Voxnovel

? Aperçu
VoxNovel est un programme innovant qui tire parti des capacités de BookNLP pour analyser la littérature, attribuer des citations à des caractères spécifiques et générer un livre audiobière sur mesure où chaque personnage a une voix distincte grâce à des coquies. Cela offre non seulement une expérience audio immersive, mais donne également vie à chaque personnage avec une voix unique, ce qui rend l'expérience d'écoute beaucoup plus attrayante.
Modèles TTS inclus
Tous les modèles coqui tts- (Tacotron, Tacotron2, Glow-TTS, Speedy-Speech, Align-TTS, FastPitch, FastSpeech, FastSpeech2, SC-Glowtts, Capacitron, Overflow, Nural Hmm TTS, délicieux TTS, ⓧTTS, VITS,? YOTTS,? TORTOISE,? Bark) et Styletts2.
?
- Ils leur permettent également de parler ces langues, mais l'attribution de la citation ne s'identifiera pas correctement pour tout ce qui n'est pas l'anglais. Anglais (en), espagnol (ES), français (FR), allemand (DE), italien (IT), portugais (PT), polonais (PL), turc (TR), Russe (RU), néerlandais (NL), tchèque (CS), arabe (AR), chinois (ZH-CN), japonais (JA), Hungarien (Hu), coréen (KO) Sorties en tant que M4B avec toutes les métadonnées et chapitres du livre, exemple de fichier de sortie dans une application de lecteur audio
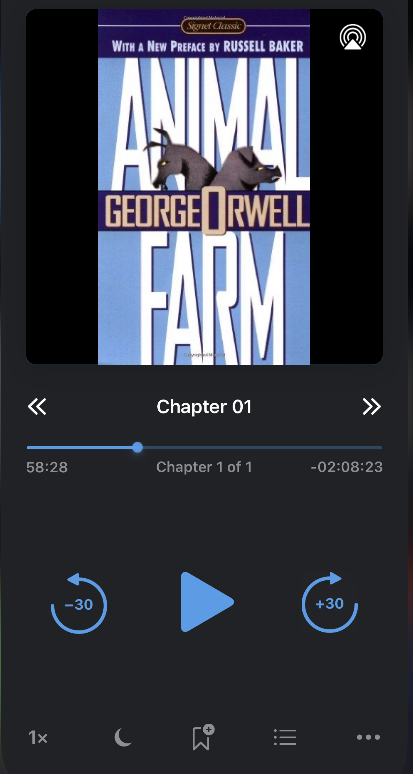
(Ainsi qu'un dossier de fichiers MP4 Chatper individuels avec une image de livre électronique intégré à celle si vous le souhaitez)
? Démos
Demos XTTS V2 de haute qualité
Gardiens_of_ga.hoole_10._lasky._kathryn _-_ Coming_of_hoole_chapter_4.mp4
?? Plus de fichiers audio de démonstration :)
Démos de tortue de haute qualité
272463996-C4F8DFDF-C5BD-4771-AB1A-6131C22A67B2.MP4
Démos audio Balacoon super rapides
271878548-53B694A9-5DDD-4174-82BC-07AFF22D2330.MP4
271876316-530E8781-C77C-4424-89CD-A02DF363B0BF.MP4
** Tests de grande qualité avec des modèles ajustés fins **
Audio_5811.mp4
Vous pouvez affiner vos propres modèles XTTS avec environ plus de 6 minutes d'audio gratuitement avec ce colab https://colab.research.google.com/drive/1gii4_x724m8q2w-zz-jxo7cwtv7rfah-
Edit: ce colab ne fonctionne plus: utilisez ma version qui fournit un correctif: https://colab.research.google.com/drive/1sqqqzupo2pdjgggkrbm60su6sbfyo3su?usp=sharing
? VoxNovel sans tête Google Colab
Explorez et exécutez la version interactive du projet VoxNovel sans tête directement sur Google Colab! Commencez ici.
Gui
GUI Part 1 (Processeur BooknLP) Infos / fonctionnalités
- Bouton "Process Fichier": cliquez sur et il vous demandera de sélectionner un fichier eBook. 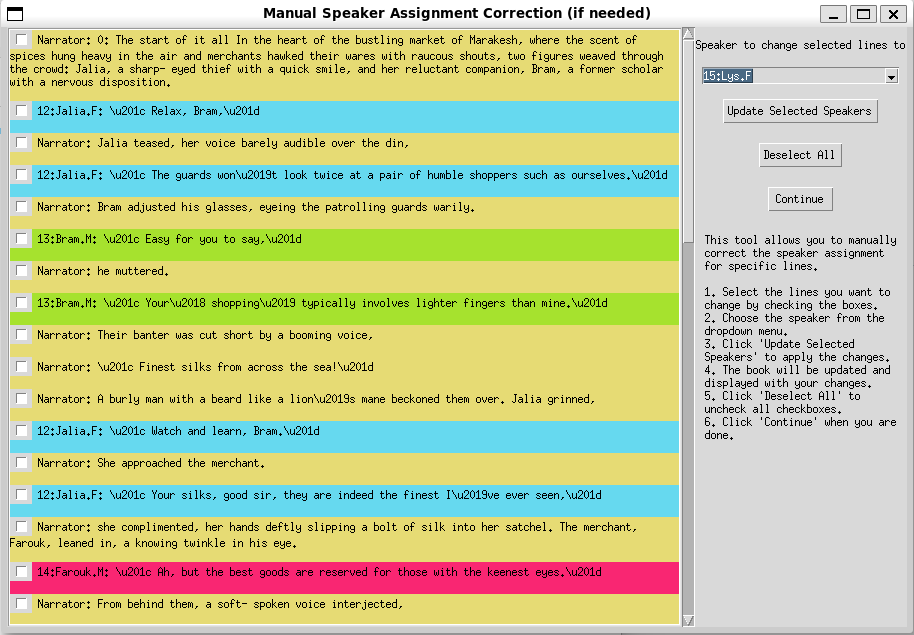
Outil de correction de l'attribution de l'enceinte manuelle (GUI 1.5)
Cette interface graphique concerne la correction manuelle des affectations de conférenciers si les devis sont mal attribués par booknlp. Il lit le fichier book.csv contenant les livres extraits de devis et des informations de haut-parleur, et vous permet d'inspecter visuellement et de modifier les affectations de haut-parleurs si nécessaire avant d'être transmise à l'étape TTS suivante.
