raycast g4f
v4.3
Use los poderosos modelos GPT-4, LLAMA-3 y más IA en Raycast, de forma gratuita, no se requiere una clave API.
Página de inicio · Política de privacidad

"Si te gusta la extensión, ¡considera darle un Tysm Star!" - El desarrollador, probablemente
Esta extensión no está disponible actualmente en la tienda de extensión Raycast, pero la instalación desde la fuente es extremadamente simple.
npm ci --production para instalar las dependencias requeridas.pip install -r requirements.txt para instalar dependencias de Python. Estos son necesarios para algunas características, por ejemplo, búsqueda web.npm run dev para construir e importar la extensión.La extensión, y su conjunto completo de comandos, deberían aparecer en su aplicación Raycast.
Abra un problema si se producen problemas inesperados durante la instalación.
¡Hay soporte incorporado para actualizar dentro de la extensión misma! Simplemente ejecute el comando "Verifique las actualizaciones" en la extensión, y se encargará del proceso de actualización para usted. Además, también puede habilitar la función "Verificar automáticamente las actualizaciones" en las preferencias.
En la línea de comando, ejecute git pull , npm ci --production y npm run dev (en ese orden).
Es posible que desee actualizar manualmente si la actualización automática no funciona (también abra un problema de GitHub si este es el caso); La actualización manualmente también le permite obtener y ver los últimos cambios en el código fuente.
| Proveedor | Modelo | Características | Estado | Velocidad | Calificación y observaciones de Extension Autor |
|---|---|---|---|---|---|
| Nexra | GPT-4O (predeterminado) | Muy rápido | 8.5/10, el modelo de mejor rendimiento. | ||
| Nexra | GPT-4-32K | Medio | 6.5/10, sin soporte de transmisión, pero por lo demás es un gran modelo. | ||
| Nexra | chatgpt | Muy rápido | 7.5/10 | ||
| Nexra | Aturdir | Medio | 8/10, GPT-4 basado con capacidades de búsqueda web. | ||
| Nexra | Llama-3.1 | Rápido | 7/10 | ||
| Nexra | Géminis-1.0-Pro | Rápido | 6.5/10 | ||
| Profundo | meta-llama-3.2-90b-visión | Rápido | 8.5/10, modelo reciente con capacidades de visión. | ||
| Profundo | meta-llama-3.2-11b-visión | Muy rápido | 7.5/10 | ||
| Profundo | meta-llama-3.1-405b | Medio | 8.5/10, modelo abierto de última generación, adecuado para tareas complejas. | ||
| Profundo | meta-llama-3.1-70b | Rápido | 8/10, modelo reciente con gran tamaño de contexto. | ||
| Profundo | meta-llama-3.1-8b | Muy rápido | 7.5/10, modelo reciente con gran tamaño de contexto. | ||
| Profundo | Llama-3.1-Nemotron-70b | Rápido | 8/10 | ||
| Profundo | Wizardlm-2-8x22b | Medio | 7/10 | ||
| Profundo | Deepseek-v2.5 | Rápido | 7.5/10 | ||
| Profundo | Qwen2.5-72b | Medio | 7.5/10 | ||
| Profundo | QWEN2.5-CODER-32B | Rápido | 7/10 | ||
| Cajón negro | modelo personalizado | Rápido | 7.5/10, generación muy rápida con capacidad de búsqueda web incorporada, pero está optimizado para la codificación. | ||
| Cajón negro | LLAMA-3.1-405B | Rápido | 8.5/10 | ||
