et la recnogition de la parole. Sur Android, seul le microphone est nécessaire.
import { checkSpeech } from 'react-native-spokestack-tray'
// ...
const hasPermission = await checkSpeech ( ) Promise boolean
src / utils / permissions.ts: 78
▸ requestSpeech (): Promise boolean
Cette fonction peut être utilisée pour demander réellement l'autorisation nécessaire pour la parole. Sur iOS, cela comprend à la fois le microphone et la recnogition de la parole. Sur Android, seul le microphone est nécessaire.
Remarque: Si l'utilisateur a diminué dans le passé sur iOS, l'utilisateur doit être envoyé aux paramètres.
import { requestSpeech } from 'react-native-spokestack-tray'
// ...
const hasPermission = await requestSpeech ( ) Promise boolean
src / utils / permissions.ts: 106
Mit


