? Multimodal Dokumentverarbeitung Lappen mit Langchain?
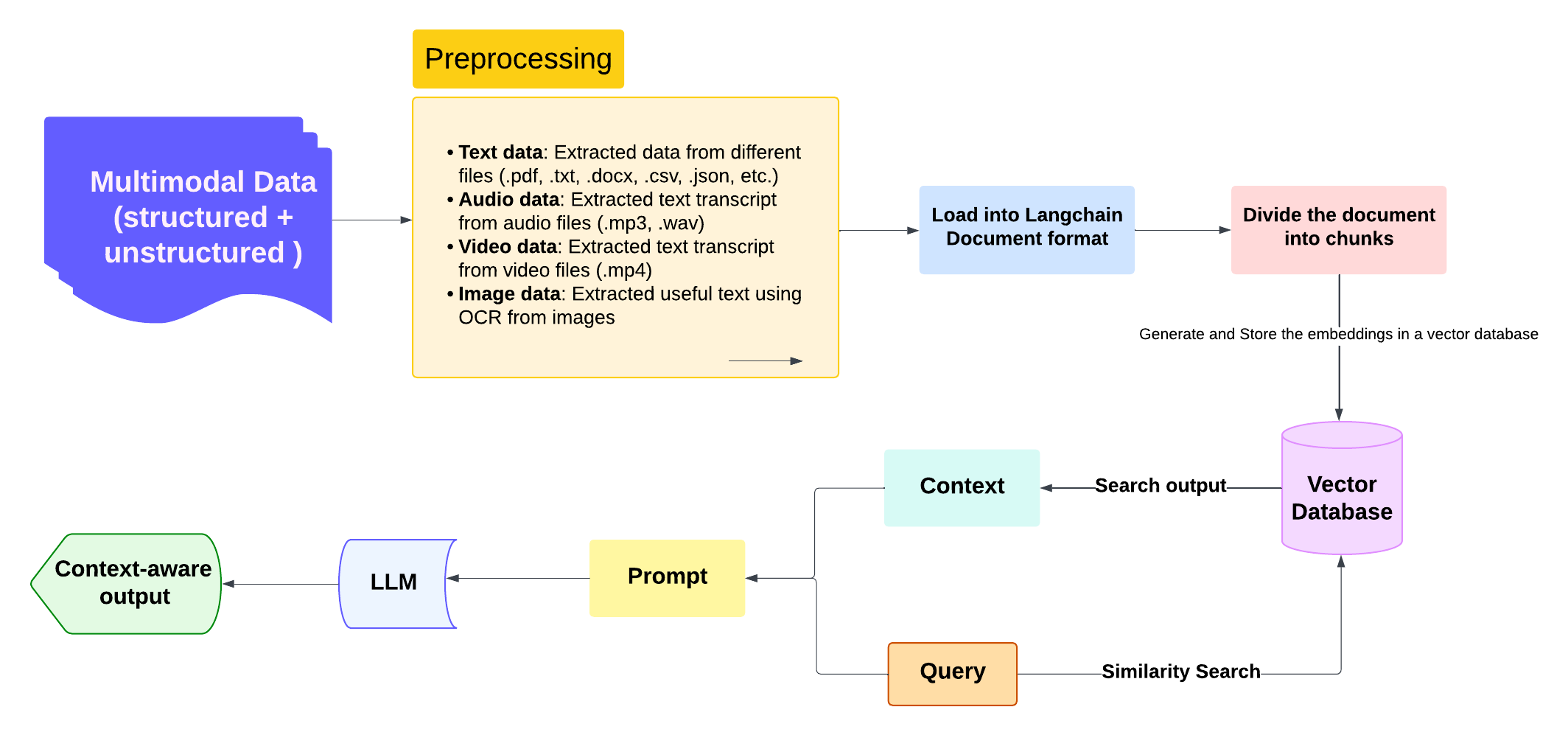
Dieses Projekt ist eine stromlose Anwendung zur Verarbeitung multimodaler Dokumente und Abfragen einer Milvus -Datenbank . Es nutzt hochmoderne Tools wie Langchain , Transformers , Easyocr und andere zum Verarbeiten, Speichern und Abfragen von Text, der aus verschiedenen Dateitypen extrahiert wurde.