Caractéristiques clés:
- Affichage de texte défilable: permet aux utilisateurs de visualiser le texte du livre avec des affectations de haut-parleurs codées en couleur.
- Sélection de haut-parleur: les utilisateurs peuvent sélectionner un nouveau haut-parleur dans un menu déroulant pour réaffecter des lignes spécifiques.
- Citations cochables: les lignes du livre sont affichées avec des cases à cocher, permettant la sélection de plusieurs lignes pour la réaffectation du haut-parleur.
- Codage de couleur du haut-parleur: chaque haut-parleur se voit attribuer une couleur unique pour une identification facile.
- Boutons pour l'action:
- Mettez à jour les conférenciers sélectionnés: appliquez le haut-parleur sélectionné à toutes les lignes vérifiées.
- Désélectionnez tout: décochez toutes les lignes sélectionnées.
- Continuez: Enregistrez les modifications et sortez de l'outil.
Comment utiliser:
- Sélectionnez les lignes: cochez les cases à côté des lignes que vous souhaitez modifier.
- Choisissez le haut-parleur: sélectionnez le haut-parleur souhaité dans le menu déroulant.
- Appliquer les modifications: cliquez sur "Mettre à jour les conférenciers sélectionnés" pour appliquer les modifications.
- Revue: le texte mettra à jour pour refléter les modifications.
- Désélectionner: cliquez sur "Deelect All" pour effacer vos sélections.
- Terminer: une fois satisfait des corrections, cliquez sur "Continuer" pour enregistrer et quitter.
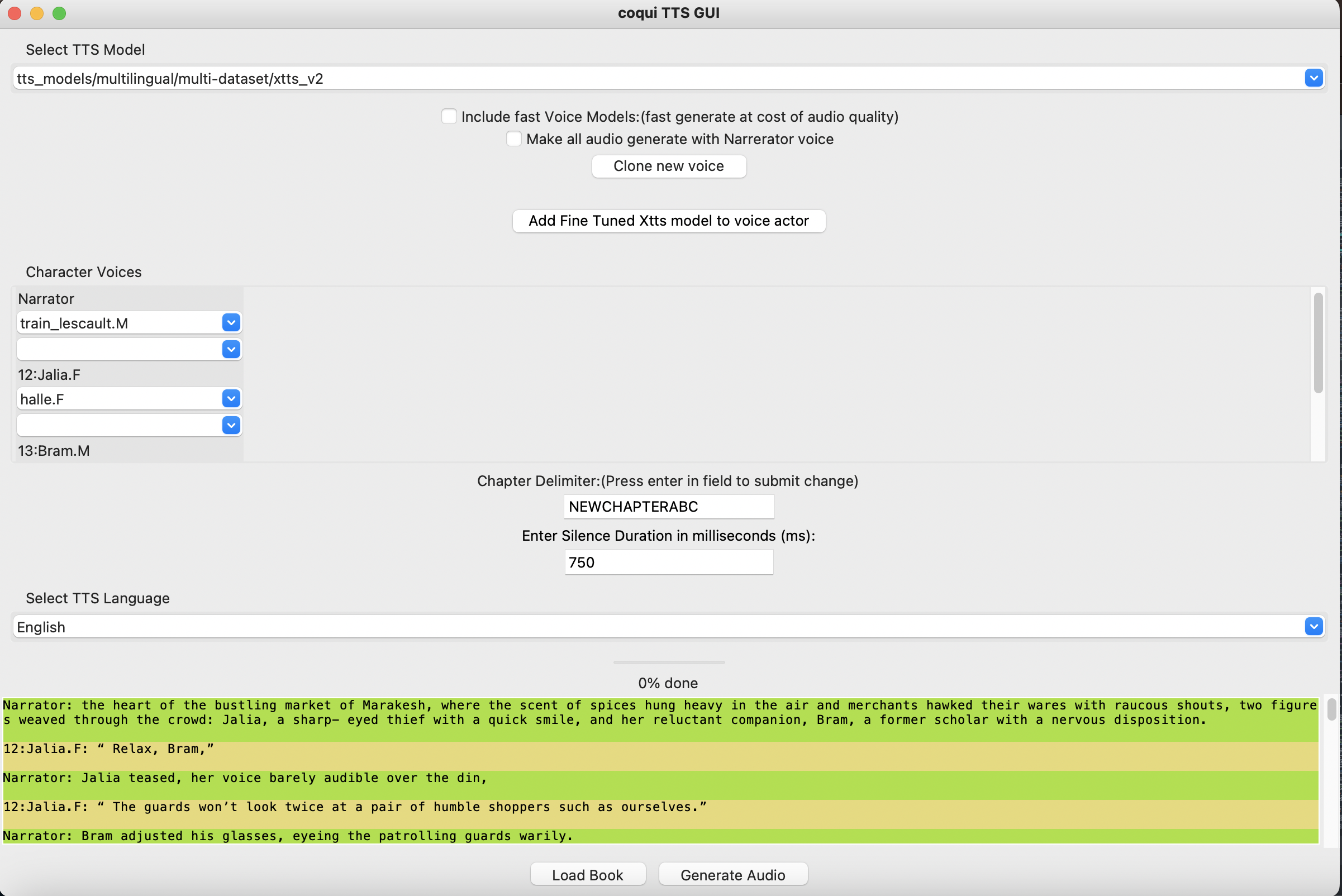
Gui partie 2 (Coqui TTS GUI) Infos / fonctionnalités
- Sélectionnez la liste déroulante du modèle TTS: cela sélectionne le modèle TTS qui sera utilisé pour le clonage vocal.
