? Rag de traitement des documents multimodaux avec Langchain?
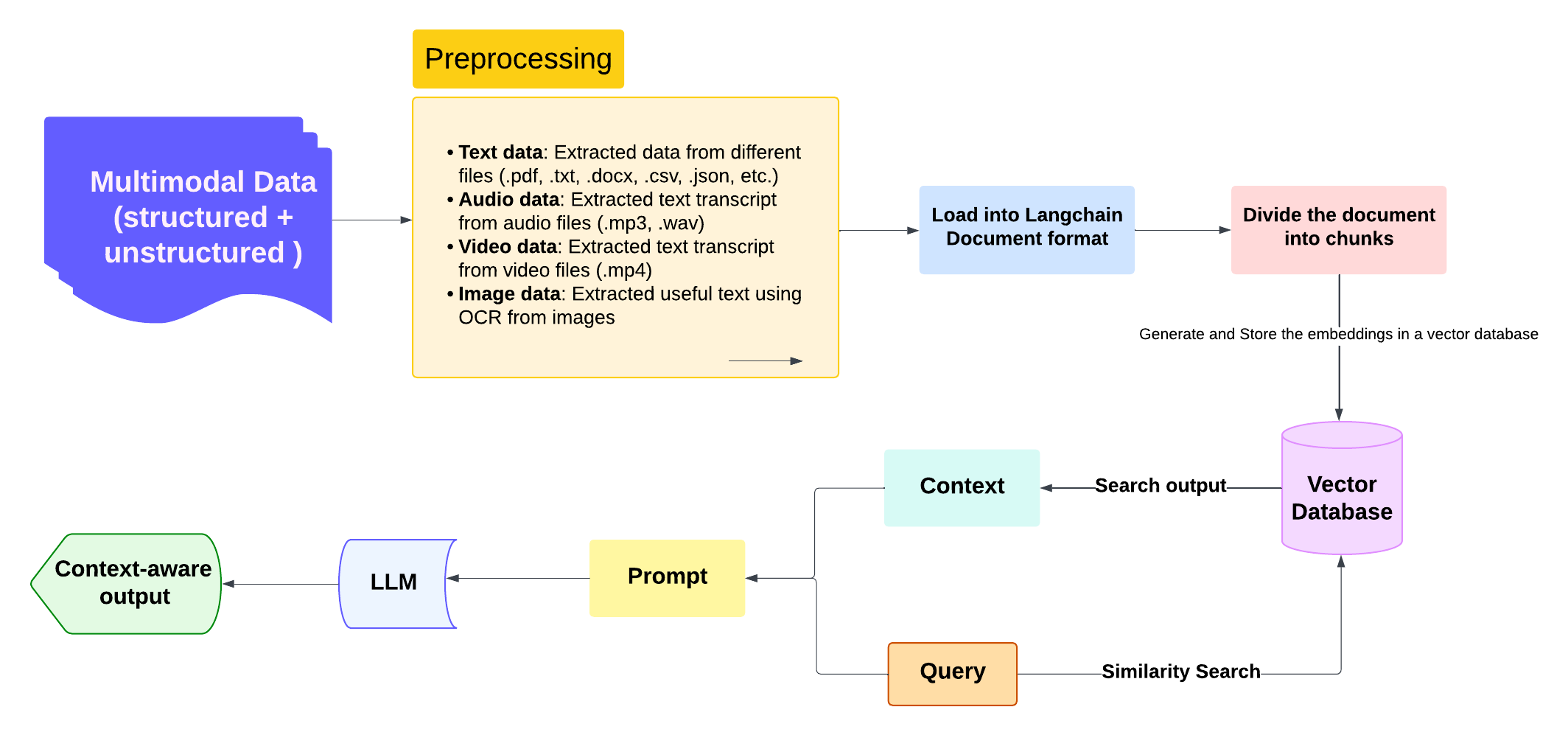
Ce projet est une application rationalisée pour le traitement des documents multimodaux et interrogeant une base de données Milvus . Il exploite des outils de pointe comme Langchain , Transformers , Easyocr et autres pour le traitement, le stockage et l'interrogation du texte extrait de divers types de fichiers.
