raycast g4f
v4.3
Utilisez les puissants modèles GPT-4, LLAMA-3 et plus d'IA sur Raycast, gratuitement - aucune clé API requise.
Page d'accueil · Politique de confidentialité

"Si vous aimez l'extension, envisagez de lui donner un Tysm Star!" - le développeur, probablement
Cette extension n'est actuellement pas disponible sur le magasin d'extension Raycast, mais l'installation de Source est extrêmement simple.
npm ci --production pour installer les dépendances requises.pip install -r requirements.txt pour installer les dépendances Python. Ceux-ci sont requis pour certaines fonctionnalités, par exemple, recherche Web.npm run dev pour créer et importer l'extension.L'extension et son ensemble complet de commandes devraient ensuite apparaître dans votre application Raycast.
Veuillez ouvrir un problème si des problèmes inattendus se produisent pendant l'installation.
Il y a une prise en charge intégrée pour la mise à jour dans l'extension elle-même! Exécutez simplement la commande "Vérifier les mises à jour" dans l'extension, et il vous occupera du processus de mise à jour pour vous. De plus, vous pouvez également activer la fonctionnalité "Vérifier automatiquement les mises à jour" dans les préférences.
Dans la ligne de commande, exécutez git pull , npm ci --production et npm run dev (dans cet ordre).
Vous voudrez peut-être mettre à jour manuellement si la mise à jour automatique ne fonctionne pas (veuillez également ouvrir un problème GitHub si tel est le cas); La mise à jour manuelle vous permet également de récupérer et de visualiser les dernières modifications du code source.
| Fournisseur | Modèle | Caractéristiques | Statut | Vitesse | Note et remarques par extension auteur |
|---|---|---|---|---|---|
| Nexra | GPT-4O (par défaut) | Très rapide | 8.5 / 10, le modèle le plus performant. | ||
| Nexra | GPT-4-32K | Moyen | 6.5 / 10, pas de support de streaming mais sinon un excellent modèle. | ||
| Nexra | chatte | Très rapide | 7.5 / 10 | ||
| Nexra | Bing | Moyen | 8/10, GPT-4 basé avec les capacités de recherche Web. | ||
| Nexra | lama-3.1 | Rapide | 7/10 | ||
| Nexra | gemini-1.0-pro | Rapide | 6.5 / 10 | ||
| Deepinfra | méta-llama-3.2-90b-vision | Rapide | 8.5 / 10, modèle récent avec capacités de vision. | ||
| Deepinfra | méta-llama-3.2-11b-vision | Très rapide | 7.5 / 10 | ||
| Deepinfra | méta-llama-3.1-405b | Moyen | 8.5 / 10, modèle ouvert de pointe, adapté aux tâches complexes. | ||
| Deepinfra | méta-llama-3.1-70b | Rapide | 8/10, modèle récent avec une grande taille de contexte. | ||
| Deepinfra | méta-llama-3.1-8b | Très rapide | 7.5 / 10, modèle récent avec une grande taille de contexte. | ||