- Incluez la case à cocher Fast Voice Modèles: (Générer rapidement au coût de la qualité de l'audio) Cliquez sur ceci pour pouvoir voir tous les autres modèles et voix singulières prises en charge par les coquies.
- Il mettra à jour la liste déroulante "Select TTS modèle" pour les modèles de clonage vocale à inclure également (liste des valeurs à ajouter).
- Il mettra à jour la liste déroulante pour les voix à sélectionner pour que chaque personnage inclue également (liste des valeurs à ajouter).
- Faites que tout l'audio génère avec le narrateur à cocher la voix: cela fera générer audio chaque personnage avec la voix que vous avez sélectionnée pour le narrateur lorsque vous cliquez sur le bouton "Générer l'audio".
- Clone NOUVEAU BOUTON VOCTY: Cliquez sur ceci pour ajouter une nouvelle voix que vous pouvez clone (assurez-vous d'avoir un fichier audio de référence à portée de main).
- Ajoutez un modèle XTTS à réglage fin au bouton d'acteur vocal: Si vous avez un dossier contenant tous les paramètres d'un modèle XTTS affiné d'une voix spécifique, vous pouvez cliquer sur ceci pour créer ce clone de l'acteur vocal avec ce modèle XTTS affiné, pour fournir de bien meilleurs résultats de clonage vocal.
- Les voites de personnages déroutes: ce sont les listes déroulantes pour sélectionner l'acteur vocal (et l'accent de chaque personnage si vous utilisez XTTS).
- (1): Les acteurs vocaux disponibles pour sélectionner pour ce personnage. (La valeur par défaut est sélectionnée audio en fonction du genre de caractère inféré: "f, m, autre").
- Lorsque vous sélectionnez une voix, il jouera l'échantillon audio de cette voix, s'il s'agit d'une voix de modèle vocale rapide et qu'un audio de réfrension n'existe pas, il en générera un pour jouer.
- (2): Les accents disponibles pour sélectionner pour ce personnage. (Facultatif, la valeur par défaut est l'anglais).
- Chapitre Delimiter Field: modifiera le délimiteur de chapitre par défaut (la chaîne utilisée pour identifier les chapitres).
- Durée du silence en millisecondes (MS) Champ: Cela modifiera la quantité de millisecondes entre chaque morceau combiné d'audio.
- Sélectionnez la liste déroulante du langage TTS: cela vous permettra de sélectionner l'accent par défaut utilisé pour chaque caractère qui n'a pas été sélectionné manuellement.
- Barre de chargement: donnera une durée environ. (Estimez, vous ne verrez probablement pas de prédictions précises tant qu'elles sont en cours d'exécution pendant 5 min).
- Bloque d'aperçu du livre annoté: Cela montrera l'intégralité du livre avec les lignes de chaque personnage codées.
- Vous pouvez cliquer sur une ligne pendant que le livre audio est généré pour entendre à quoi ressemble cette ligne générée. Mais seulement si la ligne a déjà été générée audio pour cela; Sinon, cela ne jouera rien.
- Bouton de chargement: cliquez sur ceci recharger la vue du livre annotée à code couleur, il randomisera les couleurs sélectionnées pour les lignes de chaque personnage.
- Générer le bouton audio: commencera à générer le livre audio complet.
- Sélectionnez le bouton des voix aléatoires (ne sera visible que si la case à cocher "Inclure Fast Voice" est cochée): sélectionnera une voix rapide de modèle rapide inférieure à l'auto-genre pour chaque personnage à l'exception de la voix du narrateur.