| Cajón negro | LLAMA-3.1-70B | Muy rápido | 8/10 | ||
| Cajón negro | Géminis-1.5 flash | Extremadamente rápido | 7.5/10 | ||
| Cajón negro | GPT-4O | Muy rápido | 7.5/10 | ||
| Cajón negro | Claude-3.5-Sonnet | Rápido | 8.5/10 | ||
| Cajón negro | gemini-pro | Rápido | 8/10 | ||
| Duckduckgo | GPT-4O-Mini | Extremadamente rápido | 8/10, auténtico modelo GPT-4O-Mini con fuerte privacidad. | ||
| Duckduckgo | Claude-3-Haiku | Extremadamente rápido | 7/10 | ||
| Duckduckgo | meta-llama-3.1-70b | Muy rápido | 7.5/10 | ||
| Duckduckgo | mixtral-8x7b | Extremadamente rápido | 7.5/10 | ||
| Bestim | GPT-4O-Mini | Extremadamente rápido | 8.5/10 | ||
| Rocas | Claude-3.5-Sonnet | Rápido | 8.5/10 | ||
| Rocas | Claude-3-opus | Rápido | 8/10 | ||
| Rocas | GPT-4O | Rápido | 7.5/10 | ||
| Rocas | GPT-4 | Rápido | 7.5/10 | ||
| Rocas | LLAMA-3.1-405B | Rápido | 7.5/10 | ||
| Rocas | LLAMA-3.1-70B | Muy rápido | 7/10 | ||
| Chatgptfree | GPT-4O-Mini | Extremadamente rápido | 8.5/10 | ||
| Ai4chat | GPT-4 | Muy rápido | 7.5/10 | ||
| Darkai | GPT-4O | Muy rápido | 8/10 | ||
| Mágico | GPT-4-32K | Muy rápido | 6.5/10 | ||
| Pizzagpt | GPT-4O-Mini | Extremadamente rápido | 7.5/10 | ||
| Meta ai | meta-llama-3.1 | Medio | 7/10, modelo reciente con acceso a Internet. | ||
| Reproducir exactamente | mixtral-8x7b | Medio | ?/10 | ||
| Reproducir exactamente | meta-llama-3.1-405b | Medio | ?/10 | ||
| Reproducir exactamente | meta-llama-3-70b | Medio | ?/10 | ||
| Reproducir exactamente | meta-llama-3-8b | Rápido | ?/10 | ||
| Tirada | Instantáneo | Extremadamente rápido | 8/10 | ||
| Google Géminis | Auto (Géminis-1.5-Pro, Géminis-1.5-Flash) | Muy rápido | 9/10, muy buen modelo general pero requiere una clave API. (Es gratis , vea la sección a continuación) | ||
| API local de GPT4Free | - | - | Permite el acceso a una gran variedad de proveedores. leer más | ||
| API local de Ollama | - | - | Permite la inferencia local. leer más | ||
| API personalizada compatible con Openai | - | - | Le permite usar cualquier API personalizada compatible con OpenAI. leer más |
? - Admite la carga de archivo. Nota : Por defecto, todos los proveedores admiten la funcionalidad de carga de archivos básicos para archivos basados en texto, como .txt, .md, etc.
¹: Solo admite imágenes.
El límite de tarifa para Google Gemini es de 1500 solicitudes por día (al momento de escribir). Esto debería ser mucho más que suficiente para cualquier uso normal. Si su caso de uso necesita un límite de tarifa aumentado, incluso puede crear múltiples claves API con diferentes cuentas de Google; separarlos con comas en las preferencias.
Deje que GPT decida buscar información si no tiene suficiente conocimiento o contexto. Utiliza la búsqueda de Duckduckgo, rápida y gratuita.
Habilitar la búsqueda web es rápido y fácil. Vaya a las preferencias de extensión y la opción "Búsqueda web" estará disponible. Hay 4 opciones:
¹: Los comandos que admiten la búsqueda web son: Pregunte a AI, pregunte sobre el texto seleccionado, explique. Otros comandos no utilizarán la búsqueda web.