| Deepinfra | LLAMA-3.1-NEMOTRON-70B | Rapide | 8/10 | ||
| Deepinfra | Wizardlm-2-8x22b | Moyen | 7/10 | ||
| Deepinfra | Deepseek-V2.5 | Rapide | 7.5 / 10 | ||
| Deepinfra | Qwen2.5-72b | Moyen | 7.5 / 10 | ||
| Deepinfra | QWEN2.5-CODER-32B | Rapide | 7/10 | ||
| Boîte noire | modèle personnalisé | Rapide | 7.5 / 10, génération très rapide avec une capacité de recherche Web intégrée, mais est optimisée pour le codage. | ||
| Boîte noire | lama-3.1-405b | Rapide | 8.5 / 10 | ||
| Boîte noire | lama-3.1-70b | Très rapide | 8/10 | ||
| Boîte noire | Gémeaux | Extrêmement rapide | 7.5 / 10 | ||
| Boîte noire | GPT-4O | Très rapide | 7.5 / 10 | ||
| Boîte noire | Claude-3.5-Sonnet | Rapide | 8.5 / 10 | ||
| Boîte noire | gemini-pro | Rapide | 8/10 | ||
| Duckduckgo | GPT-4O-MINI | Extrêmement rapide | 8/10, modèle GPT-4O-MINI authentique avec une forte confidentialité. | ||
| Duckduckgo | Claude-3-Haiku | Extrêmement rapide | 7/10 | ||
| Duckduckgo | méta-llama-3.1-70b | Très rapide | 7.5 / 10 | ||
| Duckduckgo | mixtral-8x7b | Extrêmement rapide | 7.5 / 10 | ||
| Bestim | GPT-4O-MINI | Extrêmement rapide | 8.5 / 10 | ||
| Rochers | Claude-3.5-Sonnet | Rapide | 8.5 / 10 | ||
| Rochers | Claude-3-opus | Rapide | 8/10 | ||
| Rochers | GPT-4O | Rapide | 7.5 / 10 | ||
| Rochers | gpt-4 | Rapide | 7.5 / 10 | ||
| Rochers | lama-3.1-405b | Rapide | 7.5 / 10 | ||
| Rochers | lama-3.1-70b | Très rapide | 7/10 | ||
| Chatpptfree | GPT-4O-MINI | Extrêmement rapide | 8.5 / 10 | ||
| Ai4chat | gpt-4 | Très rapide | 7.5 / 10 | ||
| Darkai | GPT-4O | Très rapide | 8/10 | ||
| Mhystique | GPT-4-32K | Très rapide | 6.5 / 10 | ||
| Pizzagpt | GPT-4O-MINI | Extrêmement rapide | 7.5 / 10 | ||
| Meta Ai | méta-llama-3.1 | Moyen | 7/10, modèle récent avec accès Internet. | ||
| Reproduire | mixtral-8x7b | Moyen | ? / 10 | ||
| Reproduire | méta-llama-3.1-405b | Moyen | ? / 10 | ||
| Reproduire | méta-llama-3-70b | Moyen | ? / 10 | ||
| Reproduire | méta-llama-3-8b | Rapide | ? / 10 | ||
| Bêler | Phind Instant | Extrêmement rapide | 8/10 | ||
| Google Gemini | Auto (Gemini-1.5-Pro, Gemini-1.5-Flash) | Très rapide | 9/10, très bon modèle global mais nécessite une clé API. (C'est gratuit , voir la section ci-dessous) | ||
| API local GPT4FREE | - | - | permet d'accéder à une grande variété de prestataires. En savoir plus | ||
| API local olllama | - | - | permet l'inférence locale. En savoir plus | ||
| API compatible Openai personnalisé | - | - | vous permet d'utiliser toute API compatible OpenAI personnalisée. En savoir plus |
? - prend en charge le téléchargement de fichiers. Remarque : Par défaut, tous les fournisseurs prennent en charge les fonctionnalités de téléchargement de fichiers de base pour les fichiers basés sur le texte, comme .txt, .md, etc.
