tf glow tts
Glow-TTS POC
(غير رسمي) تنفيذ Tensorflow من Glow-TTS ، Jaehyeon Kim et al. ، في Neups 2020.
تم اختباره في بيثون 3.8.5 بيئة Windows10 كوندا ، المتطلبات. txt
لتنزيل مجموعة بيانات LJ-Speech ، قم بتشغيله تحت البرنامج النصي.
سيتم تنزيل مجموعة البيانات في "~/TensorFlow_Datasets" بتنسيق tfrecord. إذا كنت ترغب في تغيير دليل التنزيل ، فحدد معلمة data_dir من LJSpeech Enthomizer.
from dataset . ljspeech import LJSpeech
# lj = LJSpeech(data_dir=path, download=True)
lj = LJSpeech ( download = True ) لتدريب الطراز ، تشغيل Train.py.
سيتم كتابة نقطة التفتيش على TrainConfig.ckpt ، ملخص Tensorboard على TrainConfig.log .
python train.py
tensorboard --logdir . l og إذا كنت ترغب في تدريب النموذج من Raw Audio ، حدد دليل الصوت وقم بتشغيل العلم --from-raw .
python . t rain.py --data-dir D: L JSpeech-1.1 w avs --from-raw للبدء في التدريب من نقطة تفتيش سابقة ، --load-epoch المتاح.
