Fontimize
1.0.0
輕鬆優化(子集)字體僅適用於文本或HTML所需的特定字形!
您是否擔心網站的初始下載尺寸?需要下載的兆字節,並且您已經優化和縮小了CSS,JavaScript和圖像,但是發現了一些大字體?想法是給您的!該工具分析您的HTML文件和CSS(或任何文本),並創建字體子集,僅包含實際使用的字符或字形的字體文件。
實際上,您可以將字體下載尺寸縮小到原始字體的10%或更少。
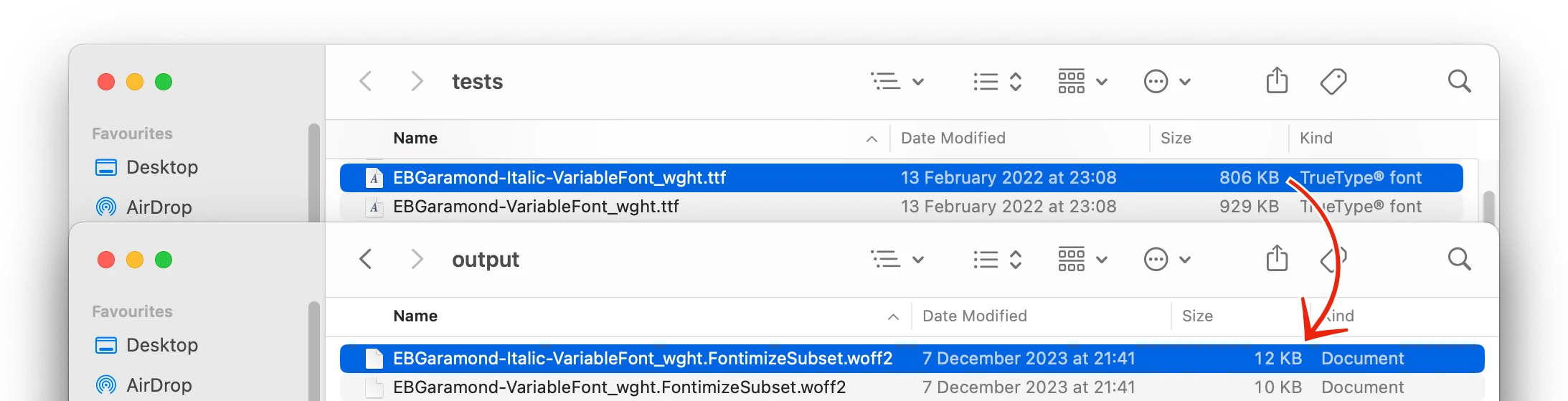
Fontimize使用TTF2Web,非常感謝並感謝該奇妙圖書館的作者。
該圖書館最初是為我的個人網站創建的。它使用了四個TTF字體,總計超過1.5MB。 (這並不罕見:一個用於標題,一個用於帶有斜體變體的普通文本,以及印刷怪癖的第四個,dropcaps。)
直接運行後,所有字體的總尺寸組合為76KB。
1.5MB降至76KB可節省95.2%!這對下載網站上的頁面的初始時間產生了明顯的影響,再加上對渲染的巨大影響:在此之前,該站點的初始負載將使用通用的Serif字體呈現,然後在下載字體後幾秒鐘重新渲染,一旦下載了幾秒鐘,這看起來真的很糟糕。現在,您將立即或在註意到之前立即獲取新字體,並且該站點從一開始就看起來正確。
Fontimize是一個Python庫,可以包含在您的Python軟件中,也可以在命令行上使用的獨立。
首先安裝和導入通知:
$ python3 -m pip install fontimize
在您的腳本中:
import fontimize要在磁盤上解析一組HTML文件以及它們使用的CSS文件,並導出新字體(默認情況下,與原始字體相同的文件夾中)僅包含HTML中使用的字形:
all_html_files = [ 'input/one.html' , 'input/two.html' ]
font_results = fontimize . optimise_fonts_for_files ( all_html_files )
print ( font_results [ "css" ])
# Prints CSS files found used by any of the HTML input files:
# { 'input/main.css',
# 'input/secondary.css' }
print ( font_results [ "fonts" ])
# Prints pairs mapping the old fonts to the new optimised font generated for each. Use this to, eg, rewrite your CSS
# By default exports to the same folder as the input files; use `font_output_dir` to change
# { 'input/fonts/Arial.ttf': 'input/fonts/Arial.FontimizeSubset.woff2',
# 'input/fonts/EB Garamond.ttf': 'input/fonts/EB Garamond.FontimizeSubset.woff2' }
print ( font_results [ "chars" ]
# Prints the set of characters that were found or synthesised that the output fonts will use
# { ',', 'u', '.', '@', 'n', 'a', '_', 'l', 'i', 'h', 'Q', 'y', 'w', 'T', 'q', 'j', ' ', 'p', 'm', 's', 'o', 't', 'c' ... }
print ( font_results [ "uranges" ]
# Prints the same set of characters, formatted as ranges of Unicode characters
# U+0020, U+002C, U+002E, U+0040, U+0051, U+0054, U+005F, U+0061-007A ...optimise_fonts_for_files()這可能是您要使用的方法。
根據磁盤上的一組輸入文件,優化 /子集字體,(自動)任何HTML文件引用的外部CSS文件。如果文件具有.htm或.html文件擴展名(提取用戶可見文本並解釋CSS),則將文件解析為HTML,否則將文件視為文本。返回發現的CSS文件的列表和舊的到新優化字體文件的地圖。