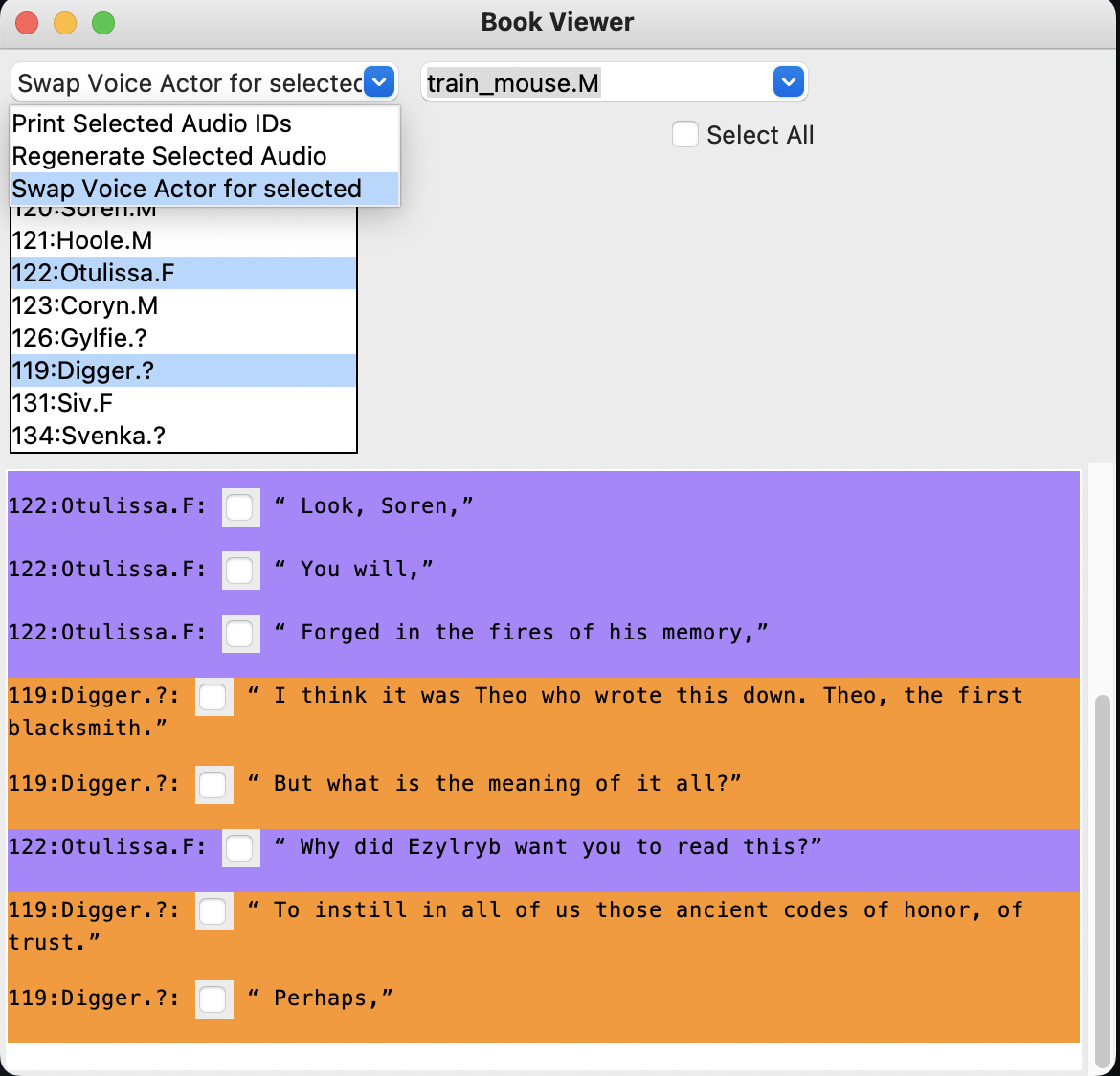
GUI PARTIE 3 (Visionneuse du livre) Infos / fonctionnalités
-Il est difficile d'expliquer que c'est plus un terrain de jeu si vous jouez avec lui, vous devriez obtenir comment cela fonctionne. Mais il peut être utilisé pour affiner le livre audio -close hors de la fenêtre lorsque vous l'avez terminé. ? Installation de configuration
? VoxNovel sans tête Google Colab
Explorez et exécutez la version interactive du projet VoxNovel sans tête directement sur Google Colab! Commencez ici.
? Docker (son ne fonctionne pas encore dans l'interface graphique)
? Docker sans tête
Docker sans tête M1? Mac
cd ~
git clone https://github.com/DrewThomasson/VoxNovel.git
sudo docker run -v "$HOME/VoxNovel:/VoxNovel/" -it athomasson2/voxnovel:headless_m1_v2
Docker sans tête? Linux / Intel? Mac
Pour Docker sans tête sur uniquement le processeur
cd ~
git clone https://github.com/DrewThomasson/VoxNovel.git
sudo docker run -v "$HOME/VoxNovel:/VoxNovel/" -it athomasson2/voxnovel:latest_headless
Pour Docker sans tête avec un GPU accélére si vous avez un GPU NVIDA
cd ~
git clone https://github.com/DrewThomasson/VoxNovel.git
sudo docker run --gpus all -v "$HOME/VoxNovel:/VoxNovel/" -it athomasson2/voxnovel:latest_headless
Windows Docker sans tête
Installation et configuration sur Windows (PowerShell)
Suivez ces étapes pour configurer le projet VoxNovel sur un système Windows à l'aide de PowerShell:
Accédez à votre répertoire de profil utilisateur:
Clone le référentiel VoxNovel de GitHub:
git clone https: // github.com / DrewThomasson / VoxNovel.git
Exécution de VoxNovel dans Docker
Pour un fonctionnement sans tête sur le processeur
Pour exécuter l'application VoxNovel dans un conteneur Docker sur votre CPU:
docker run - v " ${ env: USERPROFILE} /VoxNovel/:/VoxNovel/ " - it athomasson2 / voxnovel:latest_headlessPour une opération sans tête avec NVIDIA GPU accélérer
Si vous avez un GPU NVIDIA et que vous souhaitez accélérer le traitement, utilisez la commande suivante:
docker run -- gpus all - v " ${ env: USERPROFILE} /VoxNovel/:/VoxNovel/ " - it athomasson2 / voxnovel:latest_headless ? Gui Docker (le son ne fonctionne pas encore dans GUI)
? Docker Linux
1. `CD ~`-
git clone https://github.com/DrewThomasson/VoxNovel.git -
sudo docker run --gpus all -e DISPLAY=$DISPLAY -v /tmp/.X11-unix:/tmp/.X11-unix -v /dev/snd:/dev/snd --device /dev/snd -v "$HOME/VoxNovel:/VoxNovel/" -it athomasson2/voxnovel:latest
? Mac docker
Configuration des applications GUI avec Docker sur macOS
Ce guide fournit des instructions sur la façon d'exécuter un conteneur Docker avec une interface utilisateur graphique sur MacOS à l'aide de XQuartz pour le transfert X11 et le montage de volume.
