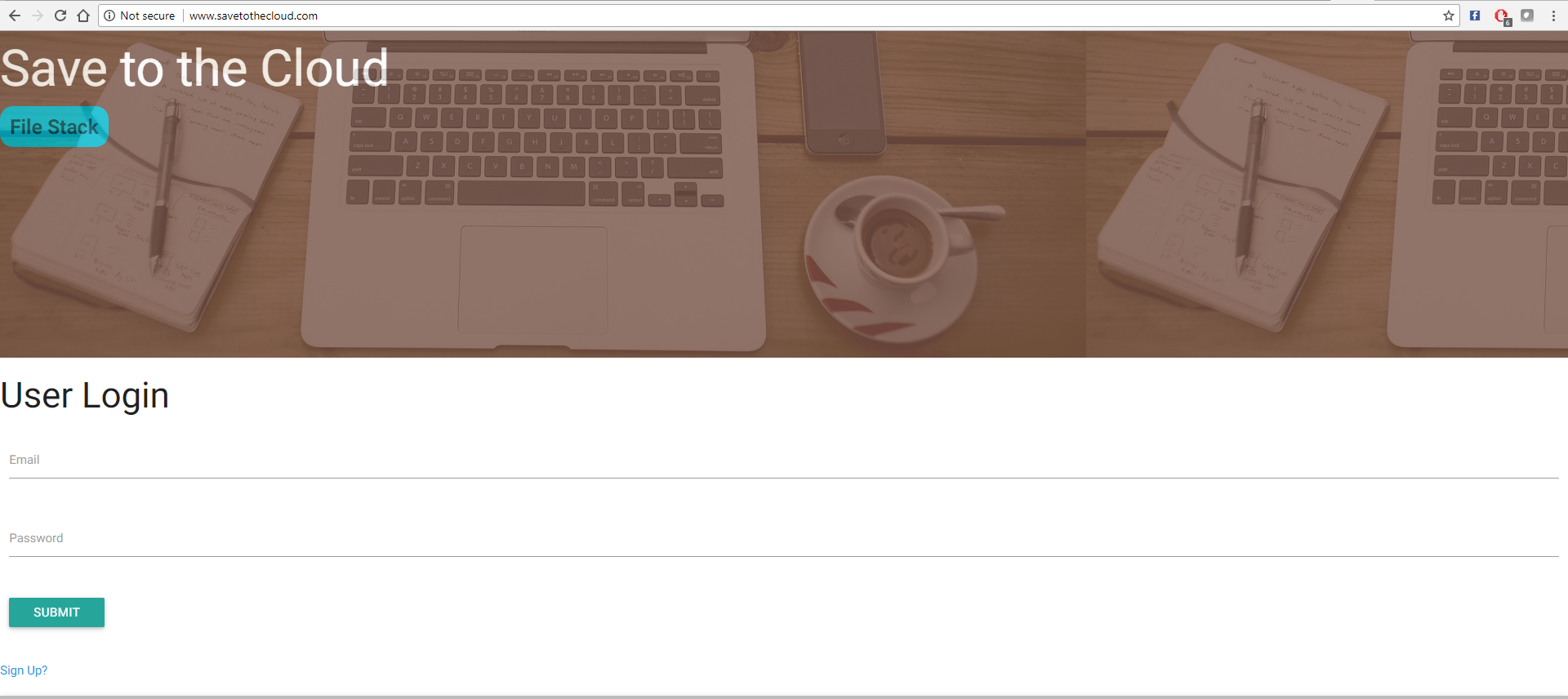
Auf der Cloud speichern
URL: http://www.savetothecloud.com/
EINFÜHRUNG
Name der Universität: http://www.sjsu.edu/
Kurs: Cloud -Technologien
Professor: Sanjay Garje
Isa: Divyanthika Urs
Student: Anuradha Rajashekar
Projektidee
- 'Save to the Cloud' ist eine vollständige Stack -Webanwendung, die hauptsächlich mit dem Speichern und Speichern von Dateien durch Nutzung der Cloud -Infrastruktur befasst.