Web Search también está disponible en los siguientes comandos:
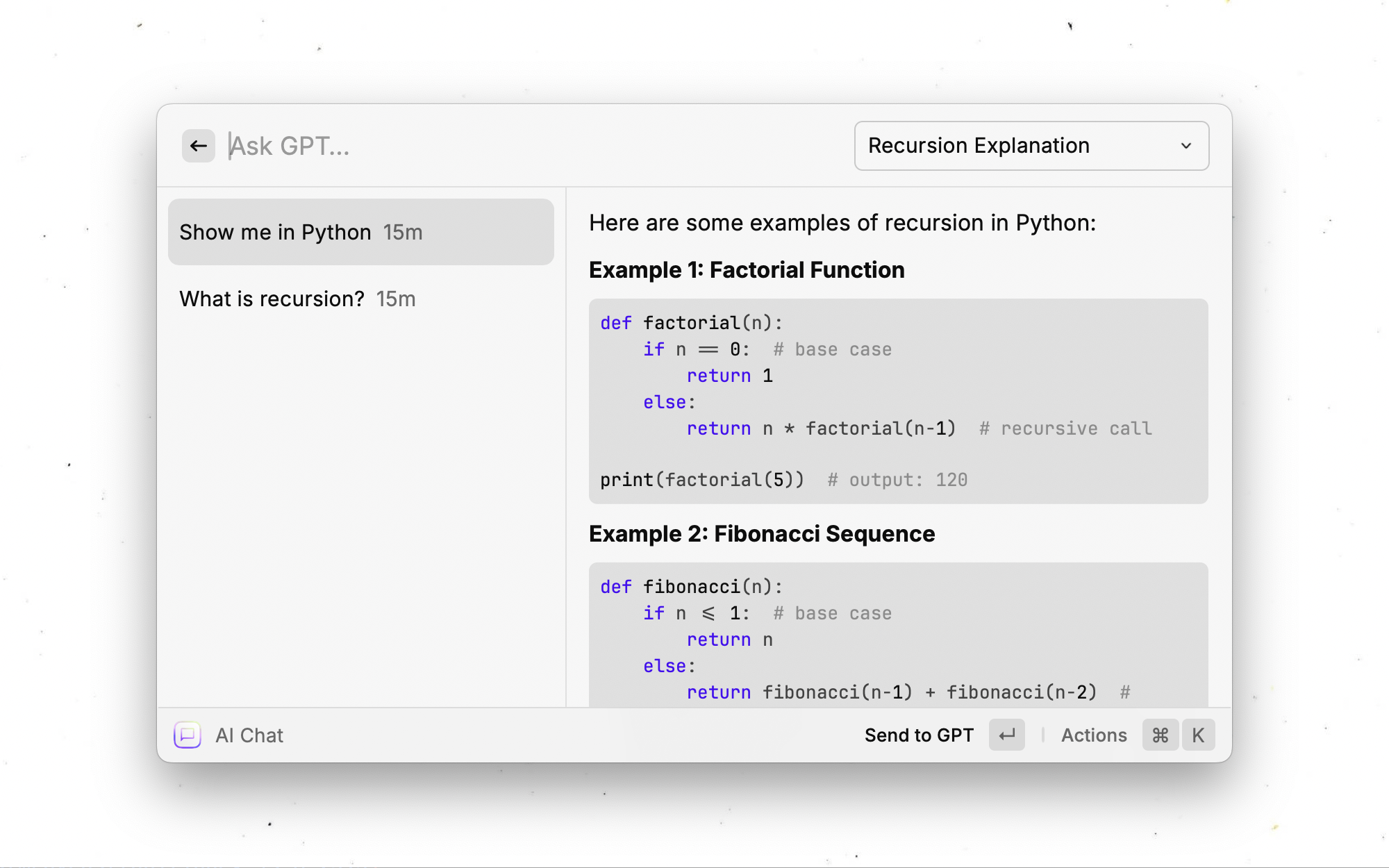
Deje que GPT presente automáticamente un nombre para la sesión de chat actual después de enviar el primer mensaje. Por ejemplo, esto es similar a lo que hace la interfaz de usuario web ChatGPT.
Deje que la extensión verifique automáticamente las actualizaciones todos los días. Si hay una nueva versión disponible, se le notificará, junto con la opción de actualizar la extensión con un solo clic.
Habilite el almacenamiento más persistente de los datos de la extensión, como datos de chat de IA o comandos personalizados. Esto respaldará una copia de estos datos a los archivos en su computadora. Útil para guardar grandes cantidades de datos. Nota: Con esta opción apagada, sus datos ya están bien conservados. No habilite esto si tiene datos confidenciales.
Muestre un icono del cursor cuando la respuesta se carga - Opción cosmética solamente.
Permite a GPT ejecutar el código Python localmente. El modelo ha recibido instrucciones de producir estrictamente solo producir un código seguro, ¡pero use bajo su propio riesgo!
Solo los modelos con capacidades de llamadas de funciones admiten esta función. Actualmente, esto incluye solo modelos DeepinFRA seleccionados.
Licencia: GPLV3. La licencia completa se encuentra en License.txt.
La base del código se deriva de Raycast Gemini por Evan Zhou.
Bibliotecas de terceros utilizadas para la generación:
(Ambos paquetes son mantenidos por el autor de extensión).
Parte del código en este repositorio se inspiró o se portó desde el proyecto GPT4Free original (escrito en Python).


