atomgrad
1.0.0

Atomgrad هو محرك ذاتي بسيط يهدف إلى أن يكون بين Micrograd و Tinygrad الذي يؤدي التلقائي على الموترات ذات القيمة المتجهة والقياس (الذرات) إلى جانب مكتبة واجهة برمجة تطبيقات الشبكة العصبية.
sum ، exp ، reshape ، randint ، uniform ، etc).relu ، sigmoid ، tanh ، إلخ.binary_cross_entropy & binary_accuracy .يمكنك تثبيت Atomgrad باستخدام PIP:
pip install atomgrad==0.3.0فيما يلي مثال بسيط على استخدام Atomgrad لحساب تدرج الوظيفة:
from atomgrad . atom import Atom
from atomgrad . graph import draw_dot
# create two tensors with gradients enabled
x = Atom ( 2.0 , requires_grad = True )
y = Atom ( 3.0 , requires_grad = True )
# define a function
z = x * y + x ** 2
# compute the backward pass
z . backward ()
# print the gradients
print ( x . grad ) # 7.0
print ( y . grad ) # 2.0
draw_dot ( z )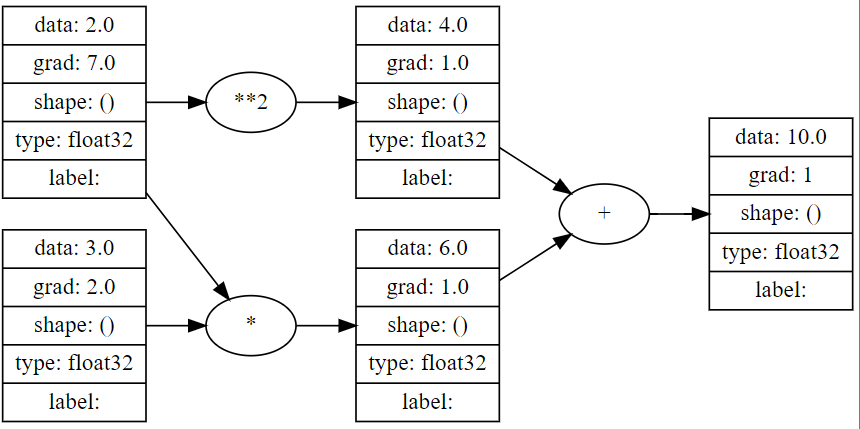
فيما يلي مثال بسيط على استخدام Atomgrad لتدريب شبكة عصبية مخفية من 16 عقدة لتصنيف ثنائي.
import numpy as np
from atomgrad . atom import Atom
from atomgrad . nn import AtomNet , Layer
from atomgrad . optim import SGD
from atomgrad . metrics import binary_cross_entropy , binary_accuracy
# create a model
model = AtomNet (
Layer ( 2 , 16 ),
Layer ( 16 , 16 ),
Layer ( 16 , 1 )
)
# create an optimizer
optim = SGD ( model . parameters (), lr = 0.01 )
# load some data
x = [[ 2.0 , 3.0 , - 1.0 ],
[ 3.0 , - 1.0 , 0.5 ],
[ 0.5 , 1.0 , 1.0 ],
[ 1.0 , 1.0 , - 1.0 ],
[ 0.0 , 4.0 , 0.5 ],
[ 3.0 , - 1.0 , 0.5 ]]
y = [ 1 , 1 , 0 , 1 , 0 , 1 ]
x = Atom ( x )
y = Atom ( y )
model . fit ( x , y , optim , binary_cross_entropy , binary_accuracy , epochs = 100 )
#output
'''
...
epoch: 30 | loss: 0.14601783454418182 | accuracy: 100.0%
epoch: 35 | loss: 0.11600304394960403 | accuracy: 100.0%
epoch: 40 | loss: 0.09604986757040024 | accuracy: 100.0%
epoch: 45 | loss: 0.0816292017698288 | accuracy: 100.0%
''' مثال على Autodiff البسيط وأربعة مصنفات ثنائية بما في ذلك مجموعة بيانات make_moons و Mnist Digits Dataset في دفتر examples/demos.ipynb .
ملاحظة: على الرغم من أن atom.nn يتضمن تنشيط softmax و cat_cross_entropy ، فإن نتائج النماذج تنفذ تمامًا ومن المحتمل أن تكون بسبب بعض الأخطاء (PLZ LMK إذا وجدت!). نتيجة لذلك ، يكون نموذج AtomNet أكثر ملاءمة للمهام الصافية العصبية للتصنيف الثنائي.