- Diese Anwendung konzentriert sich auf CRUD -Operationen auf alle Dateien, die vom Benutzer hochgeladen werden.
- Das Hauptziel dieses Projekts war es, den Dateistapel zu optimieren, indem sie API zum Hochladen, Abrufen, Löschen und Speichern von Dateien in S3 und zur Beschleunigung von Geschwindigkeit und Leistung verwenden.
- Mit dieser Bewerbung können Sie ein privates Konto für alle Ihre Dateispeicher haben und darauf zugreifen, wann immer es erforderlich ist. .
Funktionen dieser Anwendung
Speichern in der Cloud kann über den Domain -Namen zugegriffen werden: http://www.savetothecloud.com. Kompatibel sowohl in Desktop als auch in Smartphones.
Die Liste der von der Anwendung bereitgestellten Funktionen lautet wie folgt:
Anmeldeseite: Damit ein neuer Benutzer alle relevanten Informationen eingibt, die in der Datenbank gesammelt und gespeichert werden.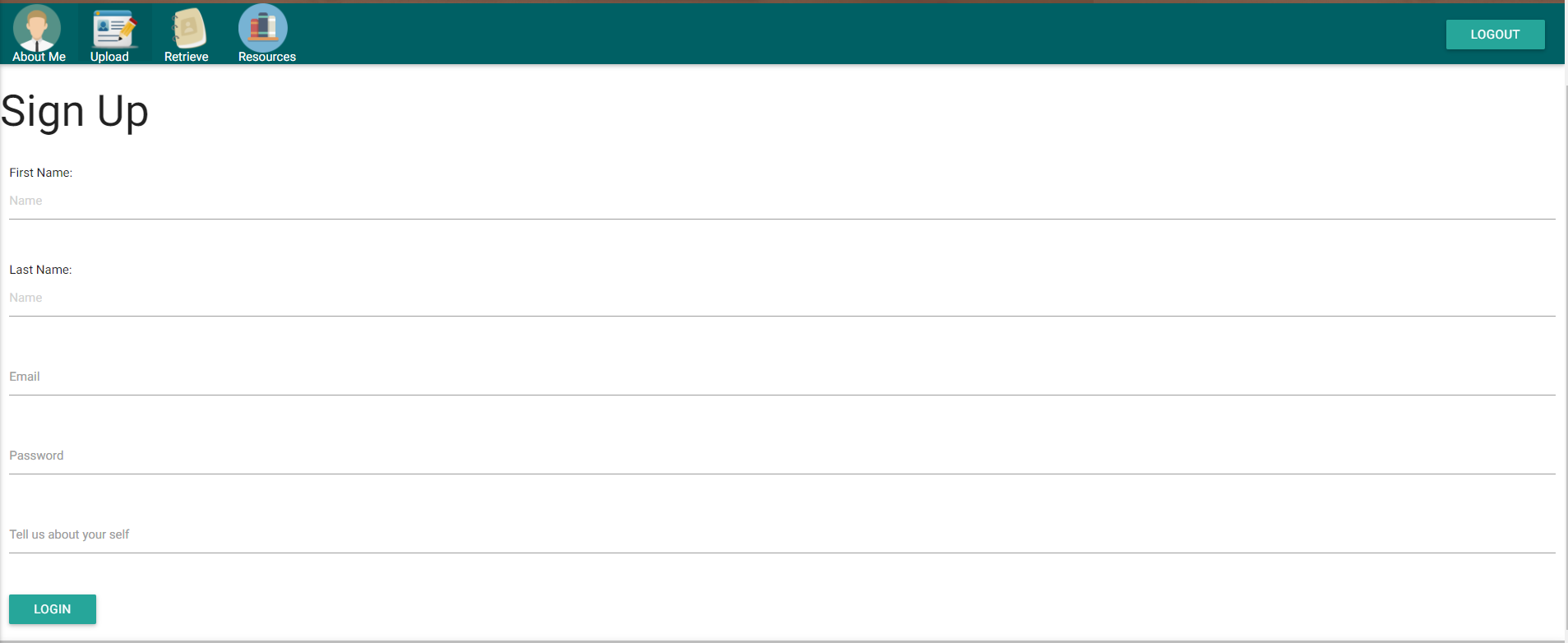
Anmeldeseite: Damit ein vorhandener Benutzer sich mit verfügbaren Anmeldeinformationen anmelden und auf die Anwendung zugreift.