¹: prend en charge les images uniquement.
La limite de taux pour Google Gemini est de 1500 demandes par jour (au moment de la rédaction). Cela devrait être bien plus que suffisant pour toute utilisation normale. Si votre cas d'utilisation a besoin d'une limite de taux accrue, vous pouvez même créer plusieurs clés d'API avec différents comptes Google; séparez-les avec des virgules dans les préférences.
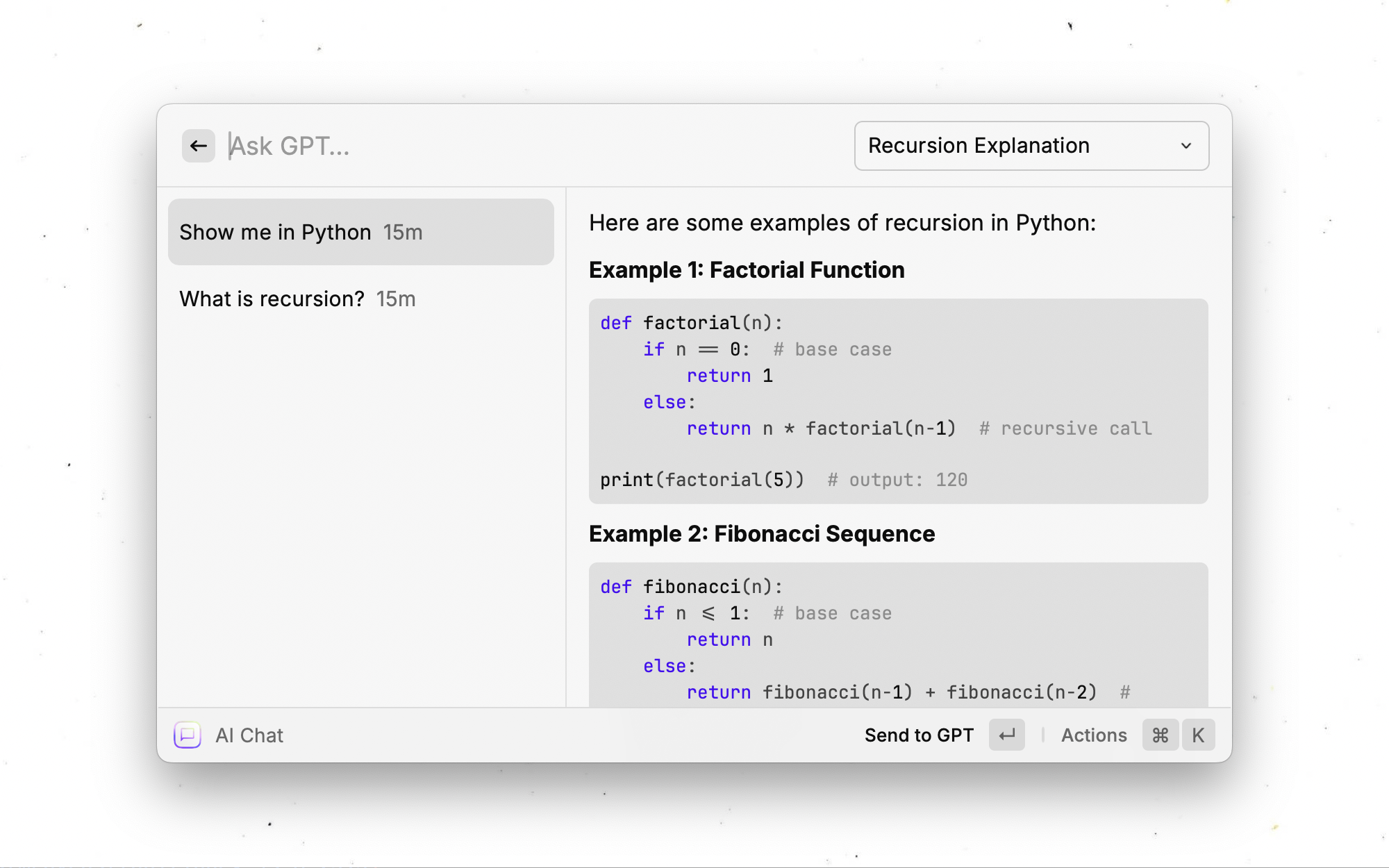
Laissez GPT décider de rechercher des informations sur le Web s'il n'a pas suffisamment de connaissances ou de contexte. Utilise la recherche DuckDuckgo, rapide et gratuite.
L'activation de la recherche Web est rapide et facile. Accédez aux préférences d'extension et l'option "Recherche Web" sera disponible. Il y a 4 options:
¹: Les commandes qui prennent en charge la recherche Web sont: Demandez à l'IA, demandez-vous sur le texte sélectionné, expliquez. D'autres commandes n'utiliseront pas la recherche Web.
La recherche Web est également disponible dans les commandes suivantes:
Laissez GPT proposer automatiquement un nom pour la session de chat en cours après avoir envoyé le premier message. Par exemple, cela est similaire à ce que fait l'interface utilisateur Web Chatgpt.
Laissez l'extension vérifier automatiquement les mises à jour chaque jour. Si une nouvelle version est disponible, vous serez informé, ainsi que l'option de mettre à jour l'extension en un seul clic.
Activer le stockage plus persistant des données de l'extension, comme les données de chat AI ou les commandes personnalisées. Cela sauvegardera une copie de ces données dans les fichiers de votre ordinateur. Utile pour enregistrer de grandes quantités de données. Remarque: avec cette option désactivée, vos données sont déjà bien conservées. N'activez pas cela si vous avez des données sensibles.
Affichez une icône de curseur lorsque la réponse charge - option cosmétique uniquement.
Permet à GPT d'exécuter le code Python localement. Le modèle a été chargé de ne produire strictement que du code sûr, mais utilisez à vos risques et périls!
Seuls les modèles avec des capacités d'appel de fonction prennent en charge cette fonctionnalité. Actuellement, cela comprend uniquement des modèles Deepinfra sélectionnés.
Licence: GPLV3. La licence complète se trouve dans Licence.txt.
La base de code est dérivée de Raycast Gemini par Evan Zhou.
Bibliothèques tierces utilisées pour la génération:
(Les deux packages sont maintenus par l'auteur d'extension.)
Une partie du code de ce référentiel a été inspirée ou portée à partir du projet GPT4Free original (écrit en Python).


