Stream responses
1.0.0
Le code consiste à démontrer l'utilisation du streaming avec l'API GPT-4, l'API ChatGPT et les modèles InstructGPT (GPT-3.5.) Et Streamlit-App.
L'approche utilise uniquement des bibliothèques OpenAI et Time et réimprime les flux à l'aide de l'impression (end = '', flush = true):
!p ip install - - upgrade openai
import openai
import time
openai . api_key = user_secrets . get_secret ( "OPENAI_API_KEY" )
startime = time . time ()Avertissement: L'inconvénient du streaming dans l'utilisation de la production est le contrôle de la politique d'utilisation appropriée: https://beta.openai.com/docs/usage-guidelines, qui devrait être examinée à l'avance pour chaque application, donc je suggère de jeter un coup d'œil à cette politique avant de décider d'utiliser le streaming.
Exécutez la première partie de fichiers.
### STREAM GPT-4 API RESPONSES
delay_time = 0.01 # faster
max_response_length = 8000
answer = ''
# ASK QUESTION
prompt = input ( "Ask a question: " )
start_time = time . time ()
response = openai . ChatCompletion . create (
# GPT-4 API REQQUEST
model = 'gpt-4' ,
messages = [
{ 'role' : 'user' , 'content' : f' { prompt } ' }
],
max_tokens = max_response_length ,
temperature = 0 ,
stream = True , # this time, we set stream=True
)
for event in response :
# STREAM THE ANSWER
print ( answer , end = '' , flush = True ) # Print the response
# RETRIEVE THE TEXT FROM THE RESPONSE
event_time = time . time () - start_time # CALCULATE TIME DELAY BY THE EVENT
event_text = event [ 'choices' ][ 0 ][ 'delta' ] # EVENT DELTA RESPONSE
answer = event_text . get ( 'content' , '' ) # RETRIEVE CONTENT
time . sleep ( delay_time )Après avoir inséré l'entrée de l'utilisateur et appuyé sur Entrée, vous devriez voir la sortie imprimée:

Exécutez le fichier Streams.ipnyb deuxième partie. Ajoutez une entrée utilisateur et vous devriez voir similaire à ci-dessous:
### STREAM CHATGPT API RESPONSES
delay_time = 0.01 # faster
max_response_length = 200
answer = ''
# ASK QUESTION
prompt = input ( "Ask a question: " )
start_time = time . time ()
response = openai . ChatCompletion . create (
# CHATPG GPT API REQQUEST
model = 'gpt-3.5-turbo' ,
messages = [
{ 'role' : 'user' , 'content' : f' { prompt } ' }
],
max_tokens = max_response_length ,
temperature = 0 ,
stream = True , # this time, we set stream=True
)
for event in response :
# STREAM THE ANSWER
print ( answer , end = '' , flush = True ) # Print the response
# RETRIEVE THE TEXT FROM THE RESPONSE
event_time = time . time () - start_time # CALCULATE TIME DELAY BY THE EVENT
event_text = event [ 'choices' ][ 0 ][ 'delta' ] # EVENT DELTA RESPONSE
answer = event_text . get ( 'content' , '' ) # RETRIEVE CONTENT
time . sleep ( delay_time )
Exécutez le fichier Streams.pnyb troisième partie. Ajoutez une entrée utilisateur et vous devriez voir similaire à ci-dessous:
collected_events = []
completion_text = []
speed = 0.05 #smaller is faster
max_response_length = 200
start_time = time . time ()
prompt = input ( "Ask a question: " )
# Generate Answer
response = openai . Completion . create (
model = 'text-davinci-003' ,
prompt = prompt ,
max_tokens = max_response_length ,
temperature = 0 ,
stream = True , # this time, we set stream=True
)
# Stream Answer
for event in response :
event_time = time . time () - start_time # calculate the time delay of the event
collected_events . append ( event ) # save the event response
event_text = event [ 'choices' ][ 0 ][ 'text' ] # extract the text
completion_text += event_text # append the text
time . sleep ( speed )
print ( f" { event_text } " , end = "" , flush = True )
J'ajoute un fichier "app_streamlit.py" fonctionnel, que vous pouvez fourrer à votre référentiel avec le "exigences.txt" et le déployer en streamlit.
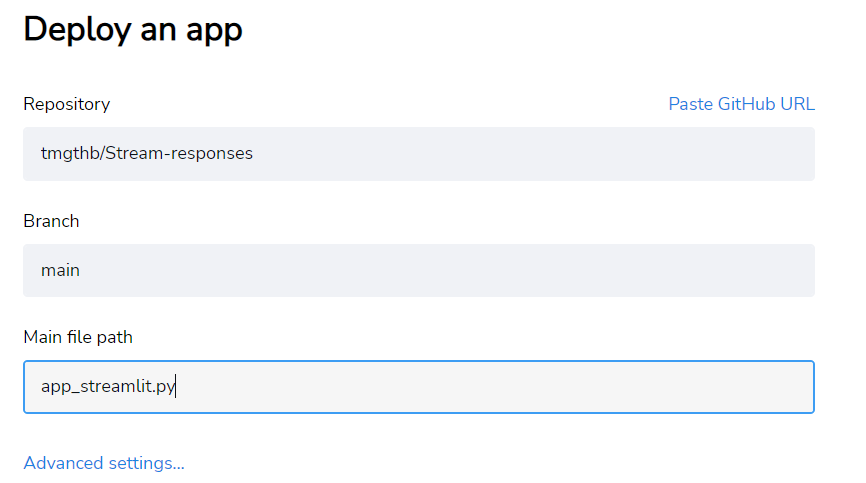
Dans les paramètres avancés, ajoutez le format Openai_API_KEY-Variable à l'aide du format:
OPENAI_API_KEY = "INSERT HERE YOUR KEY" N'hésitez pas à se propager et à améliorer davantage le code conformément à la licence. Par exemple, vous pouvez encore améliorer le ChatML pour vous assurer que le flux suit les règles de "système" souhaitées. Je les ai maintenant vides pour rendre ce script de base très générique. Je recommande de vérifier mes articles spécifiques à l'API ChatGPT sur les réponses en streaming en milieu lié au streaming, au chatml: guidage des invites avec les rôles système, assistant et utilisateur et tutoriel d'introduction de l'API ChatGPT.


