topicGPT
v0.2.2 Removed redundant parameters
Dieses Repository enthält Skripte und Aufforderungen für unser Papier "TopicGPT: Topic -Modellierung, indem sie große Sprachmodelle auffordert" (Naacl'24). Unser topicgpt_python -Paket besteht aus fünf Hauptfunktionen:
generate_topic_lvl1 erzeugt hochrangige und verallgemeinerbare Themen.generate_topic_lvl2 erzeugt für jedes hochrangige Thema niedrige und bestimmte Themen.refine_topics verfeinert die generierten Themen, indem sie ähnliche Themen zusammenführen und irrelevante Themen entfernen.assign_topics weist dem Eingabetxt die generierten Themen zusammen mit einem Zitat zu, das die Zuordnung unterstützt.correct_topics korrigiert die generierten Themen, indem das Modell so neu gestaltet wird, damit die endgültige Themenzuweisung in der Themenliste begründet ist. 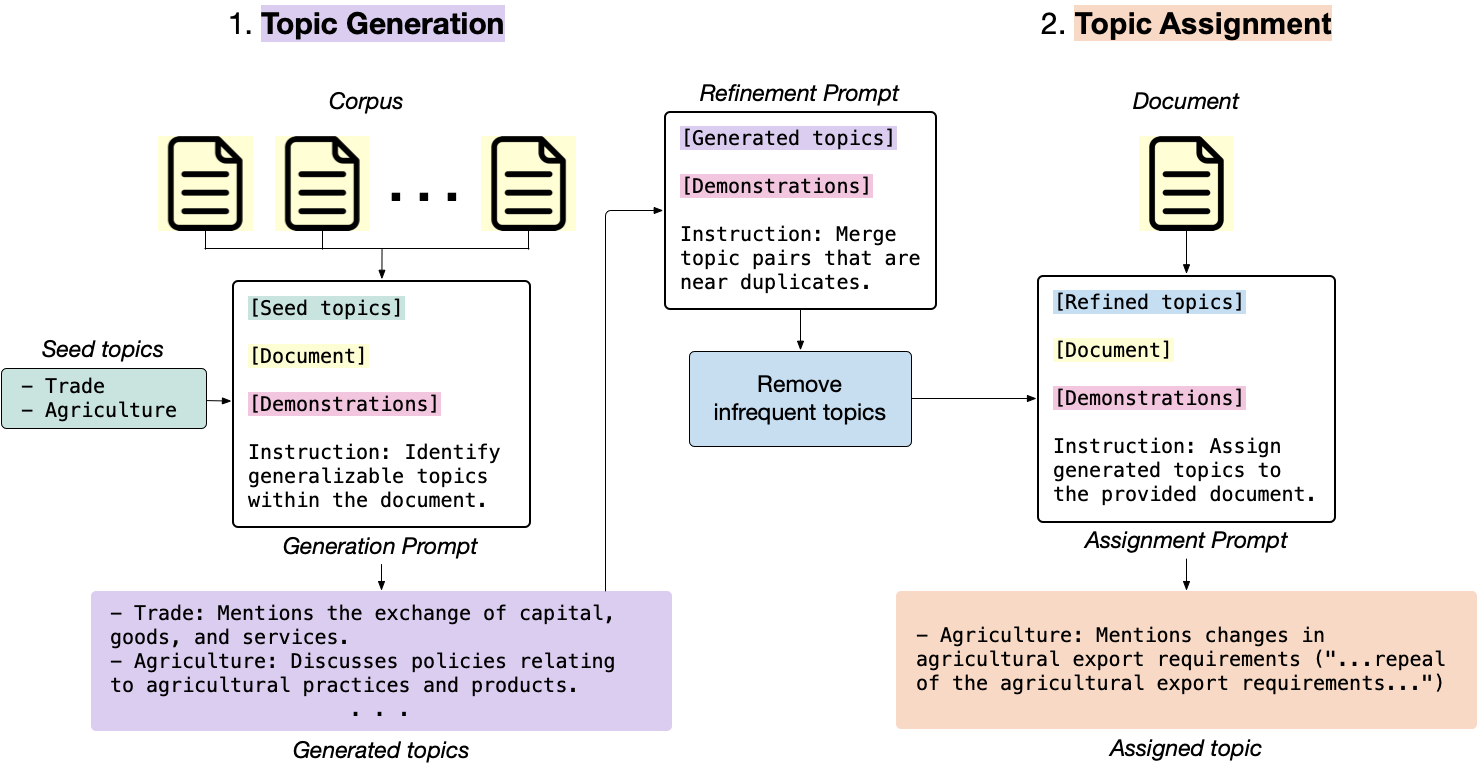
topicgpt_python wird veröffentlicht! Sie können es über pip install topicgpt_python . Wir unterstützen OpenAI -API, Vertexai, Azure -API, Gemini API und VLLM (erfordert GPUs für Inferenz). Siehe Pypi. pip install topicgpt_python
# Run in shell
# Needed only for the OpenAI API deployment
export OPENAI_API_KEY={your_openai_api_key}
# Needed only for the Vertex AI deployment
export VERTEX_PROJECT={your_vertex_project} # e.g. my-project
export VERTEX_LOCATION={your_vertex_location} # e.g. us-central1
# Needed only for Gemini deployment
export GEMINI_API_KEY={your_gemini_api_key}
# Needed only for the Azure API deployment
export AZURE_OPENAI_API_KEY={your_azure_api_key}
export AZURE_OPENAI_ENDPOINT={your_azure_endpoint}
.jsonl -Datendatei im folgenden Format vor: {
" id " : " IDs (optional) " ,
" text " : " Documents " ,
" label " : " Ground-truth labels (optional) "
