Fontimize
1.0.0
Die Schriftarten (Teilmenge) einfach auf nur die spezifischen Glyphen (Subset) zu optimieren, die für Ihren Text oder HTML benötigt werden!
Sind Sie besorgt über die erste Download -Größe Ihrer Website? Erfordern Sie Megabyte von Downloads, und Sie haben Ihre CSS, JavaScript und Bilder optimiert und abgebrochen, haben jedoch einige große Schriftarten entdeckt? Fontimize ist für Sie! Dieses Tool analysiert Ihre HTML -Dateien und CSS (oder einen beliebigen Text) und erstellt Schriftarten , Schriftdateien, die nur die tatsächlich verwendeten Zeichen oder Glyphen enthalten.
In der Praxis können Sie Ihre Schriftart -Download -Größe auf 10% oder weniger des Originals verkleinern.
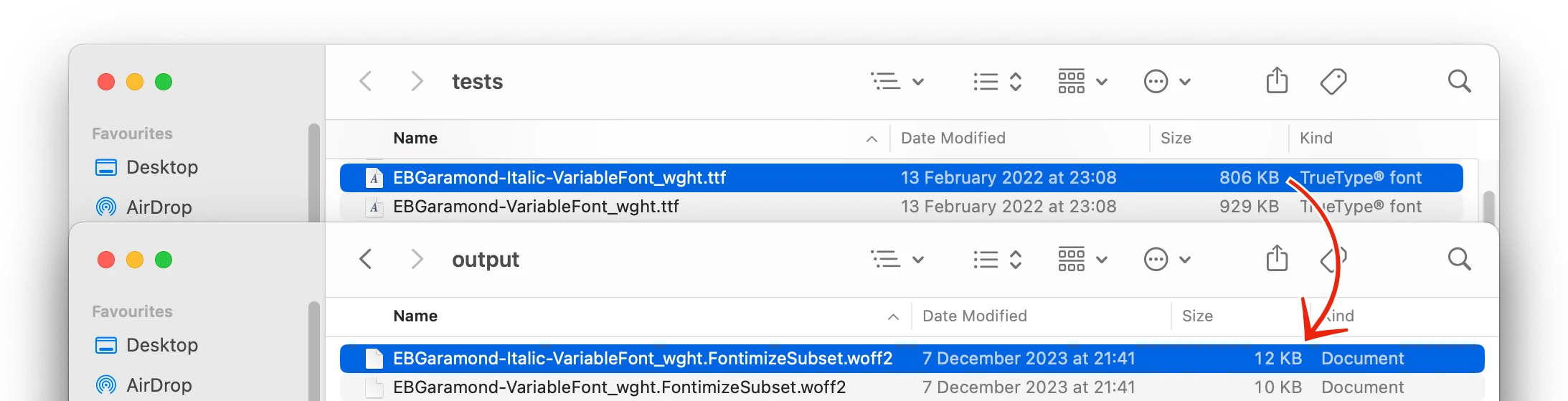
Fontimize verwendet TTF2Web und vielen Dank und Kredit an den Autor dieser fantastischen Bibliothek.
Diese Bibliothek wurde ursprünglich für meine persönliche Website erstellt. Es wurde vier TTF -Schriftarten mit einem Gesamtwert von etwas mehr als 1,5 MB verwendet. (Dies ist nicht ungewöhnlich: eine für Überschriften, eine für den normalen Text mit einer Variante für kursive ITALIC sowie ein viertes für eine typografische Eigenart, Dropcaps.)
Nach dem Ausführen von Fontimize beträgt die Gesamtgröße für alle Schriftarten zusammen 76 KB.
1,5 MB bis 76 KB sind eine Einsparung von 95,2%! Dies hatte merkwürdige Auswirkungen auf die erste Zeit, um eine Seite auf der Website herunterzuladen, sowie immensen Auswirkungen auf das Rendering: Vorher würde die anfängliche Ladung der Site mit generischen Serifenschriften und dann ein paar Sekunden später wieder rendern, sobald die Schriftarten heruntergeladen wurden, was wirklich schlecht aussah. Jetzt erhalten Sie die neuen Schriftarten sofort oder bevor Sie es bemerken, und die Website sieht von Anfang an korrekt aus.
Fontimize ist eine Python-Bibliothek und kann in Ihrer Python-Software oder in der Befehlszeile verwendet werden.