Caractéristiques
Télécharger le traitement des fichiers :
- Prend en charge plusieurs types de fichiers:
audio , video , image , text , csv , yaml , json , docx et pdf . - Extrait le contenu du texte en utilisant:
- ? Audio :
speech_recognition et pydub . - ? Vidéo : Logique d'extraction personnalisée.
- ? ️ Image :
EasyOCR . - ? Texte / journaux / documents : chargeurs de Langchain.
Intégration de Milvus :
- ? ️ stores des intégres de documents traités pour une requête basée sur la similitude.
- ? Utilise
HuggingFaceEmbeddings pour générer des représentations vectorielles.
? Interface de requête :
- Interface de requête en langage naturel.
- Implémente un pipeline de génération (RAG) de récupération (RAG) pour les réponses axées sur l'IA.
Installation
? Condition préalable
- Python 3.8+
- Gestionnaire de packages
pip ou conda - GPU compatible CUDA (facultatif, pour un traitement plus rapide)
? Fourche et cloner le référentiel
Fourk Le référentiel : accédez au référentiel GitHub-architecture Rag-Architecture et cliquez sur Fork .
Clone le référentiel fourchu :
git clone https://github.com/ < your-username > /RAG-Architecture.git
cd RAG-Architecture
? Installer des dépendances
pip install -r requirements.txt
Usage
Démarrer la demande
Exécutez l'application Streamlit:
Modes d'application
? Télécharger des fichiers:
- Téléchargez un fichier pour traiter et stocker son contenu dans Milvus.
- Affiche le contenu extrait et les stockage des intégres dans la base de données.
❓ Query:
- Entrez une question pour rechercher et récupérer les informations pertinentes de la base de données Milvus.
- Renvoie les réponses générées par l'AI à l'aide du pipeline de chiffon de Langchain.
? Structure de fichiers
# # ? **File Structure**
` ` ` bash
project/
│
├── app.py # Main Streamlit application
├── requirements.txt # ? Python dependencies
├── utils/ # Utility modules
│ ├── audio_utils.py # ? Audio file processing
│ ├── video_utils.py # ? Video file processing
│ ├── image_utils.py # ?️ Image file processing
│ ├── document_loaders.py # Document processing loaders
│ ├── milvus_client.py # ?️ Initializes Milvus database
│
├── milvus_database.db # ?️ Milvus database file (auto-created)
├── Dataset # Folder to store datasets
├── Images # ? Folder for storing images
? Modules clés
app.py
? Logique d'application principale
- Gère les téléchargements de fichiers, le traitement des documents et la requête.
utils/
- ? Audio : divise l'audio en morceaux et transcrit du texte.
- ? Vidéo : traite les fichiers vidéo pour extraire et analyser le contenu.
- ? ️ Image : utilise Easyocr pour extraire du texte.
- Journaux / documents : traite les fichiers CSV, YAML, JSON et PDF en documents structurés Langchain.
Exemple de workflow
? Téléchargement d'un fichier
- Sélectionnez le mode "Télécharger les fichiers" .
- Téléchargez un fichier (par exemple,
example.pdf ). - Traiter et stocker le fichier dans la base de données.
❓ Interroger la base de données
- Sélectionnez le mode "Requête" .
- Entrez une question de langue naturelle.
- Recevez une réponse concise basée sur des faits.
? Améliorations futures
- ? Ajoutez des capacités de requête plus avancées.
- Améliorez la prise en charge des types de fichiers et des intégres supplémentaires.
- ⚡ Améliorer l'évolutivité des ensembles de données plus grands.
Licence Ce projet est autorisé sous la licence du MIT .
? Remerciements
- Rationaliser pour l'interface utilisateur interactive.
- Langchain et Milvus pour le traitement des documents, la récupération et la base de données vectorielle.
- ? Transformers pour la génération d'intégration.
- ? ️ Easyocr pour l'extraction de texte d'image.
- ? MoviePy pour le traitement vidéo.