python . t rain.py --load-epoch 20 --config D: t f c kpt g lowtts.json لاستدلال الصوت ، قم بتشغيل interference.py.
نظرًا لأن هذا الرمز مخصص لـ POC ، تتوفر الحروف الهجائية فقط والعديد من الأحرف الخاصة ، المرجعية textNormalizer.graphemes.
python . i nference.py
--config D: t f c kpt g lowtts.json
--ckpt D: t f c kpt g lowtts g lowtts_20.ckpt-1
--text " Hello, my name is revsic "يتم ربط نقاط التفتيش المسبقة على الإصدارات.
لاستخدام النموذج المسبق ، قم بتنزيل الملفات وفك ضغطه. فيما يلي عينة نص.
from config import Config
from glowtts import GlowTTS
with open ( 'glowtts.json' ) as f :
config = Config . load ( json . load ( f ))
tts = GlowTTS ( config . model )
tts . restore ( './glowtts_20.ckpt-1' ). expect_partial ()تدريب LJSpeech 20 عصر مع TF-Diffwave
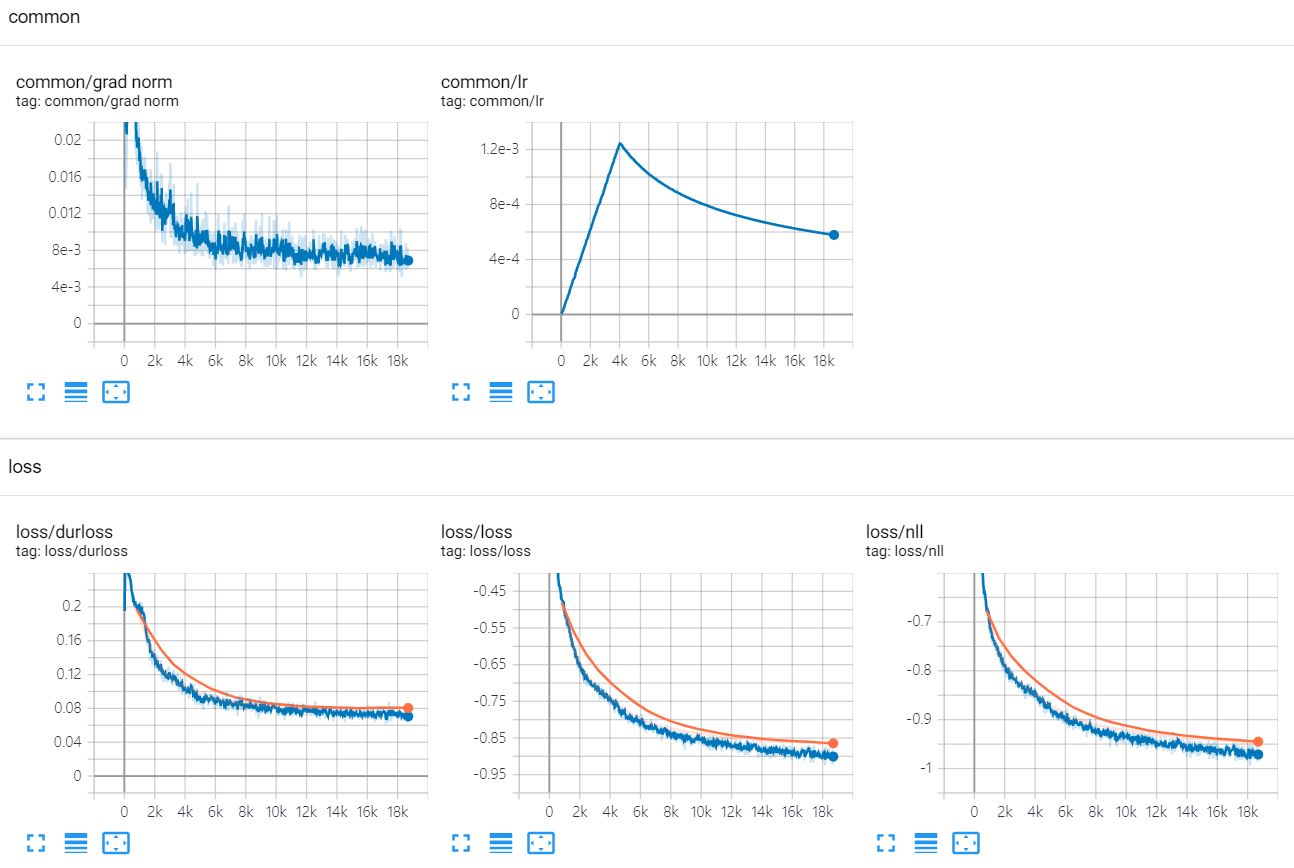
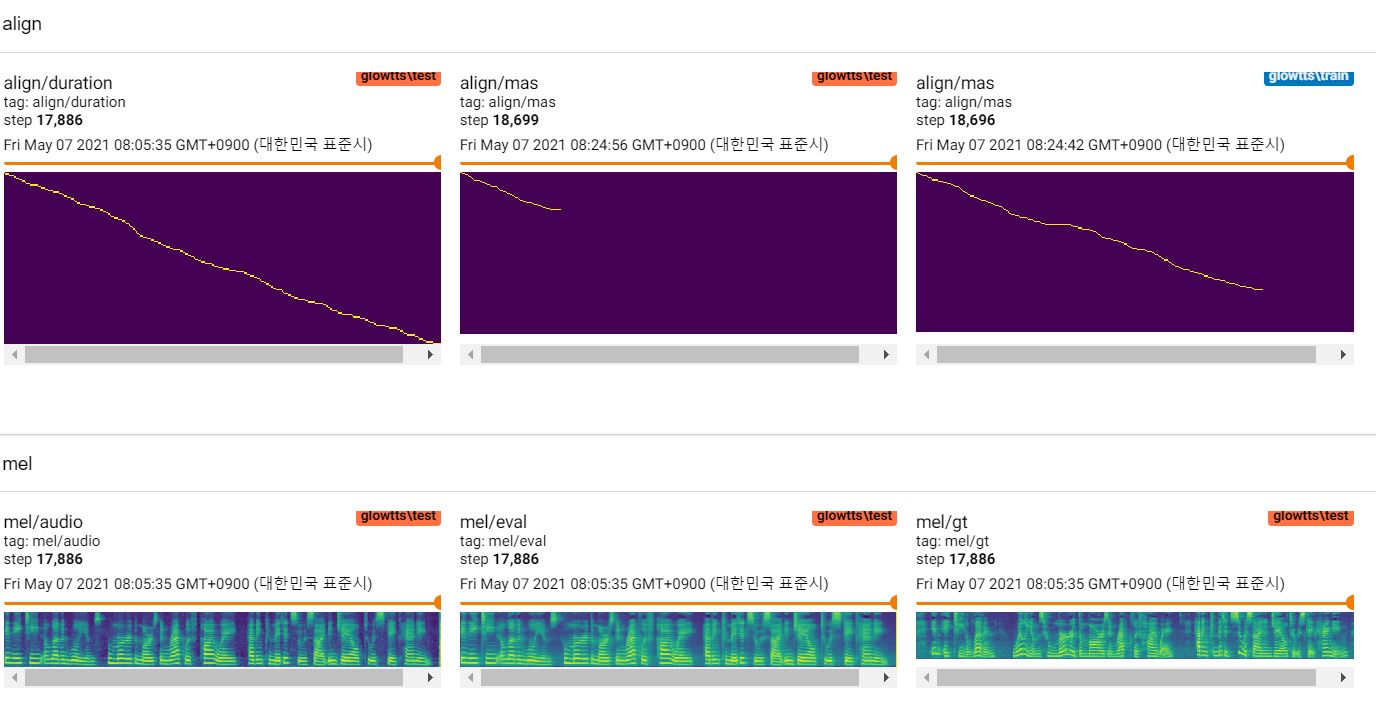
المرجع https://revsic.github.io/tf-glow-tts.


