? Coala: Fantastische Sprachagenten
Eine Zusammenstellung von Sprachagenten, die die kognitiven Architekturen für Sprachagenten (? COALA) verwenden.
- Coala -Papier (16 Seiten des Hauptinhalts): https://arxiv.org/abs/2309.02427
- Coala Tweet (6 Threads): https://twitter.com/shunyuyao12/status/1699396834983362690
- Coala Bibtex -Datei mit 300+ verwandten Zitaten: Coala.bib
- Coala Bibtex Zitat Wenn Sie unsere Arbeit/Ressourcen nützlich finden:
@misc { sumers2023cognitive ,
title = { Cognitive Architectures for Language Agents } ,
author = { Theodore Sumers and Shunyu Yao and Karthik Narasimhan and Thomas L. Griffiths } ,
year = { 2023 } ,
eprint = { 2309.02427 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.AI }
}? Coala -Übersicht
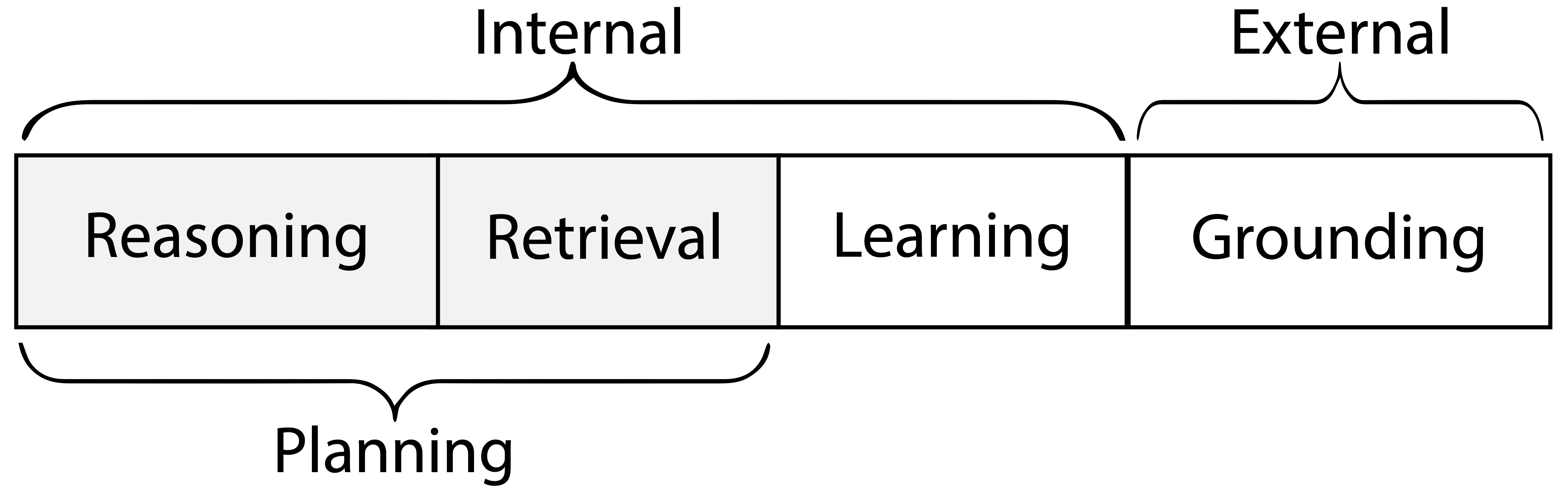
Coala gibt einen Sprachagenten genau an, der mit seinem Aktionsraum mit 2 Teilen beginnt:
- Externe Aktionen zur Interaktion mit externen Umgebungen ( Erdung )
- Interne Handlungen zur Interaktion mit internen Erinnerungen ( Argumentation , Abrufen , Lernen )
- Ein Sprachagent hat ein kurzfristiges Arbeitsgedächtnis und mehrere (optionale) langfristige Erinnerungen (episodisch für Erfahrung, Semantik für Wissen, Verfahren für Code/LLM)
- Argumentation = Arbeitsspeicher aktualisieren (mit LLM)
- Abrufen = Langzeitgedächtnis lesen
- Lernen = Langzeitgedächtnis schreiben
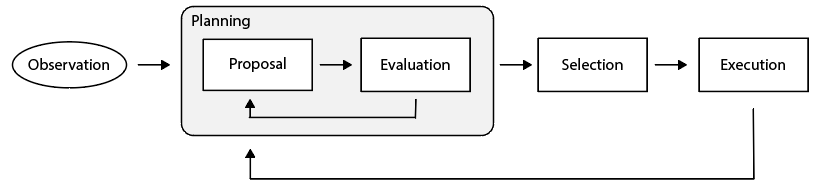
Wie wählt ein Sprachagenten dann aus, welche Aktion zu ergreifen ist? Seine Handlungen werden in Entscheidungszyklen eingebaut, und jeder Zyklus hat zwei Phasen:
- Planung : Der Agent wendet Arguming-/Abrufaktionen an, um (iterativ) Maßnahmen vorzuschlagen und zu bewerten und dann eine Lern-/Erdungsaktion auszuwählen.