Beginnen Sie mit der Installation und Importierung von Fontimize:
$ python3 -m pip install fontimize
In Ihrem Skript:
import fontimizeUm einen Satz von HTML -Dateien auf der Festplatte und die von ihnen verwendeten CSS -Dateien zu analysieren und neue Schriftarten (standardmäßig im selben Ordner wie die ursprünglichen Schriftarten) zu exportieren), die nur die in der HTML verwendeten Glyphen enthalten:
all_html_files = [ 'input/one.html' , 'input/two.html' ]
font_results = fontimize . optimise_fonts_for_files ( all_html_files )
print ( font_results [ "css" ])
# Prints CSS files found used by any of the HTML input files:
# { 'input/main.css',
# 'input/secondary.css' }
print ( font_results [ "fonts" ])
# Prints pairs mapping the old fonts to the new optimised font generated for each. Use this to, eg, rewrite your CSS
# By default exports to the same folder as the input files; use `font_output_dir` to change
# { 'input/fonts/Arial.ttf': 'input/fonts/Arial.FontimizeSubset.woff2',
# 'input/fonts/EB Garamond.ttf': 'input/fonts/EB Garamond.FontimizeSubset.woff2' }
print ( font_results [ "chars" ]
# Prints the set of characters that were found or synthesised that the output fonts will use
# { ',', 'u', '.', '@', 'n', 'a', '_', 'l', 'i', 'h', 'Q', 'y', 'w', 'T', 'q', 'j', ' ', 'p', 'm', 's', 'o', 't', 'c' ... }
print ( font_results [ "uranges" ]
# Prints the same set of characters, formatted as ranges of Unicode characters
# U+0020, U+002C, U+002E, U+0040, U+0051, U+0054, U+005F, U+0061-007A ...optimise_fonts_for_files()Dies ist wahrscheinlich die Methode, die Sie verwenden möchten.
Optimiert / Teilmengen Schriftarten basierend auf einer Reihe von Eingabedateien auf der Festplatte und (automatisch) auf die externen CSS -Dateien, auf die sich auf die HTML -Dateien beziehen. Dateien werden als HTML analysiert, wenn sie eine .htm oder .html Dateierweiterung haben (benutzerfreundlicher Text wird extrahiert und CSS wird analysiert), andernfalls werden Dateien als Text behandelt. Gibt die Liste der gefundenen CSS -Dateien und eine Karte der Alten in neue optimierte Schriftarteien zurück.
Parameter:
html_files : list[str] : Liste der Pfade, von denen jedes eine HTML -Datei ist. Jeder wird analysiert.font_output_dir = "" : Pfad zu dem Ort, an dem die untergrenzten Schriftarten platziert werden sollen. Standardmäßig ist dies leer ( "" ), was bedeutet, die neuen Schriftarten an derselben Stelle wie die Eingangsschriften zu generieren. Da die neuen Schriftarten einen anderen Namen haben (siehe subsetname , den nächsten Parameter), überschreiben Sie die Eingangsschriften nicht. Es gibt keine Überprüfung, ob bereits vor ihrem geschriebene Untergruppen -Schriftarten vorhanden sind .subsetname = "FontimizeSubset" : Die optimierten Schriftarten werden im Format OriginalName.FontimizeSubset.woff2 umbenannt. Es ist wichtig, die untergrenzten Schriftarten von den ursprünglichen Schriftarten mit allen Glyphen zu unterscheiden. Sie können den Ausgabebereichernamen in eine andere Zeichenfolge ändern, die in Ihrem Dateisystem gültig ist.verbose : bool = False : Wenn True , emittiert diagnostische Informationen über die CSS -Dateien, Schriftarten usw., die es gefunden und generiert.print_stats : bool = True : druckt Informationen für die Gesamtgröße auf der Festplatte der Eingangsschriften und die Gesamtgröße der optimierten Schriftarten sowie die Einsparungen in Prozent. Stellen Sie dies auf False , wenn Sie möchten, dass es lautlos ausgeführt wird.fonts : list[str] = [] : Eine Liste von Pfaden zu Schriftdateien. Diese werden zu allen Schriftarten hinzugefügt, die die Methode über CSS findet. Sie würden dies normalerweise angeben, wenn Sie Textdateien anstelle von HTML übergebenaddtl_text : str = "" : Zusätzliche Zeichen, die zu den in den Dateien gefundenen hinzugefügt werden solltenRückgaben:
dict[str, typing.Any]return_value["css"] -> Liste der eindeutigen CSS -Dateien, die die HTML -Dateien verwendenreturn_value["fonts"] -> ein dict , wobei keys() die ursprünglichen Schriftart Dateien sind, und der Wert für jeden Schlüssel ist die Ersatz -Schriftdatei, die generiert wurde. Sie können dies verwenden, um Verweise auf die ursprünglichen Schriftartdateien zu aktualisieren. Beachten Sie, dass Fontimizer das Eingangs -CSS nicht umschreibt.return_value["chars"] -> eine set von Zeichen gefunden, die beim Parsen der Eingabe gefunden wurdenreturn_value["uranges] -> Die Unicode-Bereiche für dieselben Zeichenoptimise_fonts_for_html_contents() Ähnlich wie optimise_fonts_for_html_files , außer dass die Eingabe Html als Zeichenfolge ist (z. <head>...</head><body>...<body> ). Es wird nicht analysiert, um die verwendeten CSS -Dateien (und somit verwendete Schriftarten) zu finden. Daher müssen Sie ihm auch eine Liste von Schriftartdateien zur Optimierung geben.
