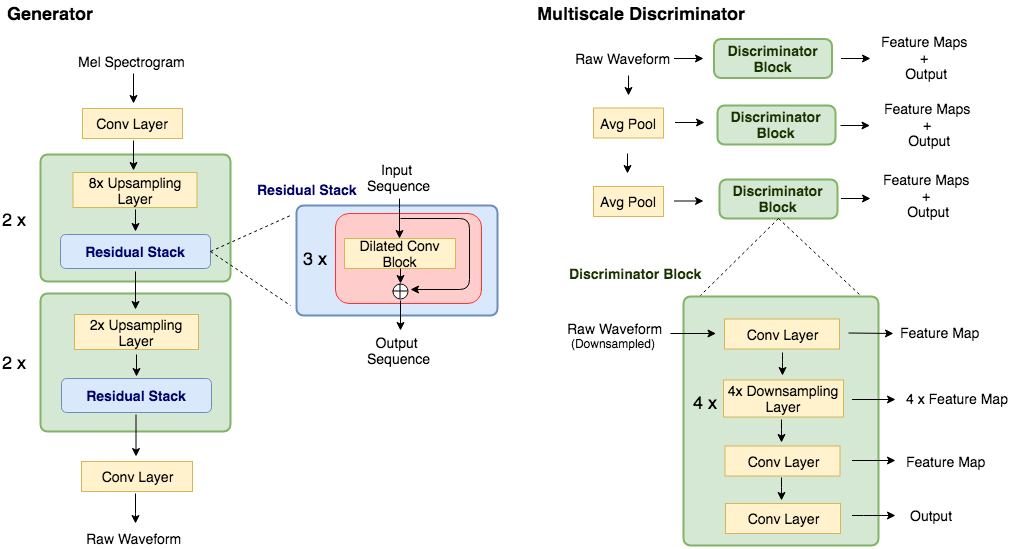
melgan
voiced segment (fix #30, #17)
梅爾根聲碼器的非正式Pytorch實施
在Python 3.6上測試
pip install -r requirements.txtpython preprocess.py -c config/default.yaml -d [data's root path]yaml文件python trainer.py -c [config yaml file] -n [name of the run]cp config/default.yaml config/config.yaml ,然後編輯config.yaml*.mel文件的*.wav對。tensorboard --logdir logs/ 嘗試Google Colab:todo
import torch
vocoder = torch . hub . load ( 'seungwonpark/melgan' , 'melgan' )
vocoder . eval ()
mel = torch . randn ( 1 , 80 , 234 ) # use your own mel-spectrogram here
if torch . cuda . is_available ():
vocoder = vocoder . cuda ()
mel = mel . cuda ()
with torch . no_grad ():
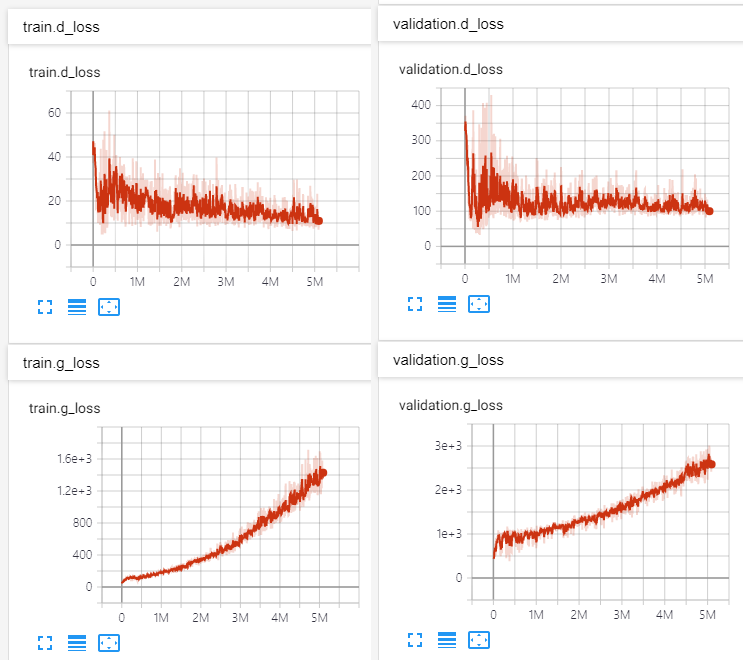
audio = vocoder . inference ( mel )python inference.py -p [checkpoint path] -i [input mel path] 請參閱以下網址:http://swpark.me/melgan/。使用LJSpeech-1.1在V100 GPU進行了14天的培訓。
BSD 3條規定許可證。