Installer xquartz
- Téléchargez et installez XQuartz sur le site Web Xquartz.
- Open Xquartz.
- Allez à
XQuartz -> Preferences . - Dans l'onglet
Security , activez les connexions de clients de réseau . - Redémarrez Xquartz pour appliquer ces paramètres.
Configurer et exécuter le conteneur Docker
Autoriser Docker à se connecter à Xquartz
Ouvrez un terminal et exécutez la commande suivante pour autoriser les connexions de votre machine locale à xquartz:
xhost + $(ifconfig en0 | grep inet | awk '$1=="inet" {print $2}')
Démarrez le conteneur Docker
Exécutez la commande suivante pour démarrer votre conteneur Docker. Cette commande configure l'interface graphique à afficher sur votre hôte et monte les répertoires nécessaires:
cd ~
git clone https://github.com/DrewThomasson/VoxNovel.git
docker run -e DISPLAY=$(ifconfig en0 | grep inet | awk '$1=="inet" {print $2}'):0
-v /tmp/.X11-unix:/tmp/.X11-unix
-v "/Users/$(whoami)/VoxNovel:/VoxNovel"
athomasson2/voxnovel:latest
Notes
- Configuration XQuartz : assurez-vous que Xquartz est configuré pour permettre aux clients du réseau avant d'essayer de se connecter.
- Existence du répertoire : vérifiez que le répertoire
/Users/$(whoami)/VoxNovel existe sur votre Mac. Sinon, créez-le ou ajustez le chemin de montage du volume dans la commande docker selon les besoins. - Pare-feu et sécurité : si vous confrontez les problèmes de connectivité, vérifiez les paramètres du pare-feu et les préférences de sécurité qui peuvent bloquer les connexions.
? Windows Docker
Installez VCXSRV:
- Installez d'abord VCXSRV et configurez-le pour autoriser les connexions.
Comment configurer VCXSRV
Après avoir installé VCXSRV, il lance généralement automatiquement. Vous pouvez confirmer qu'il s'exécute en vérifiant son icône dans le plateau système, généralement situé près de l'horloge dans la barre des tâches. Il peut également démarrer automatiquement lorsque vous vous connectez à votre système.
Pour vous assurer qu'il est configuré pour permettre les connexions à partir de conteneurs Docker, suivez ces étapes:
- Cliquez avec le bouton droit sur l'icône VCXSRV dans le plateau système.
- Sélectionnez "Xlaunch" pour ouvrir l'assistant de configuration.
- Dans l'assistant de configuration, sélectionnez "plusieurs fenêtres" et passez à l'étape suivante.
- Choisissez vos paramètres préférés pour le numéro d'affichage et l'écran.
- Dans la fenêtre "Paramètres supplémentaires", assurez-vous de cocher la case intitulée "Désactiver le contrôle d'accès" pour permettre les connexions à partir de conteneurs Docker.
- Terminez la configuration en cliquant sur "Finition", puis "Enregistrer la configuration" lorsque vous y êtes invité.
Avec ces paramètres, VCXSRV doit être exécuté et configuré pour permettre les connexions à partir de conteneurs Docker. Vous pouvez désormais procéder à l'exécution de vos commandes Docker nécessitant un support d'interface graphique.
Passez à votre répertoire d'origine:
Clone le référentiel:
git clone https://github.com/DrewThomasson/VoxNovel.git
Exécutez le conteneur Docker:
docker run -e DISPLAY=host.docker.internal:0 -v " /Users/ $( whoami ) /VoxNovel:/VoxNovel/ " -it athomasson2/voxnovel:latest
? Linux
Installation d'Ubuntu de commande unique
(N'utilisez pas si vous avez déjà installé MiniConda.)
Pour installer VoxNovel sur Ubuntu, vous pouvez utiliser la commande unique suivante:
yes | wget -O - https://raw.githubusercontent.com/DrewThomasson/VoxNovel/main/shell_install_scripts/Ubuntu-install.sh | bash
Raccourci de bureau
-Ce script d'installation unique ci-dessus devrait également créer un raccourci pour l'application.