- Ausführung : Die ausgewählte Lern-/Erdungsaktion wird ausgeführt, um das interne Gedächtnis oder die externe Welt zu beeinflussen.
Um mehr zu verstehen, lesen Sie Abschnitt 4 unseres Papiers.
Papiere
Im Folgenden finden Sie nur eine Untergruppe von Papieren, die von Coala.bib plus gezogene Anforderungen mit potenziell falschen Aktionsraumetiketten abgeschafft wurden. Datum basiert auf Arxiv v1. Sie repräsentieren nicht alle Arbeiten der Sprachagent, und wir planen, bald weitere Arbeiten hinzuzufügen (Zugangsanfragen willkommen) und haben Etiketten für hoch zitierte Arbeiten.
- (2021-10) AI-Ketten: transparente und kontrollierbare Human-AI-Interaktion durch Erkettung von großsprachigen Modellaufforderungen (Argumentation)
- (2021-10) SILG: Die multi-umgebende symbolische interaktive Sprache Erdungsbenchmark (Umgebung)
- (2022-01) Sprachmodelle als Null-Shot-Planer: Extrahieren umsetzbarer Wissen für verkörperte Wirkstoffe (Erdung)
- (2022-03) promptChainer: Das Anketten von großsprachigen Modellaufforderungen durch visuelle Programmierung (Erdung)
- (2022-03) Scienceworld: Ist Ihr Agent schlauer als ein Fünftklässler? (Umfeld)
- (2022-04) tun, wie ich kann, nicht wie ich sage: Erdungssprache bei Roboter-Gewähren (Erdung)
- (2022-04) Sokratische Modelle: Komponieren von multimodalem Argumentieren von Zero-Shot mit Sprache (Erdung)
- (2022-07) WebShop: Auf dem Weg zu skalierbarer realer Webinteraktion mit fundierten Sprachagenten (Umgebung)
- (2022-09) Progprompt: Generierung von Roboter-Taskplänen mit großer Sprachmodellen (Erdung)
- (2022-10) Zersetzte Aufforderung: Ein modularer Ansatz zum Lösen komplexer Aufgaben (Argumentation)
- (2022-10) Mind's Auge: Geerdete Sprachmodell-Argumentation durch Simulation (Erdung)
- (2022-10) Reagieren: Synergisierung von Argumentation und Handeln in Sprachmodellen (Erdung, Argumentation)
- (2022-11) Große Sprachmodelle sind Einheitliche Ingenieure auf menschlicher Ebene (Argumentation)
- (2022-12) LLM-Planner: Wenige Schuss-geerdete Planung für verkörperte Wirkstoffe mit großen Sprachmodellen (Erdung)
- (2022-12) Erzeugen Sie nicht, diskriminieren Sie: Ein Vorschlag für die Erdungssprachmodelle für Umgebungen in realer Welt (Erdung)
- (2023-02) Die Kette der Hintersicht richtet Sprachmodelle mit Feedback (Lernen) aus
- (2023-02) Beschreiben, Erklären, Planen und Auswählen: Interaktive Planung mit großsprachigen Modellen ermöglicht Open-World Multi-Task-Agenten (Erdung, Argumentation)
- (2023-02) Toolformer: Sprachmodelle können sich selbst beibringen, Tools (Erdung) zu verwenden
- (2023-03) Foundation-Modelle für Entscheidungsfindung: Probleme, Methoden und Chancen (Umfrage)
- (2023-03) Hugginggpt: Lösen von KI-Aufgaben mit Chatgpt und seinen Freunden im Umarmungsgesicht (Erdung)
- (2023-03) Palm-E: Ein verkörpertes multimodales Sprachmodell (Erdung)
- (2023-03) Reflexion: Sprachmittel mit verbalem Verstärkungslernen (Erdung, Argumentation, Lernen)
- (2023-03) Selbstrefine: iterative Verfeinerung mit Selbstversorgungsback (Argumentation)
- (2023-03) Selbstplanungscodeerzeugung mit großsprachigen Modellen (Argumentation)
- (2023-04) Generative Agents: Interaktive Simulacra des menschlichen Verhaltens (Erdung, Argumentation, Abruf, Lernen)
