melgan
voiced segment (fix #30, #17)
Melgan Vocoder의 비공식 Pytorch 구현
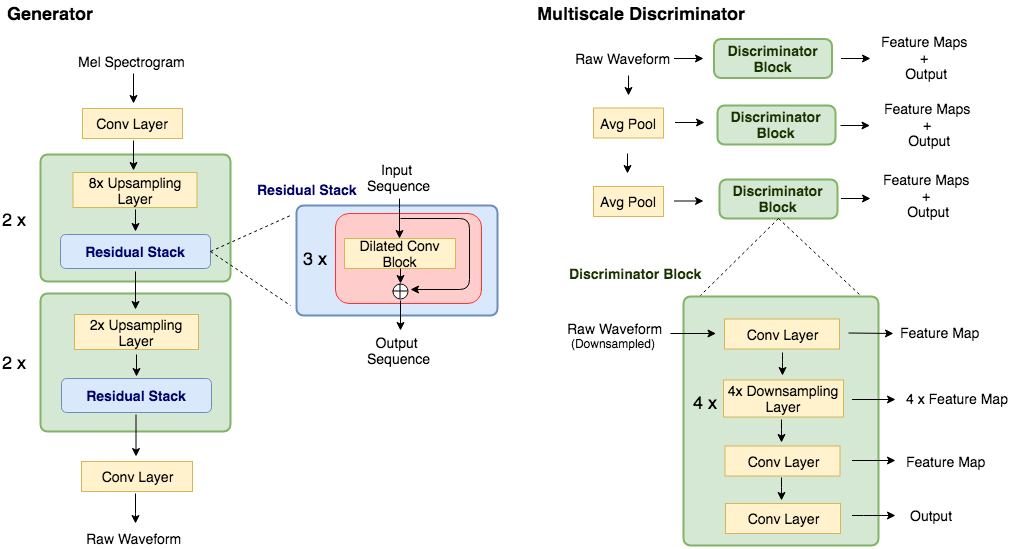
파이썬 3.6에서 테스트
pip install -r requirements.txtpython preprocess.py -c config/default.yaml -d [data's root path]yaml 파일 편집 python trainer.py -c [config yaml file] -n [name of the run]cp config/default.yaml config/config.yaml 다음 config.yaml 편집하십시오*.mel 파일이있는 *.wav 쌍이 포함되어야합니다.tensorboard --logdir logs/ Google Colab : Todo와 함께 사용해보십시오
import torch
vocoder = torch . hub . load ( 'seungwonpark/melgan' , 'melgan' )
vocoder . eval ()
mel = torch . randn ( 1 , 80 , 234 ) # use your own mel-spectrogram here
if torch . cuda . is_available ():
vocoder = vocoder . cuda ()
mel = mel . cuda ()
with torch . no_grad ():
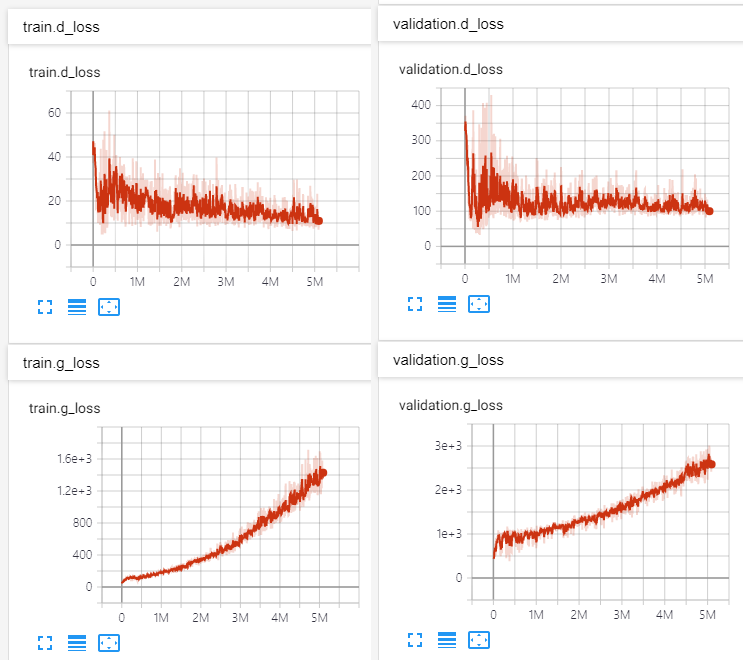
audio = vocoder . inference ( mel )python inference.py -p [checkpoint path] -i [input mel path] http://swpark.me/melgan/에서 오디오 샘플을 참조하십시오. 모델은 LJSPEECH-1.1을 사용하여 14 일 동안 V100 GPU에서 교육을 받았습니다.
BSD 3-Clause 라이센스.