Option de lancement manuel
Ou vous pouvez lancer manuellement l'application dans le terminal avec la commande suivante:
cd ~ /VoxNovel && conda activate VoxNovel && python gui_run.py
ou installation manuelle:
-
sudo apt-get install calibre -
sudo apt-get install ffmpeg -
conda create --name VoxNovel python=3.10 -
conda activate VoxNovel -
git clone https://github.com/DrewThomasson/VoxNovel.git -
cd VoxNovel -
pip install bs4 -
pip install styletts2 -
pip install tts==0.21.3 -
pip install booknlp==1.0.7.1 -
pip install -r Ubuntu_requirements.txt -
python -m spacy download en_core_web_sm
? Pour les langues non latines, support TTS (facultatif)
Installez MECAB pour (support TTS des langues non latins) (facultatif):
- Ubuntu:
sudo apt-get install -y mecab libmecab-dev mecab-ipadic-utf8
(Pour les langues non latines Prise en charge TTS) (facultative)
python -m unidic download
pip install mecab mecab-python3 unidic
? Pont à vapeur) (x86_64 Arch Linux)
Pour installer VoxNovel sur votre pont de vapeur, ouvrez un terminal et exécutez la commande unique suivante:
bash <( curl -s https://raw.githubusercontent.com/DrewThomasson/VoxNovel/main/shell_install_scripts/Steam-Deck_VoxNovel-Install.sh )
- Maintenant, vous devriez avoir un raccourci de bureau pour VoxNovel à la fin de ce script!
? Intel Mac
Installer sur Intel Mac:
Téléchargez l'installateur Intel VoxNovel
Ou exécutez la commande suivante dans votre terminal:
bash <( curl -s https://raw.githubusercontent.com/DrewThomasson/VoxNovel/main/shell_install_scripts/Intel_Mac_Install_VoxNovel.sh )
Une fois terminé, vous devriez avoir un raccourci de bureau pour VoxNovel.
? Désinstaller sur Intel Mac:
Pour désinstaller, exécutez la commande suivante dans votre terminal:
bash <( curl -s https://raw.githubusercontent.com/DrewThomasson/VoxNovel/main/shell_install_scripts/uninstall_VoxNovel_Mac.sh )
(Désactif n'utilise pas) Intel Mac Manual-Install
Exécutez dans cet ordre:-
brew install calibre -
brew install ffmpeg -
conda create --name VoxNovel python=3.10 -
conda activate VoxNovel -
git clone https://github.com/DrewThomasson/VoxNovel.git -
cd VoxNovel -
pip install styletts2 -
pip install tts==0.21.3 -
pip install booknlp==1.0.7.1 9. pip install -r MAC-requirements.txt -
pip install spacy 11. python -m spacy download en_core_web_sm
? Pour les langues non latines, support TTS (facultatif)
Installez MECAB pour (support TTS des langues non latins) (facultatif):
- macOS:
brew install mecab , brew install mecab-ipadic
(Pour les langues non latines Prise en charge TTS) (facultative)
python -m unidic download
pip install mecab mecab-python3 unidic
? Apple Silicon Mac (testé sur 2020 M1 Pro 8 Go RAM)
Installer sur le silicium Apple Mac:
Télécharger le programme d'installation d'Apple Silicon VoxNovel
Ou exécutez la commande suivante dans votre terminal:
bash <( curl -s https://raw.githubusercontent.com/DrewThomasson/VoxNovel/main/shell_install_scripts/Apple_silicone_VoxNovel_install.sh )
Une fois terminé, vous devriez avoir un raccourci de bureau pour VoxNovel.
? Désinstaller sur le silicium Apple Mac:
Pour désinstaller, exécutez la commande suivante dans votre terminal:
bash <( curl -s https://raw.githubusercontent.com/DrewThomasson/VoxNovel/main/shell_install_scripts/uninstall_VoxNovel_Mac.sh )
(Désactif n'utilise pas) Installation manuelle de silicium Apple Silicon
Exécutez dans cet ordre:
-
brew install calibre (vous devrez peut-être également l'installer manuellement à partir de leur site si cela ne fonctionne pas) -
brew install ffmpeg -
conda create --name VoxNovel python=3.10 -
conda activate VoxNovel -
git clone https://github.com/DrewThomasson/VoxNovel.git -
cd VoxNovel -
pip install tensorflow-macos (également en option pip install tensorflow-metal mais jusqu'à présent, je n'ai pas encore obtenu GPU Speetup -
pip install styletts2 -
pip install tts==0.21.3 -
pip install --no-dependencies booknlp==1.0.7.1 -
pip install transformers==4.30.0 -
pip install tensorflow -
pip install -r MAC-requirements.txt -
pip install ebooklib bs4 epub2txt pygame moviepy spacy -
python -m spacy download en_core_web_sm
? Pour les langues non latines, support TTS (facultatif)
Installez MECAB pour (support TTS des langues non latins) (facultatif):
- MacOS:
brew install mecab , brew install mecab-ipadic (pour les langues non latines TTS Prise en charge) (facultatif)
python -m unidic download
pip install mecab mecab-python3 unidic
? Windows 11
En raison des problèmes de Windows BookNLP, tout cela sera exécuté dans WSL (ne vous inquiétez pas, c'est toujours facile).
? Regardez la vidéo d'installation ici
Dans votre PowerShell, collez:
Pour installer WSL. (Vous pourriez être invité par votre système à activer la virtualisation dans votre BIOS s'il est disponible, car il est nécessaire d'exécuter WSL sous Windows.)
