tf glow tts
Glow-TTS POC
(Unofficial) Tensorflow implementation of Glow-TTS, Jaehyeon Kim et al., in NeurIPS 2020.
Tested in python 3.8.5 windows10 conda environment, requirements.txt
To download LJ-Speech dataset, run under script.
Dataset will be downloaded in '~/tensorflow_datasets' in tfrecord format. If you want to change the download directory, specify data_dir parameter of LJSpeech initializer.
from dataset.ljspeech import LJSpeech
# lj = LJSpeech(data_dir=path, download=True)
lj = LJSpeech(download=True) To train model, run train.py.
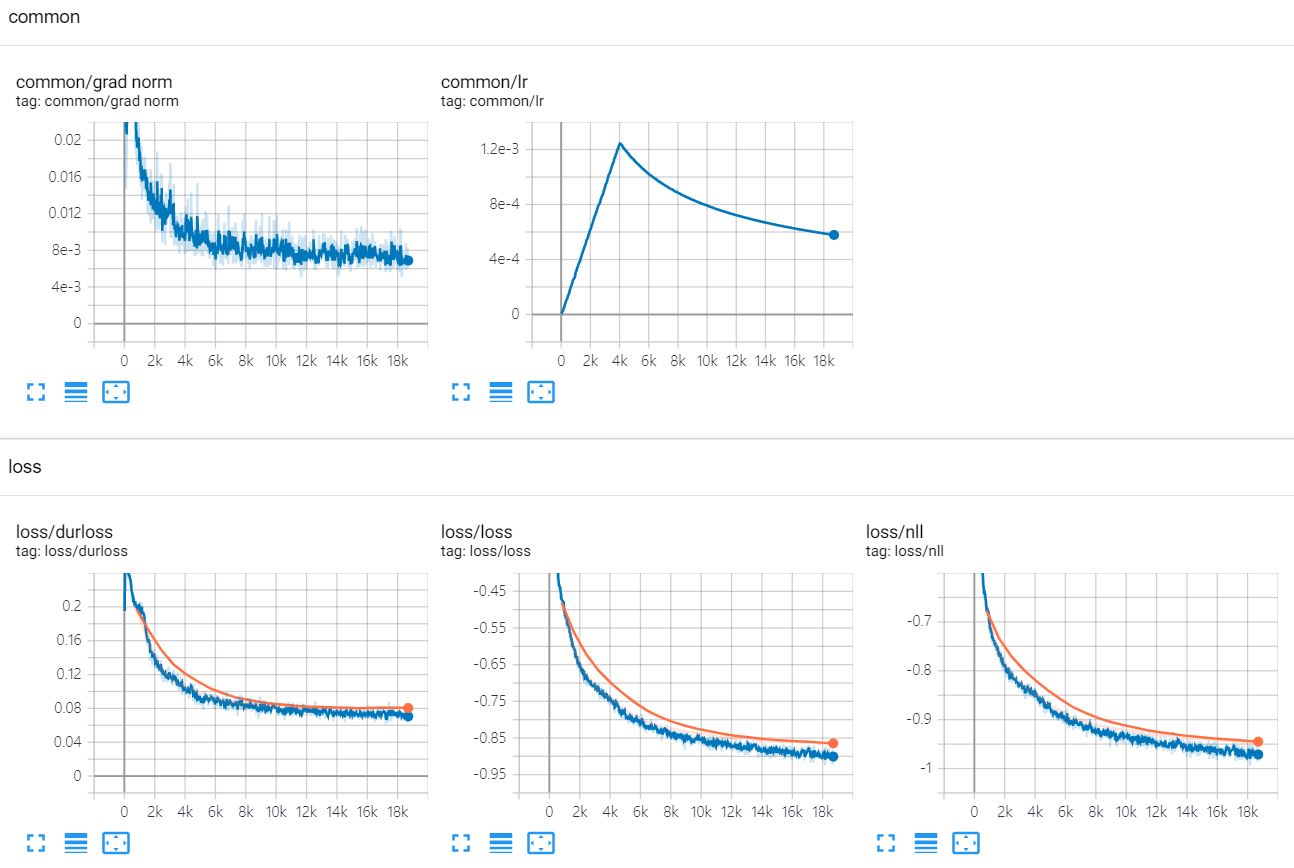
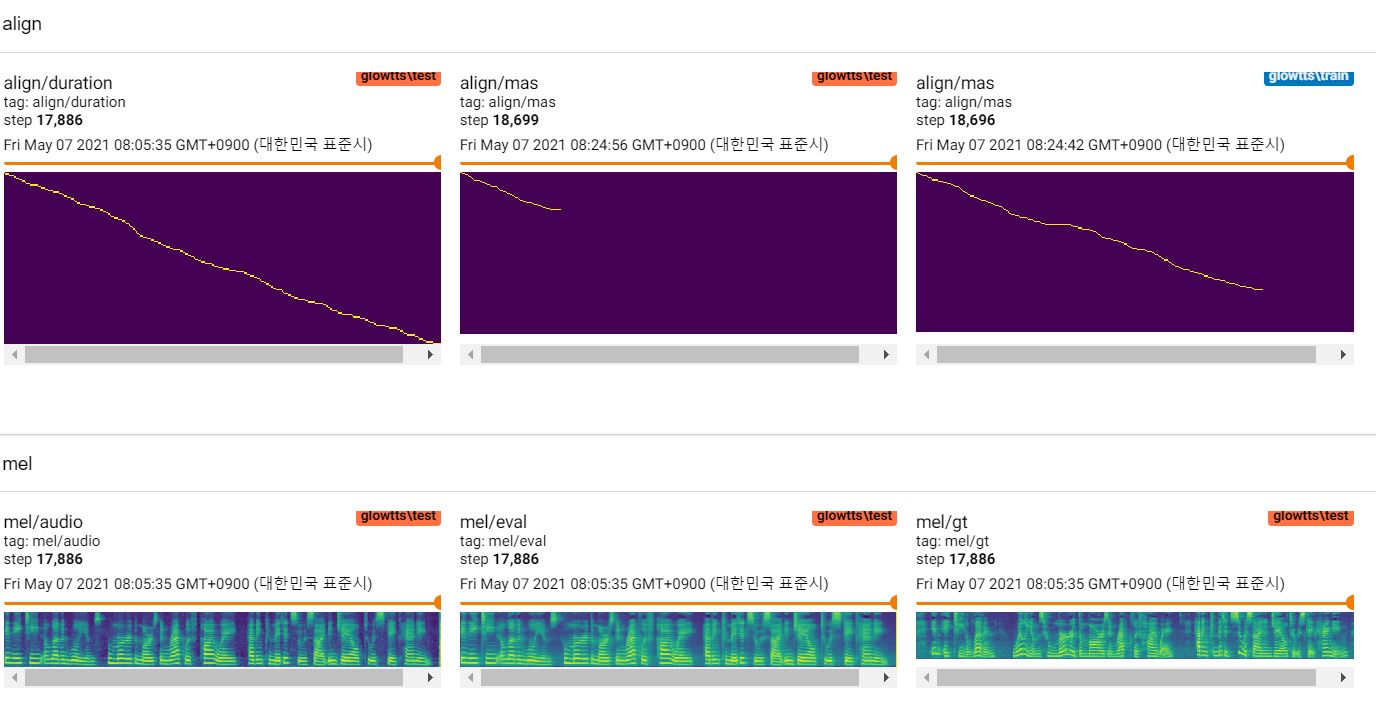
Checkpoint will be written on TrainConfig.ckpt, tensorboard summary on TrainConfig.log.
python train.py
tensorboard --logdir .logIf you want to train model from raw audio, specify audio directory and turn on the flag --from-raw.
python .train.py --data-dir D:LJSpeech-1.1wavs --from-rawTo start to train from previous checkpoint, --load-epoch is available.
python .train.py --load-epoch 20 --config D:tfckptglowtts.jsonTo inference the audio, run inference.py.
Since this code is for POC, only alphabets and several special characters are available, reference TextNormalizer.GRAPHEMES.
python .inference.py
--config D:tfckptglowtts.json
--ckpt D:tfckptglowttsglowtts_20.ckpt-1
--text "Hello, my name is revsic"Pretrained checkpoints are relased on releases.
To use pretrained model, download files and unzip it. Followings are sample script.
from config import Config
from glowtts import GlowTTS
with open('glowtts.json') as f:
config = Config.load(json.load(f))
tts = GlowTTS(config.model)
tts.restore('./glowtts_20.ckpt-1').expect_partial()train LJSpeech 20 epochs with tf-diffwave
Reference https://revsic.github.io/tf-glow-tts.