}data/input . Es gibt auch eine Beispieldatendatendaten data/input/sample.jsonl um den Code zu debuggen. In demo.ipynb finden Sie eine vollständige Pipeline und detailliertere Anweisungen. Wir empfehlen Ihnen, zuerst auf einer Untergruppe mit billigeren (oder Open-Source) -Modellen zu laufen, bevor Sie sich bis zum gesamten Datensatz skalieren.
(Optional) Definieren Sie E/A -Pfade in config.yml und laden Sie mit:
import yaml
with open ( "config.yml" , "r" ) as f :
config = yaml . safe_load ( f )Laden Sie das Paket:
from topicgpt_python import *Erzeugen Sie hochrangige Themen:
generate_topic_lvl1 ( api , model , data , prompt_file , seed_file , out_file , topic_file , verbose )Erzeugen Sie niedrige Themen (optional)
generate_topic_lvl2 ( api , model , seed_file , data , prompt_file , out_file , topic_file , verbose )Verfeinern Sie die generierten Themen, indem Sie in der Nähe von Duplikaten zusammenführen und Themen mit niedriger Frequenz (optional) entfernen:
refine_topics ( api , model , prompt_file , generation_file , topic_file , out_file , updated_file , verbose , remove , mapping_file )Weisen und korrigieren Sie die Themen, normalerweise mit einem schwächeren Modell, wenn Sie kostenpflichtige APIs verwenden, um Kosten zu sparen:
assign_topics (
api , model , data , prompt_file , out_file , topic_file , verbose
) correct_topics(
api, model, data_path, prompt_path, topic_path, output_path, verbose
)
Schauen Sie sich den data/output für Beispielausgänge an.
Wir bieten auch metrische Berechnungsfunktionen in topicgpt_python.metrics an, um die Ausrichtung zwischen den generierten Themen und den Boden-Wahrheit-Etiketten (angepasster Rand-Index, harmonischer Reinheit und normalisierten gegenseitigen Informationen) zu bewerten.
@misc{pham2023topicgpt,
title={TopicGPT: A Prompt-based Topic Modeling Framework},
author={Chau Minh Pham and Alexander Hoyle and Simeng Sun and Mohit Iyyer},
year={2023},
eprint={2311.01449},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