Merkmale
Dateiverarbeitung hochladen :
- Unterstützt mehrere Dateitypen:
audio , video , image , text , csv , yaml , json , docx und pdf . - Extrahiert Textinhalte mit:
- ? Audio :
speech_recognition und pydub . - ? Video : benutzerdefinierte Extraktionslogik.
- ? ️ Bild :
EasyOCR . - ? Text/Protokolle/Dokumente : Langchain -Lader.
Milvus -Integration :
- ? Umpf speichert verarbeitete Dokumenteinbettungen für Ähnlichkeitsbasis.
- ? Verwendet
HuggingFaceEmbeddings , um Vektordarstellungen zu erzeugen.
? Abfrageschnittstelle :
- Query -Schnittstelle für natürliche Sprache.
- Implementiert eine RAG-Pipeline (Abruf-Augmented Generation) für AI-gesteuerte Antworten.
Installation
? Voraussetzungen
- Python 3.8+
-
pip oder conda -Paketmanager - CUDA-kompatible GPU (optional für eine schnellere Verarbeitung)
? Gabel und klonen Sie das Repository
Geben Sie das Repository aus : Navigieren Sie zu Rag-Architecture Github Repository und klicken Sie auf Gabel .
Klonen Sie das Forked Repository :
git clone https://github.com/ < your-username > /RAG-Architecture.git
cd RAG-Architecture
? Abhängigkeiten installieren
pip install -r requirements.txt
Verwendung
Starten Sie die Anwendung
Führen Sie die Streamlit -App aus:
Anwendungsmodi
? Dateien hochladen:
- Laden Sie eine Datei hoch, um ihre Inhalte in Milvus zu verarbeiten und zu speichern.
- Zeigt extrahierte Inhalte an und speichert Emetten in der Datenbank.
❓ Abfrage:
- Geben Sie eine Frage ein, um relevante Informationen aus der Milvus -Datenbank zu durchsuchen und abzurufen.
- Gibt Ai-generierte Antworten mit Langchains Rag-Pipeline zurück.
? Dateistruktur
# # ? **File Structure**
` ` ` bash
project/
│
├── app.py # Main Streamlit application
├── requirements.txt # ? Python dependencies
├── utils/ # Utility modules
│ ├── audio_utils.py # ? Audio file processing
│ ├── video_utils.py # ? Video file processing
│ ├── image_utils.py # ?️ Image file processing
│ ├── document_loaders.py # Document processing loaders
│ ├── milvus_client.py # ?️ Initializes Milvus database
│
├── milvus_database.db # ?️ Milvus database file (auto-created)
├── Dataset # Folder to store datasets
├── Images # ? Folder for storing images
? Schlüsselmodule
app.py
? Hauptanwendungslogik
- Vervollständigt Datei -Uploads, Dokumentenverarbeitung und Abfrage.
utils/
- ? Audio : Teilen Audio in Stücke und transkreibt Text.
- ? Video : Verarbeitet Videodateien zum Extrahieren und Analyse von Inhalten.
- ? ️ Bild : Verwendet Easyocr zum Extrahieren von Text.
- Protokolle/Dokumente : Verarbeitet CSV-, YAML-, JSON- und PDF -Dateien in strukturierte Langchain -Dokumente.
Beispiel Workflow
? Hochladen einer Datei
- Wählen Sie den Modus "Dateien hochladen" .
- Laden Sie eine Datei hoch (z. B.
example.pdf ). - Verarbeiten und speichern Sie die Datei in der Datenbank.
❓ Abfragen der Datenbank
- Wählen Sie "Abfrage" -Modus.
- Geben Sie eine natürliche Sprachfrage ein.
- Erhalten Sie eine kurze, faktenbasierte Antwort.
? Zukünftige Verbesserungen
- ? Fügen Sie fortgeschrittenere Abfragenfunktionen hinzu.
- Verbessern Sie die Unterstützung für zusätzliche Dateitypen und Einbettungen.
- ⚡ Verbesserung der Skalierbarkeit für größere Datensätze.
Lizenz Dieses Projekt ist im Rahmen der MIT -Lizenz lizenziert.
? Anerkennung
- Straffung für die interaktive Benutzeroberfläche.
- Langchain und Milvus für Dokumentenverarbeitung, Abruf und Vektor DB.
- ? Transformatoren für die Einbettung der Erzeugung.
- ? ️ Easyoc für Bildtextextraktion.
- ? Moviepy für die Videoverarbeitung.