Über mich Seite: Benutzerdetails, allgemeine Hobbys und Details zum Benutzer. 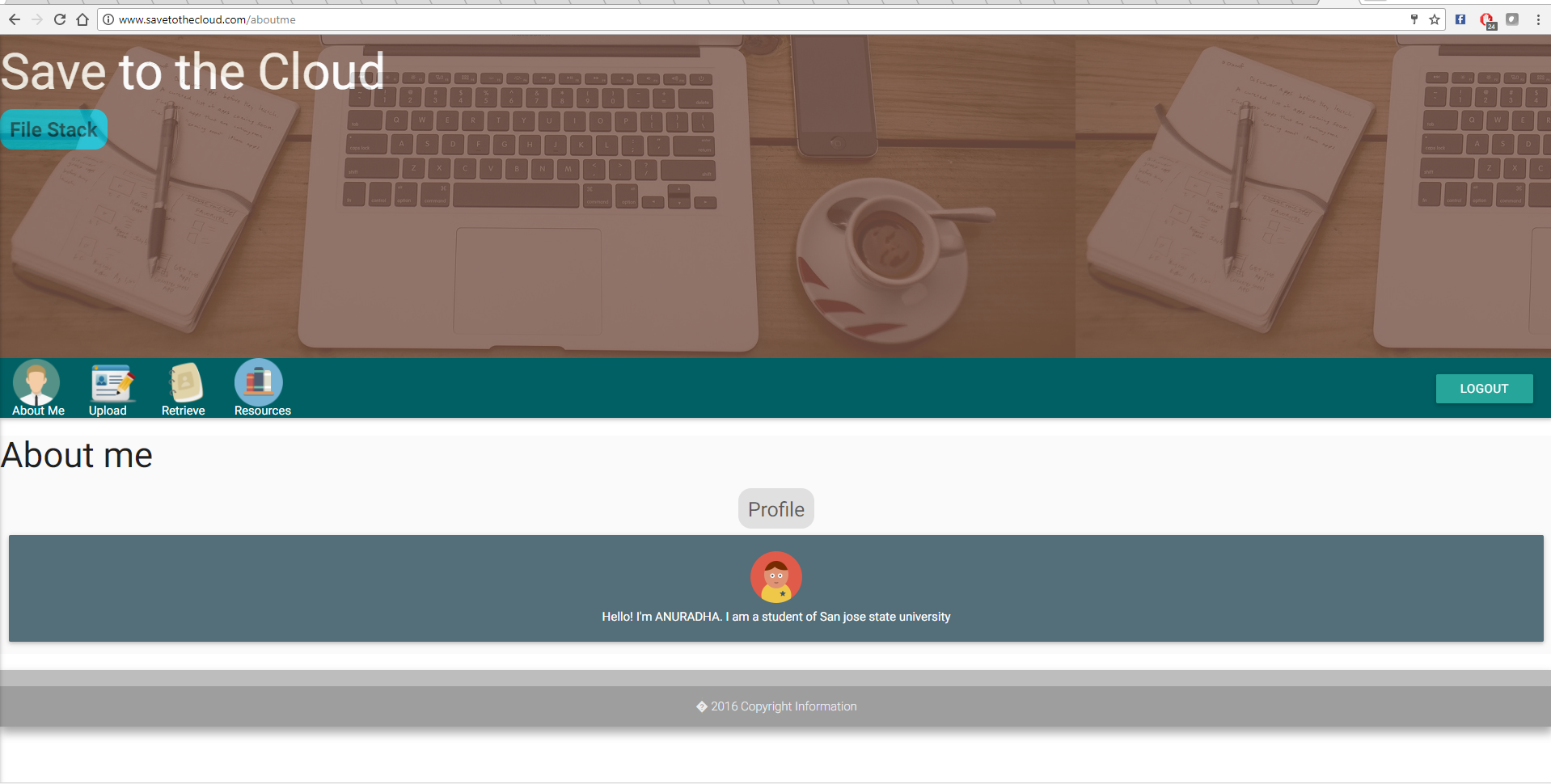
Option hochladen: Damit der Benutzer Dateien für den Speicher in Amazon S3 hochladen kann. 