- (2023-04) Emergent autonome wissenschaftliche Forschungsfähigkeiten großer Sprachmodelle (Erdung, Argumentation)
- (2023-04) LLM+P: Ermächtigung großer Sprachmodelle mit optimalen Planungskenntnissen (Erdung, Argumentation)
- (2023-04) Raffiner: Argumentation Feedback zu Zwischendarstellungen (Argumentation)
- (2023-04) Lehren großer Sprachmodelle für Selbstentwicklung (Argumentation)
- (2023-04) Genegpt: Erweiterung großer Sprachmodelle mit Domänenwerkzeugen für einen verbesserten Zugang zu biomedizinischen Informationen (Erdung, Argumentation)
- (2023-05) Kritiker: Große Sprachmodelle können sich mit Werkzeuginteraktiven kritisieren (Erdung, Argumentation, Abruf)
- .
- (2023-05) CHATCOT: Tool-ausgelöste Argumentation auf Chat-basierte Großsprachenmodelle (Erdung, Argumentation)
- (2023-05) Toolkengpt: Erweiterung gefrorener Sprachmodelle mit massiven Werkzeugen über Tool-Einbettungen (Erdung, Argumentation)
- (2023-05) Die Zersetzung verbessert das Denken durch Selbstbewertungs-Dekodierung (Argumentation)
- (2023-05) Ermutigen divergentes Denken in großen Sprachmodellen durch Multi-Agent-Debatte (Erdung, Argumentation)
- (2023-05) Verbesserung der Tatsache und des Denkens in Sprachmodellen durch Multiagent-Debatten (Erdung, Argumentation)
- (2023-05) Adaplanner: Adaptive Planung aus Feedback mit Sprachmodellen (Erdung, Abruf, Lernen)
- (2023-05) Plan-und-Solve-Aufforderung: Verbesserung der Überlegungen zur Kette des Null-Shot-Kettens durch große Sprachmodelle (Argumentation)
- (2023-05) Rewoo: Entkopplung von Argumentation aus Beobachtungen für effiziente erweiterte Sprachmodelle (Erdung, Argumentation)
- (2023-05) SwiftSage: Ein generatives Mittel mit schnellem und langsamem Denken für komplexe interaktive Aufgaben (Erdung, Argumentation)
- (2023-05) Baumbaum: Absichtliche Problemlösung mit großen Sprachmodellen (Argumentation)
- (2023-05) Voyager: Ein offenes verkörpertes Wirkstoff mit großen Sprachmodellen (Erdung, Argumentation, Abrufen, Lernen)
- (2023-06) Intercode: Standardisierende und Benchmarking interaktiver Codierung mit Ausführungsfeedback (Erdung, Argumentation)
- (2023-06) Toolqa: Ein Datensatz für LLM-Frage, die mit externen Tools beantwortet werden (Erdung)
- (2023-06) Mind2Web: Auf dem Weg zu einem Generalistischen Agenten für das Web (Umgebung)
- (2023-06) RESTGPT: Verbinden von großsprachigen Modellen mit realer Rastful-APIs (Erdung, Argumentation)
- (2023-06) Toolalpaca: Generalisiertes Werkzeuglernen für Sprachmodelle mit 3000 simulierten Fällen (Erdung, Argumentation)
- (2023-07) Ein reales Webagent mit Planung, langem Kontextverständnis und Programmsynthese (Erdung, Argumentation)
- (2023-07) RT-2: Vision-Sprach-Action-Modelle übertragen Webwissen auf Roboterkontrolle (Erdung)
- (2023-07) ROCO: Dialektische Multi-Robot-Zusammenarbeit mit großsprachigen Modellen (Erdung)
- (2023-07) Roboter, die um Hilfe bitten: Unsicherheitsausrichtung für Großsprachmodellplaner (Erdung)
- (2023-07) S $^3 $: Social-Network-Simulationssystem mit großsprachigen Modellverminderungen (Erdung, Argumentation)
- (2023-07) Toolllm: Erleichterung großer Sprachmodelle, um 16000+ reale APIs (Erdung, Argumentation, Abruf) zu beherrschen
