topicGPT
v0.2.2 Removed redundant parameters
Ce référentiel contient des scripts et des invites à notre article "TopicGpt: Modélisation des sujets en invitant de grands modèles de langage" (NAACL'24). Notre package topicgpt_python se compose de cinq fonctions principales:
generate_topic_lvl1 génère des sujets de haut niveau et généralisables.generate_topic_lvl2 génère des sujets de bas niveau et spécifiques à chaque sujet de haut niveau.refine_topics affine les sujets générés en fusionnant des sujets similaires et en supprimant des sujets non pertinents.assign_topics Attribue les sujets générés au texte d'entrée, ainsi qu'un devis qui prend en charge l'affectation.correct_topics corrige les sujets générés en réploriant le modèle afin que l'affectation de sujet finale soit fondée sur la liste des sujets. 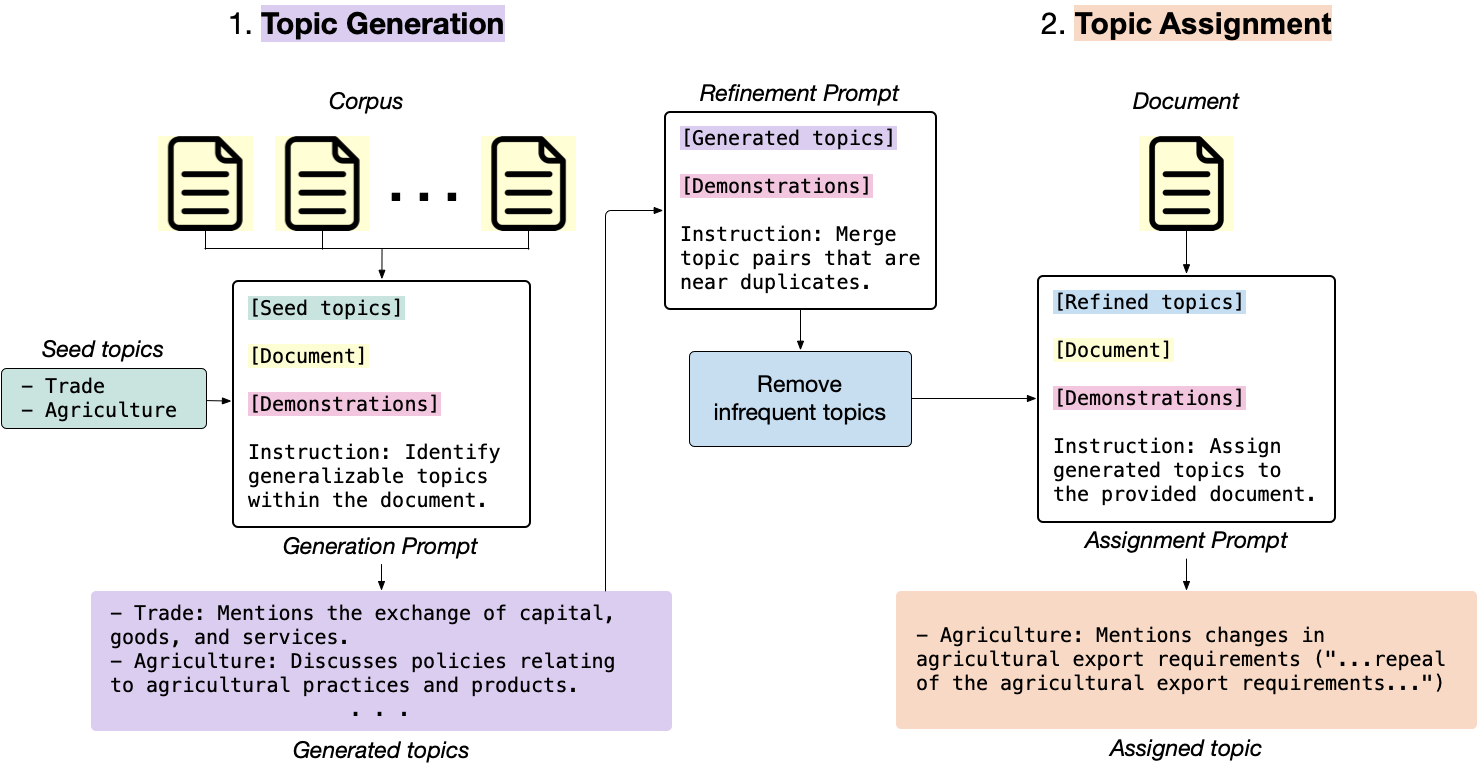
topicgpt_python est publié! Vous pouvez l'installer via pip install topicgpt_python . Nous prenons en charge l'API OpenAI, Vertexai, Azure API, Gemini API et VLLM (nécessite des GPU pour l'inférence). Voir PYPI. pip install topicgpt_python
# Run in shell
# Needed only for the OpenAI API deployment
export OPENAI_API_KEY={your_openai_api_key}
# Needed only for the Vertex AI deployment
export VERTEX_PROJECT={your_vertex_project} # e.g. my-project
export VERTEX_LOCATION={your_vertex_location} # e.g. us-central1
# Needed only for Gemini deployment
export GEMINI_API_KEY={your_gemini_api_key}
# Needed only for the Azure API deployment
export AZURE_OPENAI_API_KEY={your_azure_api_key}
export AZURE_OPENAI_ENDPOINT={your_azure_endpoint}
.jsonl dans le format suivant: {
" id " : " IDs (optional) " ,
" text " : " Documents " ,
" label " : " Ground-truth labels (optional) "
}data/input . Il existe également un exemple de données de fichiers data/input/sample.jsonl pour déboguer le code. Consultez demo.ipynb pour un pipeline complet et des instructions plus détaillées. Nous vous conseillons d'essayer de fonctionner sur un sous-ensemble avec des modèles moins chers (ou open source) avant de passer à l'ensemble de l'ensemble de données.
(Facultatif) Définissez les chemins d'E / S dans config.yml et chargez en utilisant:
import yaml
with open ( "config.yml" , "r" ) as f :
config = yaml . safe_load ( f )Chargez le package:
from topicgpt_python import *Générer des sujets de haut niveau:
generate_topic_lvl1 ( api , model , data , prompt_file , seed_file , out_file , topic_file , verbose )Générer des sujets de bas niveau (en option)
generate_topic_lvl2 ( api , model , seed_file , data , prompt_file , out_file , topic_file , verbose )Affinez les sujets générés en fusionnant des doublons près et en supprimant des sujets à basse fréquence (facultatif):
refine_topics ( api , model , prompt_file , generation_file , topic_file , out_file , updated_file , verbose , remove , mapping_file )Attribuez et corrigez les sujets, généralement avec un modèle plus faible si vous utilisez des API payantes pour économiser le coût:
assign_topics (
api , model , data , prompt_file , out_file , topic_file , verbose
) correct_topics(
api, model, data_path, prompt_path, topic_path, output_path, verbose
)
Découvrez le dossier data/output pour les sorties d'échantillons.
Nous proposons également des fonctions de calcul métrique dans topicgpt_python.metrics pour évaluer l'alignement entre les sujets générés et les étiquettes de la truth au sol (indice RAND ajusté, pureté harmonique et informations mutuelles normalisées).
@misc{pham2023topicgpt,
title={TopicGPT: A Prompt-based Topic Modeling Framework},
author={Chau Minh Pham and Alexander Hoyle and Simeng Sun and Mohit Iyyer},
year={2023},
eprint={2311.01449},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