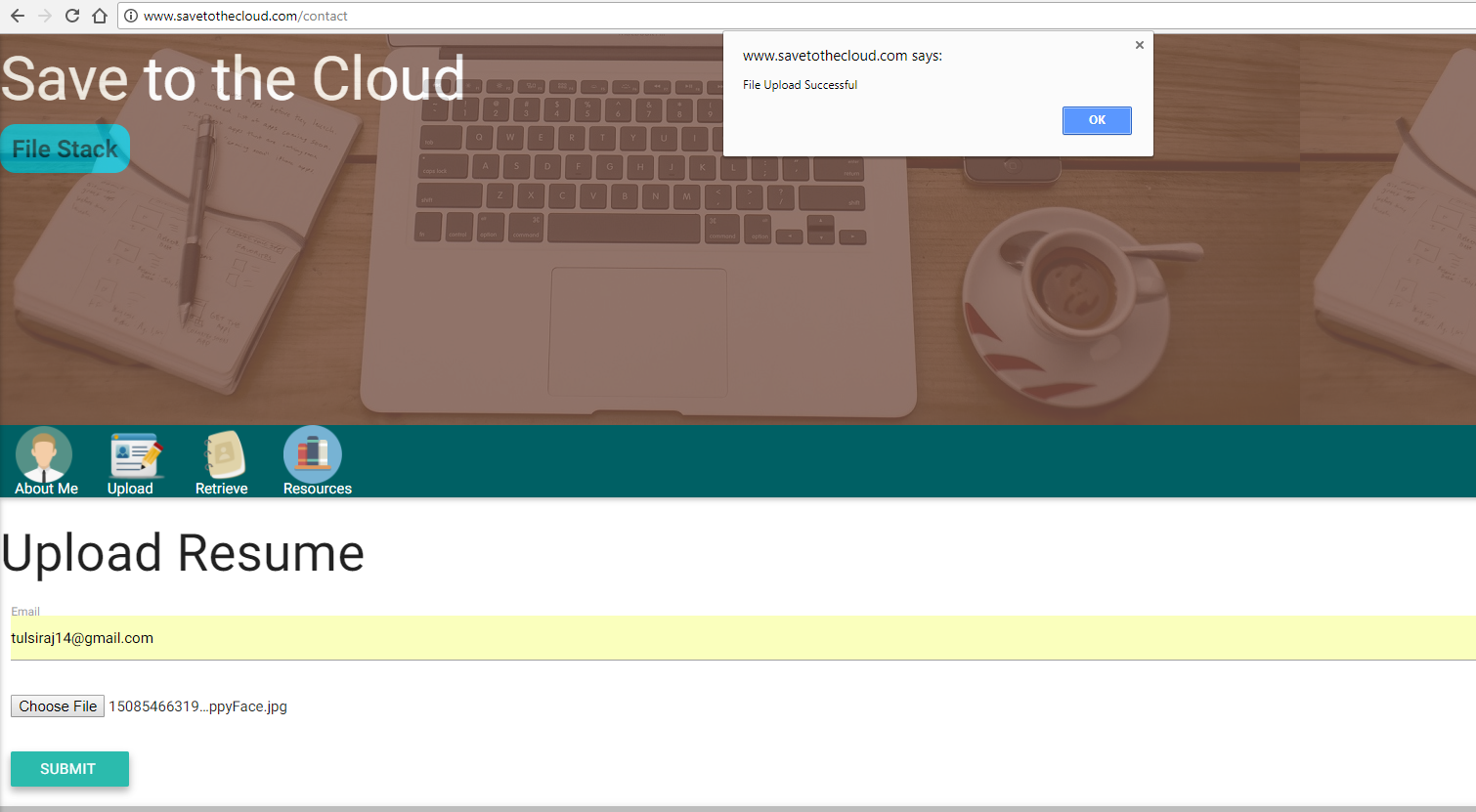
Abrufen Sie alle Dateien Option ab: So abrufen, um zuvor hochgeladene Dateien abzurufen
Option löschen: Zum Löschen von Dateien, die vom Benutzer nicht mehr erforderlich sind.