Après avoir défini votre nom d'utilisateur et votre mot de passe, ouvrez WSL et collez cette commande pour une seule installation de commande:
yes | wget -O - https://raw.githubusercontent.com/DrewThomasson/VoxNovel/main/shell_install_scripts/Ubuntu-install.sh | bash
(Facultatif uniquement pour les cartes graphiques NVIDA n'exécutez pas cette commande si vous n'avez pas de carte graphique NVIDIA) Installez la boîte à outils NVIDIA CUDA (requise pour l'accélération du GPU NVIDIA):
sudo apt install nvidia-cuda-toolkit
Assurez-vous que vous êtes dans l'environnement de VoxNovel Conda: (si 'conda: commande non trouvé' ie- conda n'est pas considéré comme une commande, essayez de fermer la fenêtre PowerShell actuelle et de relancer le WSL Env avec [wsl -d ubuntu]
Accédez au dossier VoxNovel (sinon déjà là):
Maintenant, exécutez l'un des deux programmes ci-dessous
Pour exécuter le programme
Ou pour courir sans tête
python headless_voxnovel.py
Accéder aux fichiers WSL Ubuntu à partir de Windows
Vous pouvez accéder à vos fichiers WSL Ubuntu directement dans Windows File Explorer en entrant le chemin suivant dans la barre d'adresse:
Les fichiers de livres audio de sortie seront situés sous VoxNoveloutput_audiobooks dans le WSL Env
Pour créer un raccourci de bureau VoxNovel Windows
Exécutez cette commande dans PowerShell
Invoke-Expression (Invoke-WebRequest -Uri " https://raw.githubusercontent.com/DrewThomasson/VoxNovel/main/shell_install_scripts/Windows-install-scripts/create_desktop_shortcut.ps1 " ).Content
? ️ Uninstallation:
Pour tout supprimer, exécutez la commande suivante dans PowerShell:
Cela supprimera complètement l'environnement Ubuntu où l'application est stockée. ?
Dépannage WSL
Si vous avez des problèmes avec l'environnement WSL:
Liste tous les environnements WSL:
Supprimez un environnement WSL spécifique (par exemple, Ubuntu):
wsl --unregister < distro_name >
Réinstaller WSL:
Pour lancer WSL chaque fois que vous devez exécuter ce programme, vous pouvez utiliser la barre de recherche dans Windows pour trouver et lancer "WSL" ou exécuter:
? Pour les langues non latines, support TTS (facultatif)
Installez MECAB pour (support TTS des langues non latins) (facultatif):
-
sudo apt-get install -y mecab libmecab-dev mecab-ipadic-utf8
(Pour les langues non latines Prise en charge TTS) (facultative)
python -m unidic download
pip install mecab mecab-python3 unidic
Pour exécuter le programme
Ou pour courir sans tête
python headless_voxnovel.py
Courir avec un VRAM bas (4 Go)
Modifications
- Il s'avère qu'une fois que vous avez réglé l'appareil, il reste comme ça pour le programme complet.
- Donc, j'ai divisé le programme en deux programmes Python: un CPU et un GPU. J'ai testé cela sur mon (4 Go VRAM GPU) et cette solution fonctionne. Au moins de mon côté, j'espère vraiment que cela fonctionne de votre côté.
Pour exécuter le correctif que j'ai fait sur mesure pour une situation GPU VRAM faible:
Pour exécuter les scripts fournis sur votre système, suivez ces étapes dans l'ordre:
Traitement de livres (CPU uniquement):
- Script: 1cpu_book_processing.py
- Ce script gère la tâche de traiter uniquement le livre à l'aide de booknlp, le forçant spécifiquement à s'exécuter sur le CPU.
- Exécutez avec
python 1CPU_Book_processing.py
Génération audio (GPU uniquement):
- Script: 2gpu_audio_generation.py
- Ce script est dédié à la génération d'audio uniquement avec le GPU et doit être exécuté après avoir terminé le traitement du livre avec
1CPU_Book_processing.py . - Exécutez avec
python 2GPU_Audio_generation.py
Résultats de performance
Lors de l'exécution d'un mini test avec un fichier EPUB utilisant la configuration ci-dessus, les mesures de performance suivantes ont été observées:
Résultats de performance
Test sur Terminé avec le mini fichier EPUB situé dans l'exemple_working_files.zip
| Tâche | Configuration | Temps (secondes) |
|---|
| Traitement des livres | GPU uniquement (GeForce GTX 980), 4 Go VRAM, 32 Go de RAM, Intel i7-8700K | 2.922 |
| Génération audio | GPU uniquement (GeForce GTX 980), 4 Go VRAM, 32 Go de RAM, Intel i7-8700K | 128.48 |
| Traitement des livres | CPU uniquement, 32 Go de RAM, Intel i7-8700K | 4.964 |
| Génération audio | CPU uniquement, 32 Go de RAM, Intel i7-8700K | 391.4227 |
Pour exécuter le programme automobile
Cela signifie que tout ce que vous faites est de sélectionner le livre et que toutes les voix seront attribuées et générées pour vous. python auto_noGui_run.py
Fichiers de livres audio générés par l'accès
Vous pouvez accéder à vos fichiers de livres audio générés dans le dossier VoxNovel à l'emplacement
VoxNovel/output_audiobooks
Types de fichiers d'ebook pris en charge:
.epub, .pdf, .mobi, .txt, .html, .rtf, .chm, .lit, .pdb, .fb2, .odt, .cbr, .cbz, .prc, .lrf, .pml, .snb, .cbc, .rb et .tcr,.