- (2023-07) Verständnis der Vorteile und Herausforderungen bei der Verwendung modellbasierter Konversationsmittel in großer Sprache für die Unterstützung des geistigen Wohlbefindens (Erdung)
- (2023-07) Kognitive Synergie in Großsprachenmodellen auszutrieren: Ein Aufgabenlösungsmittel durch Selbstkollaboration mit mehreren Personen (Erdung, Argumentation)
- (2023-07) Webarena: Eine realistische Webumgebung zum Aufbau autonomer Agenten (Umwelt)
- (2023-08) Agentbench: Bewertung von LLMs als Wirkstoffe (Umgebung)
- (2023-08) Agentverse: Erleichterung der Zusammenarbeit mit mehreren Agenten und Erforschung neuer Verhaltensweisen in Agenten (Umwelt)
- (2023-08) Autogen: Aktivierung von LLM-Anwendungen der nächsten Generation über ein Multi-Agent-Konversationsrahmen (Erdung, Argumentation)
- (2023-08) CGMI: Konfigurierbares allgemeines Interaktionsgerüst mit mehreren Agenten (Erdung, Argumentation)
- (2023-08) Chateval: Auf dem Weg zu besseren LLM-basierten Evaluatoren durch Multi-Agent-Debatte (Erdung, Argumentation)
- (2023-08) Kumulatives Denken mit großen Sprachmodellen (Argumentation)
- (2023-08) Expel: LLM-Wirkstoffe sind experimentelle Lernende (Erdung, Argumentation, Abruf, Lernen)
- (2023-08) GPT-in-the-Loop: Anpassungsfähige Entscheidungsfindung für Multiagent-Systeme (Erdung, Argumentation)
- (2023-08) Gentopia: Eine kollaborative Plattform für Tool-Alt-LLMs (Umgebung)
- (2023-08) Metagpt: Meta-Programmierung für kollaborative Multi-Agent-Rahmenwerte (Erdung, Argumentation)
- (2023-08) Proagent: Aufbau einer proaktiven kooperativen KI mit Großsprachmodellen (Erdung, Argumentation)
- (2023-08) RetroFormer: Retrospektive große Sprachmittel mit politischer Gradientenoptimierung (Erdung, Argumentation, Lernen)
- (2023-08) SAPIEN: affektive virtuelle Agenten, die von Großsprachenmodellen (Erdung, Argumentation) angetrieben werden
- (2023-08) Synergistische Integration großer Sprachmodelle und kognitiver Architekturen für robuste KI: Eine explorative Analyse (Erdung, Argumentation, Abruf, Lernen)
- (2023-09) Tora: Ein mit Werkzeug integriertes Argumentationsmittel für die mathematische Problemlösung (Erdung, Argumentation, Lernen)
- (2023-09) Identifizieren der Risiken von LM-Wirkstoffen mit einer LM-emulierten Sandbox (Umgebung)
- (2023-09) Verdacht Agent: Unvollkommene Informationsspiele mit Theory of Mind Awes GPT-4 (Erdung, Argumentation) spielen
- (2024-01) Selbstkontrast: Bessere Reflexion durch inkonsistente Lösungsperspektiven (Argumentation, Reflexion)
- (2024-02) Agent-Pro: Lernen, sich durch Reflexion und Optimierung auf Politikebene zu entwickeln (Argumentation, Reflexion, Lernen)
- (2024-03) LLM3: Großsprachige modellbasierte Aufgabe und Bewegungsplanung mit Bewegungsversagen. (Planung, Argumentation)
- (2024-04) Ermächtigung der biomedizinischen Entdeckung mit KI-Agenten (AI-Wissenschaftler, Biomedizinische Forschung)
- (2024-05) Timechara: Bewertung der Halluzination von Rollenspielen mit großer Sprachmodelle (Argumentation, Abruf)
(Weitere bald hinzugefügt werden. Anfrage willkommen.)
Ressourcen
- Autonome Agenten von LLM betrieben (Lil'log)
- LLM-Agents-Papiere
- Llmagentpaper
- Awesome-llm-Anbieter-Agent
(Weitere bald hinzugefügt werden. Anfrage willkommen.)