Option Update: So aktualisieren Sie bereits hochgeladene Dateien. In der Anwendung werden Benutzer so weitergeleitet, dass neue Dateien mit dem Update / Revision erneut hochgeladen werden.
Die Anwendung zeigt Folgendes auf der Seite 'Abruf' an.
• Vorname des Benutzers
• Nachname des Benutzers
• Datei -Upload -Zeit
• Dateiname/ Beschreibung
• Dateiaktualisierungszeit 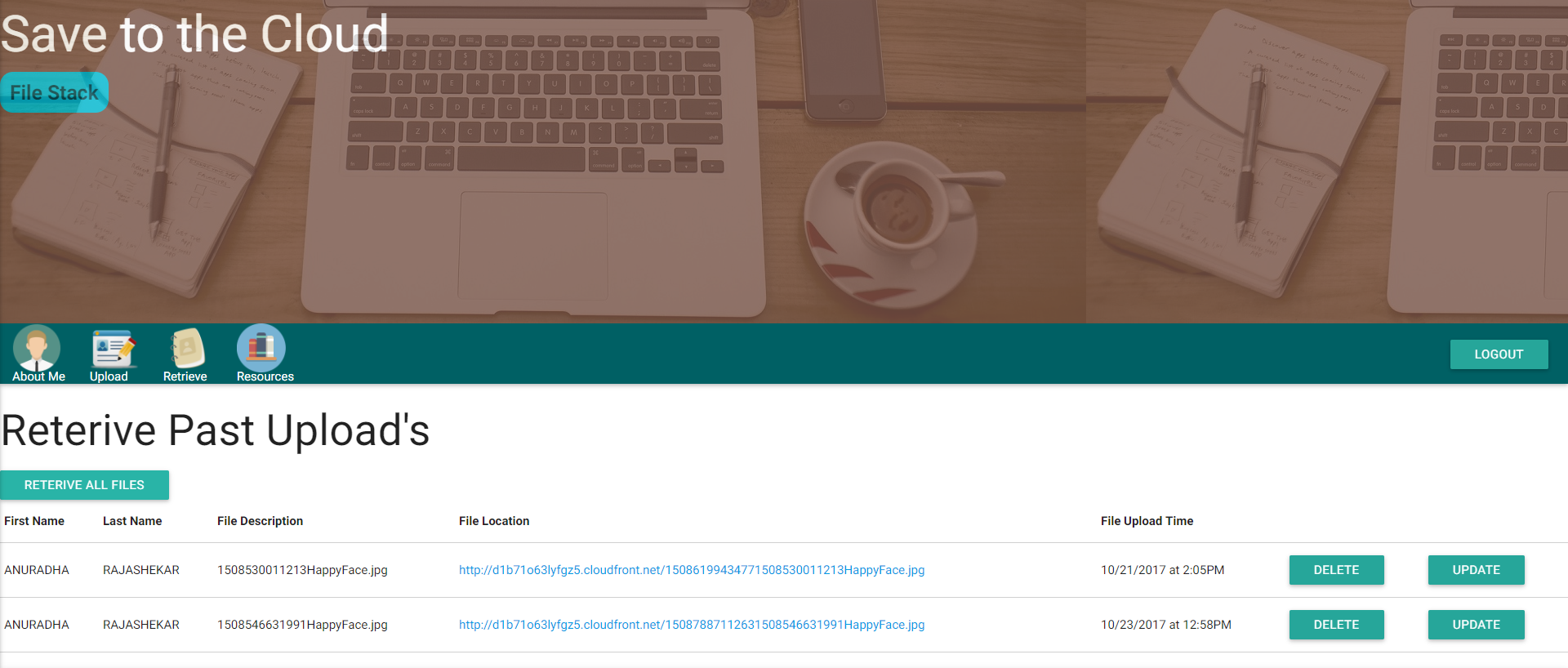
Ressourcenseite: Der Benutzer finden Links zu allen in dieser Anwendung verwendeten Technologie. 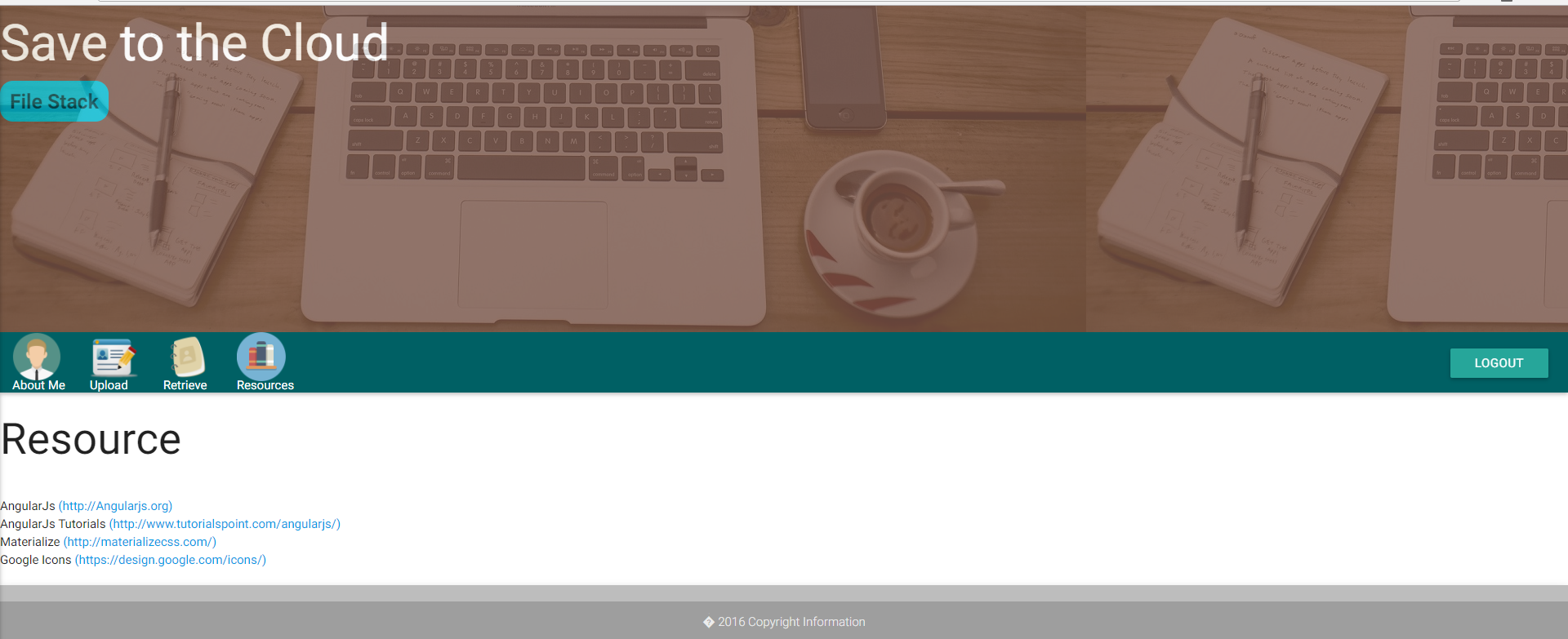
Link zu Benutzern Facebook, LinkedIn, Google Mail und einem anderen Social -Media -Konto in einem Klick entfernt. 