Parameter:
html_contents : list[str] : Liste der HTML -Zeichenfolgen. Der Text wird extrahiert und verwendet, um die Liste der Glyphen für die optimierten Schriftarten zu generieren.fonts : list[str] : Liste der Pfade in Ihrem lokalen Dateisystem zu Schriftdateien zur Optimierung. Dies können relative Pfade sein. Andere Parameter ( fontpath , subsetname , verbose , print_stats ) sind identisch mit optimise_fonts_for_html_files .
Rückgaben:
dict , in dem keys() die ursprünglichen Schriftart Dateien sind, und der Wert für jeden Schlüssel ist die Ersatz -Schriftdatei, die generiert wurdeoptimise_fonts_for_multiple_text() Ähnlich wie optimise_fonts_for_html_contents , außer dass die Eingabe eine Liste von Python -Zeichenfolgen ist. Der Inhalt dieser Saiten wird verwendet, um die Glyphen für die optimierten Schriftarten zu erzeugen: Es gibt eine Glyphe für jedes einzigartige Zeichen in den Eingangszeichenfolgen (wenn die Eingangsschriften die erforderlichen Glyphen enthalten.)
Geben Sie eine Liste von Schriftartdateien ( fonts Parameter) als Eingabe -Schriftart Dateien ein, um basierend auf dem Text zu optimieren.
Parameter:
texts : list[str] : Liste der Python -Zeichenfolgen. Die erzeugten Schriftarten enthalten die Glyphen, die diese Saiten verwenden. Andere Parameter ( fonts , fontpath , subsetname , verbose , print_stats ) und der Rückgabewert sind für optimise_fonts_for_html_contents ideal.
optimise_fonts()Dies ist die Hauptmethode; Alle oben genannten Methoden enden hier. Es benötigt eine Python -Unicode -Textzeichenfolge und eine Liste von Pfaden zu Schriftdateien, um zu optimieren, und erstellt Schriftarten, die nur die eindeutigen Glyphen enthalten, die für den Eingabetxt erforderlich sind.
Parameter:
text: str : Eine Python -Unicode -Zeichenfolge. Aus diesem Grund wird ein Satz eindeutiger Unicode -Zeichen erzeugt, und die Ausgabe -Schriftart Dateien enthalten alle Glyphen, die erforderlich sind, um diese Zeichenfolge korrekt zu rendern (vorausgesetzt, die Schriftarten enthielten die Glyphen zunächst.) Andere Parameter ( fonts , fontpath , subsetname , verbose , print_stats ) und der Rückgabewert sind identisch mit optimise_fonts_for_html_contents und optimise_fonts_for_multiple_text .
Das Befehlszeilen -Tool kann eigenständig oder in eine Pipeline für die Inhaltsgenerierung integriert werden.
Einfache Verwendung:
python3 fontimize.py file_a.html file_b.html
Dies analysiert die HTML sowie alle referenzierten externen CSS -Dateien, um sowohl Glyphen als auch verwendete Schriftarten zu finden. Es generiert neue Schriftdateien am selben Ort wie die Eingabe -Schriftartdateien.
python3 fontimize.py --text "The fonts will contain only the glyphs in this string" --fonts "Arial.tff" "Times New Roman.ttf"
Dies erzeugt nur die für die angegebenen Zeichenfolge erforderlichen Glyphen und erstellt neue Versionen von Arial und Times New Roman im WOFF2 -Format am selben Ort wie die Eingabe -Schriftartdateien.