- (Les meilleurs résultats proviennent de l'utilisation de EPUB ou MOBI pour la détection de chapitre automatique)
Dossiers
Dossiers utilisés par le programme
/ Final_combined_output_audio: c'est là que tous vos fichiers audio de chapitre seront mis dans l'ordre du chapitre Num
/ output_audiobooks: c'est là que tous vos fichiers de livres audio M4B seront stockés
/ Working_files: détient tous les fichiers de travail utilisés par le programme pendant l'activité.
- / Working_files / temp_ebook: détient tous les fichiers de chapitre TXT extraits individuels de l'ebook.
/ Tortoise: détient tous les exemples de fichiers vocaux
Fonctions GUI
GUI PARTIE 1 (Processeur BookNLP)
- Bouton "Process Fichier": cliquez sur et il vous demandera de sélectionner un fichier eBook. GUI PARTIE 2 (Coqui TTS GUI)
- Sélectionnez la liste déroulante du modèle TTS: cela sélectionne le modèle TTS qui sera utilisé pour le clonage vocal.
- Incluez la case à cocher Fast Voice Modèles: (Générer rapidement au coût de la qualité de l'audio) Cliquez sur ceci pour pouvoir voir tous les autres modèles et voix singulières prises en charge par les coquies.
- Il mettra à jour la liste déroulante "Select TTS modèle" pour les modèles de clonage vocale à inclure également (liste des valeurs à ajouter).
- Il mettra à jour la liste déroulante pour les voix à sélectionner pour que chaque personnage inclue également (liste des valeurs à ajouter).
- Faites que tout l'audio génère avec le narrateur à cocher la voix: cela fera générer audio chaque personnage avec la voix que vous avez sélectionnée pour le narrateur lorsque vous cliquez sur le bouton "Générer l'audio".
- Clone NOUVEAU BOUTON VOCTY: Cliquez sur ceci pour ajouter une nouvelle voix que vous pouvez clone (assurez-vous d'avoir un fichier audio de référence à portée de main).
- Ajoutez un modèle XTTS à réglage fin au bouton d'acteur vocal: Si vous avez un dossier contenant tous les paramètres d'un modèle XTTS affiné d'une voix spécifique, vous pouvez cliquer sur ceci pour créer ce clone de l'acteur vocal avec ce modèle XTTS affiné, pour fournir de bien meilleurs résultats de clonage vocal.
- Les voites de personnages déroutes: ce sont les listes déroulantes pour sélectionner l'acteur vocal (et l'accent de chaque personnage si vous utilisez XTTS).
- (1): Les acteurs vocaux disponibles pour sélectionner pour ce personnage. (La valeur par défaut est sélectionnée audio en fonction du genre de caractère inféré: "f, m, autre").
- Lorsque vous sélectionnez une voix, il jouera l'échantillon audio de cette voix, s'il s'agit d'une voix de modèle vocale rapide et qu'un audio de réfrension n'existe pas, il en générera un pour jouer.
- (2): Les accents disponibles pour sélectionner pour ce personnage. (Facultatif, la valeur par défaut est l'anglais).
- Chapitre Delimiter Field: modifiera le délimiteur de chapitre par défaut (la chaîne utilisée pour identifier les chapitres).
- Durée du silence en millisecondes (MS) Champ: Cela modifiera la quantité de millisecondes entre chaque morceau combiné d'audio.
- Sélectionnez la liste déroulante du langage TTS: cela vous permettra de sélectionner l'accent par défaut utilisé pour chaque caractère qui n'a pas été sélectionné manuellement.
- Barre de chargement: donnera une durée environ. (Estimez, vous ne verrez probablement pas de prédictions précises tant qu'elles sont en cours d'exécution pendant 5 min).
- Bloque d'aperçu du livre annoté: Cela montrera l'intégralité du livre avec les lignes de chaque personnage codées.
- Vous pouvez cliquer sur une ligne pendant que le livre audio est généré pour entendre à quoi ressemble cette ligne générée. Mais seulement si la ligne a déjà été générée audio pour cela; Sinon, cela ne jouera rien.
- Bouton de chargement: cliquez sur ceci recharger la vue du livre annotée à code couleur, il randomisera les couleurs sélectionnées pour les lignes de chaque personnage.
- Générer le bouton audio: commencera à générer le livre audio complet.
- Sélectionnez le bouton des voix aléatoires (ne sera visible que si la case à cocher "Inclure Fast Voice" est cochée): sélectionnera une voix rapide de modèle rapide inférieure à l'auto-genre pour chaque personnage à l'exception de la voix du narrateur.
GUI PARTIE 3 (Visionneuse du livre)
-Il est difficile d'expliquer que c'est plus un terrain de jeu si vous jouez avec lui, vous devriez obtenir comment cela fonctionne. Mais il peut être utilisé pour affiner le livre audio -close hors de la fenêtre lorsque vous l'avez terminé. ? Caractéristiques
Caractéristiques planifiées entrantes
Un merci spécial à:
- @ Sidharthrajaram (pour son installation de styletts2 pip qu'il a créé, je ne pouvais pas d'ajouter Styletts2 sans lui. :)) (https://github.com/sidharthrajaram/styletts2)