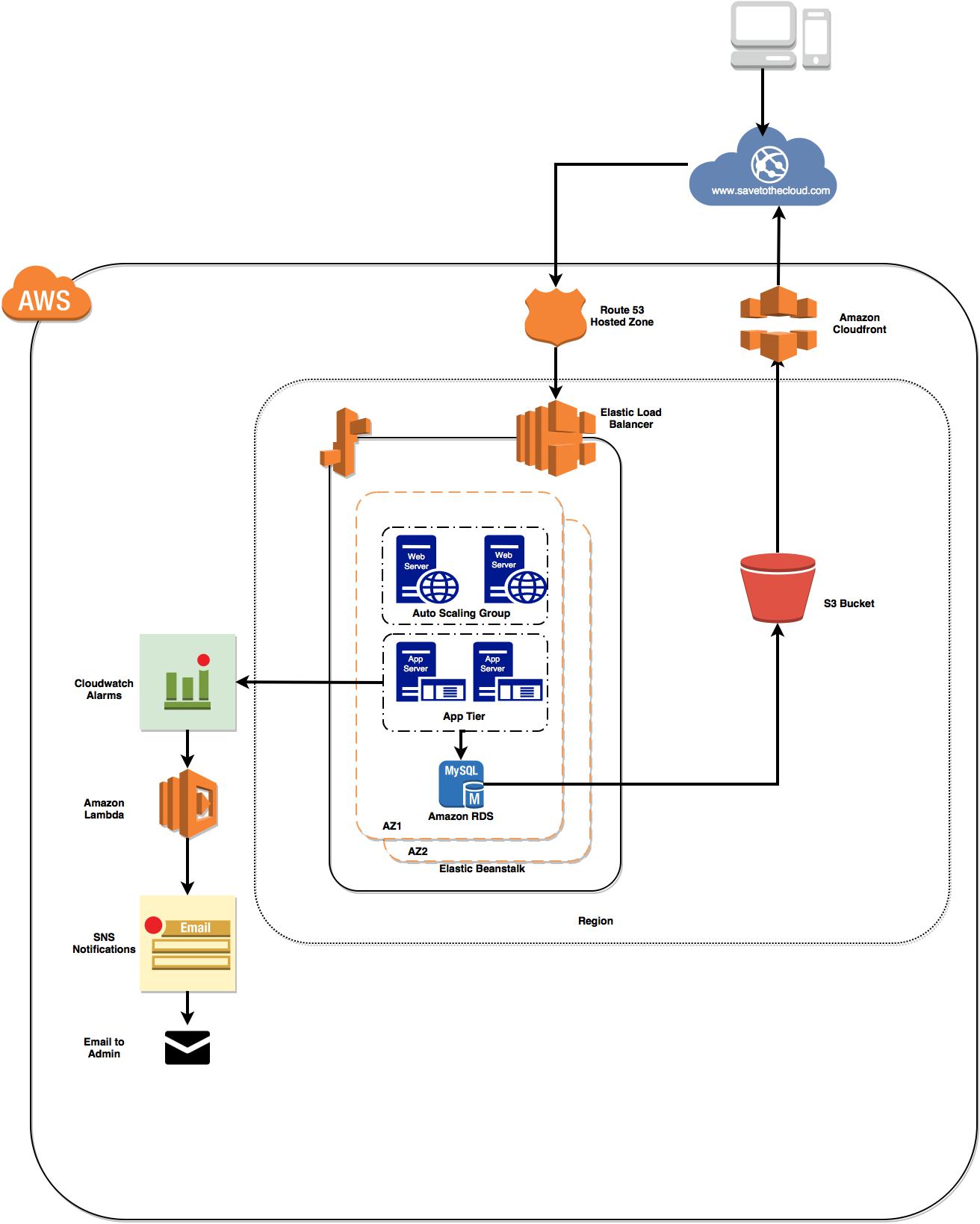
Architektur Digram für dieses Projekt
Voraussetzungen:
- Erstellen Sie ein Amazon -Konto und navigieren Sie zur Konsole in Amazon AWS.