--text "string here" ( -t ): Die zum Rendern dieser Zeichenfolge verwendeten Glyphen werden zu den in den Eingabedateien gefundenen Glyphen hinzugefügt, falls vorhandenen angegeben. Sie müssen entweder Eingabedateien oder Text (oder beides) übergeben, andernfalls wird ein Fehler angegeben.--fonts "a.ttf" "b.ttf" ( -f ): Optionale Liste der Eingabeberichte. Diese werden zu jedem gefundenen gefundenen über HTML/CSS hinzugefügt. --outputdir folder_here ( -o ): Verzeichnis, in dem die generierten Schriftartdateien platziert werden sollen. Dies muss bereits existieren.--subsetname MySubset ( -s ): Phrase, die in den generierten Schriftstellungsamen verwendet werden. Es ist wichtig, die Ausgangsschriften von den Eingangsschriften zu unterscheiden, da sie (per Definition als Teilmenge) unvollständig sind. --verbose ( -v ): Ausgaben detaillierte Informationen während des Verfahrens--nostats ( -n ): Drucken Sie keine Informationen über optimierte Ergebnisse am Ende Unit -Tests werden über tests.py ausgeführt und verwenden die Dateien in tests . Beachten Sie, dass dies neue Ausgabedateien in dem Ordner testsoutput generiert.
Der tests -Ordner enthält mehrere Schriftarten, die unter der SIL Open -Schriftart Lizenz lizenziert sind.
Ich verwende Fontimize als Teil eines benutzerdefinierten statischen Site -Generators, um meine Website zu erstellen. Es arbeitet als letzter Schritt und optimiert Schriftarten basierend auf den generierten HTML -Dateien, die auf der Festplatte gespeichert sind. Die Rückgabewerte von Fontimize - wie die von ihm erstellten Schriftarten und die von ihm analysierten CSS -Dateien - werden dann verwendet, um das CSS umzuschreiben und auf die neu optimierten Schriftarten zu verweisen.
(Umschreiben von CSS ist derzeit keine Funktion, die von fontimize bereitgestellt wird. Bitte erstellen Sie eine Ausgabe- oder Pull -Anfrage, wenn Sie möchten. Derzeit generiert die Bibliothek neue Schriftdateien und gibt eine Zuordnung zurück (entweder als Wörterbuch- oder Textausgabe), die die alten Schriftart Dateien zeigt, die die alten Schriftart Dateien und die entsprechenden neuen Gründe ändern. Um dies ausdrücklich zu tun.
Standardmäßig werden die neuen unterklärten Schriftarten mit dem Suffix "fontimizerSubset", Arial.FontimizerSubset.woff2 . Sie können den Namen der Teilmenge-Schriftart unter Verwendung des Parameters der subsetname -Methode oder des Parameters --subsetname=Foo ) anpassen. Es wird empfohlen, einen Untermenschnamen zu verwenden, um zu vermeiden, dass die optimierte Schriftart mit der ursprünglichen Schriftart (die alle Glyphen enthält) zu verwechseln, können Sie einen beliebigen Namen verwenden, den Sie bevorzugen. Der Standardname „FontimizerSubset“ ist einfach ein Vorschlag, andere auf diese Bibliothek zurückzusetzen, falls sie darauf stoßen sollten. Es ist nicht erforderlich, diesen Namen beizubehalten, und Sie können einen anderen Satz verwenden.
CSS Pseudo-Elemente:
Fontimieren Sie Parses CSS für beide Schriftarten, die explizit verwendet werden, und für alle auf dem Bildschirm angezeigten Glyphen. Dies beinhaltet Glyphen in CSS-Pseudoelementen wie :before und :after . Wenn Text oder Zeichen in diesen Pseudoelementen definiert sind, werden sie in die untergrenzten Schriftarten aufgenommen.
Inline -CSS:
Fontimize analysiert derzeit keine Inline -CSS in HTML -Dateien. Es wird davon ausgegangen, dass externe CSS verwendet wird, was durch die <link> -Tags im Abschnitt <head> des HTML -Dokuments findet. Fontimize analysiert dann diese CSS -Dateien für Schriftarten und Glyphen. Wenn das Parsen von Inline -CSS hilfreich wäre, wecken Sie bitte ein Problem.
Zusätzliche Zeichen:
Wenn im Eingabetext einzelne oder doppelte Zitate enthalten sind, enthält die untergrenzte Schriftart auch die entsprechenden Zitate für die linke und rechtsgerichtete. In ähnlicher Weise enthält die Teilmenge, wenn ein Armaturenbrett gefunden wird, sowohl En-Dashes als auch Em-Dashes.
Es ist wirklich schön (aber nicht erforderlich), dass wenn Sie Fontimizer verwenden, um mit https://fontimize.daveon.design/ oder diesem Github Repo zu verlinken. Das soll andere Menschen auf das Werkzeug verweisen. Vielen Dank :)