參數:
html_files : list[str] :路徑列表,每個路徑是一個HTML文件。每個都將進行分析。font_output_dir = "" :應放置子集字體的路徑。默認情況下,這是空的( "" ),這意味著在與輸入字體同一位置生成新字體。由於新字體具有不同的名稱(請參見subsetname ,下一個參數),您不會覆蓋輸入字體。沒有檢查子集字體在編寫之前是否已經存在。subsetname = "FontimizeSubset" :優化字體以format OriginalName.FontimizeSubset.woff2重命名。重要的是要將子集字體與所有字形的原始字體區分原始字體。您可以將輸出子集名稱更改為在文件系統上有效的任何其他字符串。verbose : bool = False :如果是True ,請發出有關其發現並正在生成的CSS文件,字體等的診斷信息。print_stats : bool = True :打印輸入字體磁盤上的總尺寸的信息,優化字體的總尺寸,以及節省百分比的信息。如果您希望它靜靜地運行,則將其設置為False 。fonts : list[str] = [] :字體文件的路徑列表。這些被添加到該方法通過CSS找到的任何字體中。如果您傳遞文本文件而不是HTML,通常會指定這一點addtl_text : str = "" :應添加到文件中的其他字符返回:
dict[str, typing.Any]return_value["css"] - > HTML文件使用的唯一CSS文件列表return_value["fonts"] - >一個dict keys()是原始字體文件,每個密鑰的值是生成的替換字體文件。您可以使用它將引用更新到原始字體文件。請注意,Fontimizer不會重寫輸入CSS。return_value["chars"] - >解析輸入時發現的一set字符return_value["uranges] - > unicode範圍相同的字符範圍:“ u+1000-2000,u+2500-2501”等。請注意,請注意每對中的第二個數字沒有“ u+” - 這與字體庫的所需輸入格式相匹配。optimise_fonts_for_html_contents()類似於optimise_fonts_for_html_files ,除了輸入為html作為字符串(例如<head>...</head><body>...<body> )。它不能解析找到使用的CSS文件(以及使用的字體),因此您還需要給它一個字體文件列表以優化。
參數:
html_contents : list[str] :HTML字符串列表。該文本將被提取並用於生成優化字體的字形列表。fonts : list[str] :本地文件系統上的路徑列表以優化字體。這些可以是相對路徑。其他參數( fontpath , subsetname , verbose , print_stats )與optimise_fonts_for_html_files相同。
返回:
dict keys()是原始字體文件,每個密鑰的值是生成的替換字體文件optimise_fonts_for_multiple_text()類似於optimise_fonts_for_html_contents ,除了輸入是Python字符串列表。這些字符串的內容用於生成優化字體的字形:輸入字符串中的每個唯一字符都會有一個字形(如果輸入字體包含所需的字形。)
將字體文件( fonts參數)列表傳遞為輸入字體文件,以根據文本進行優化。
參數:
texts : list[str] :Python字符串列表。生成的字體將包含這些字符串使用的字形。其他參數( fonts , fontpath , subsetname , verbose , print_stats )和返回值對optimise_fonts_for_html_contents為單元。
optimise_fonts()這是主要方法;上面的所有方法最終都在這裡。它需要一個python Unicode文本字符串,並列出了字體文件的路徑列表以優化,並創建僅包含輸入文本所需的唯一字形的字體子集。
參數:
text: str :python unicode字符串。從中生成了一組唯一的Unicode字符,輸出字體文件將包含正確渲染此字符串所需的所有字形(假設字體包含要開始的字形。)其他參數( fonts , fontpath , subsetname , verbose , print_stats )和返回值與optimise_fonts_for_html_contents和optimise_fonts_for_multiple_text相同。
命令行工具可以獨立使用或集成到內容生成管道中。
簡單用法:
python3 fontimize.py file_a.html file_b.html
這解析了HTML以及任何引用的外部CSS文件,以找到同時的字體和二手字體。它與輸入字體文件同一位置生成新的字體文件。
python3 fontimize.py --text "The fonts will contain only the glyphs in this string" --fonts "Arial.tff" "Times New Roman.ttf"
這僅生成指定字符串所需的字形,並在與輸入字體文件相同的位置以Woff2格式創建新版本的Arial和Times New Roman。
--text "string here" ( -t ):用於渲染此字符串的字形將添加到輸入文件中的字形(如果有的話)中。您必須傳遞輸入文件或文本(或兩者),否則會出現錯誤。--fonts "a.ttf" "b.ttf" ( -f ):輸入字體的可選列表。這些將添加到通過HTML/CSS引用的任何發現。 --outputdir folder_here ( -o ):放置生成的字體文件的目錄。這一定已經存在。--subsetname MySubset ( -s ):生成的字體文件名中使用的短語。將輸出字體與輸入字體區分開很重要,因為(按定義作為子集)它們不完整。 --verbose ( -v ):在處理時輸出詳細信息--nostats ( -n ):未打印有關優化結果的信息單位測試通過tests.py進行運行,並在tests中使用文件。請注意,這將在testsoutput文件夾中生成新的輸出文件。
tests文件夾包含在SIL Open Font許可證下獲得許可的幾個字體。
我將Fontimize用作自定義靜態站點生成器的一部分來構建我的網站。它是最後一步,根據存儲在磁盤上的生成的HTML文件優化字體。然後,來自Fontimize的返回值(例如它創建的字體和分析的CSS文件)是用來重寫CSS並指向新優化的字體的。
(重寫CSS當前不是通過Fontimize提供的功能;如果您願意的話,請創建問題或拉動請求。當前,該庫會生成新的字體文件並返回映射(作為字典或文本輸出),以顯示舊字體文件和相應的新文件,但是,如果您不需要修改該文件,則該文件不適合您,如果您願意為您進行修改,請使用該文件,如果您願意為您進行修改。需要顯式這樣做。
默認情況下,新的子集字體將以“ fontimizersubset”的後綴命名,例如, Arial.FontimizerSubset.woff2 。您可以使用subsetname方法參數或--subsetname=Foo命令行參數自定義子集字體的名稱。建議使用子集名稱避免將優化字體與原始字體混淆(包含所有字形),但您可以使用任何喜歡的名稱。默認的名稱“ fontimizersubset”只是一個建議,將其他人指向此庫,如果他們遇到它。沒有必要保留此名稱,您可以自由使用其他短語。
CSS偽元素:
對於明確使用的字體和屏幕上顯示的任何字形的字體,就會對兩個字體進行parses css。這包括CSS偽元素中的字形,例如:before和:after 。如果在這些偽元素中定義了文本或字符,則將它們包含在子集字體中。
內聯CSS:
Fontimize當前未在HTML文件中解析內聯CSS。它假設正在使用外部CSS,它通過HTML文檔的<head>部分中的<link>標籤找到。然後,Fontimize將對字體和字形分析這些CSS文件。如果對內聯CSS進行解析會有所幫助,請提出一個問題。
其他字符:
當輸入文本中找到單個或雙引號時,子集字體還將包括相應的左和右傾角引號。同樣,如果找到破折號,該子集將包括持續儀表和EM劃線。
如果您使用fontimizer,鏈接到https://fontimize.daveon.design/或此github repo是真的很不錯(但不是必需的)。那就是將其他人指向該工具。非常感謝:)