- Erstellen Sie einen Eimer in S3 und laden Sie Dateien hoch und überprüfen Sie die Konfiguration in S3 und setzen Sie den Lebenszyklus (S3-> S3IA-> Gletscher).
- Verknüpfen Sie Ihren S3 -Bucket mit CloudFront, um den Datenverkehr auf S3 -Bucket zu laden.
- Diese Anwendung wird in der elastischen Beanstalk -Umgebung eingesetzt, in der sie eine Umgebung durch Auslösen von EC2 -Instanz, automatische Skalierungsgruppe erstellt, um die Verfügbarkeit während des Ausfalls und den elastischen Lastausgleich aufrechtzuerhalten, um sicherzustellen, dass die Last für Instanzen und Amazon RDS (MySQL) als Datenbank verteilt ist.
- Cloud Watch Alarme werden so eingestellt, dass sie einen gesunden Status der Instanzen überprüfen.
- Lambda -Funktion zu Empfänger -Cloud -Uhren -Warnungen und senden Sie die Benachrichtigung an den Benutzer über das Ereignis.
- Weitere Informationen zu jeder Konfiguration finden Sie unter (https://aws.amazon.com/documentation/).
Liste der erforderlichen Software:
- Frontend: Angular JS, Materialise (Modell, Ansicht, Controller Java -Skript)
- Serverseite: Knoten JS, Express JS, Multer, AWS-SDK
- Datenbank: Amazon RDS (MySQL)
- Amazon Cloud Infrastructure (Elastic Beaderstalk, CloudWatch, SNS, Lambda usw.)
FRONTEND-
- Angular JS (Modell, Ansicht, Controller) und Materialise werden für das Frontend verwendet. CSS wird für die schicke Strukturierung der Benutzeroberfläche verwendet.
Serverseite-
- NodeJs und ExpressJs werden für die Back-End-Funktionalität zusammen mit AWS-SDK für verschiedene Funktionen wie PutObject, GetObject, ListObject usw. in S3 verwendet.
DATENBANK-
- Die MySQL Relational Database wird zum Speichern und Abrufen von Benutzerdaten verwendet. Dieser Service erhält meine Amazon RDS als PaaS.
- "Tabellen" werden in der Datenbank erstellt, um User FirstName, LastName und andere Datensätze zu verfolgen.
Anweisungen zum lokalen Einrichten von Projekten:
- Klonen Sie das obige Projekt in Ihr lokales Repository (Clone-Link: https: //github.com/anuradhaiyer/aws-cloud-project.git)
- Gehen Sie in den Ordner, in dem das Projekt kloniert wird, und prüfen Sie, ob alle Abhängigkeiten für das Projekt erwähnt werden.
- Installieren Sie Node.js in Ihrem System. Link für Iinstalling- (https://nodejs.org/en/).
- Wir haben "AWS-SDK" für den Zugriff auf S3 von Amazon aufgenommen. Bitte fügen Sie diese als Abhängigkeit in Paket.json-Datei hinzu.
- Server.js enthält die Backend/Server -Seitenlogik in dieser Anwendung.
- Die Funktionalität der Frontend ist in Angular JS geschrieben (siehe Ordner "Ansichten" im obigen Verbot)
- Um dieses Projekt auszuführen, gehen Sie zum Ordner, in dem Dateien für dieses Projekt verfügbar sind-> Gitbash/CMD-> "NPM Install" ausführen, um alle Knotenmodule lokal zu installieren. Geben Sie den Befehl "Knotenserver JS" ein, um den Server zu starten. Die Anwendung wird in dem im Code erwähnten dargestellt. Ex: "Localhost: 8081/"
- Verwenden Sie Sublime oder Notepad ++ zum Bearbeiten von Code und starten Sie den Server nach der Bearbeitung.


