matfuse sd
1.0.0
Giuseppe Vecchio,Renato Sortino,Simone Palazzo和Concetto Spampinato

紙質官方的Pytorch實施“ Matfuse:具有擴散模型的可控材料生成” 。
Matfuse是一種新穎的方法,可以簡化SVBRDF(空間變化的雙向反射分佈函數)映射的創建。
它利用擴散模型(DM)的生成能力簡化材料合成過程。通過整合多種調節源,包括調色板,草圖,文本和圖片,它在材料生成中提供了細粒度的控制和靈活性。
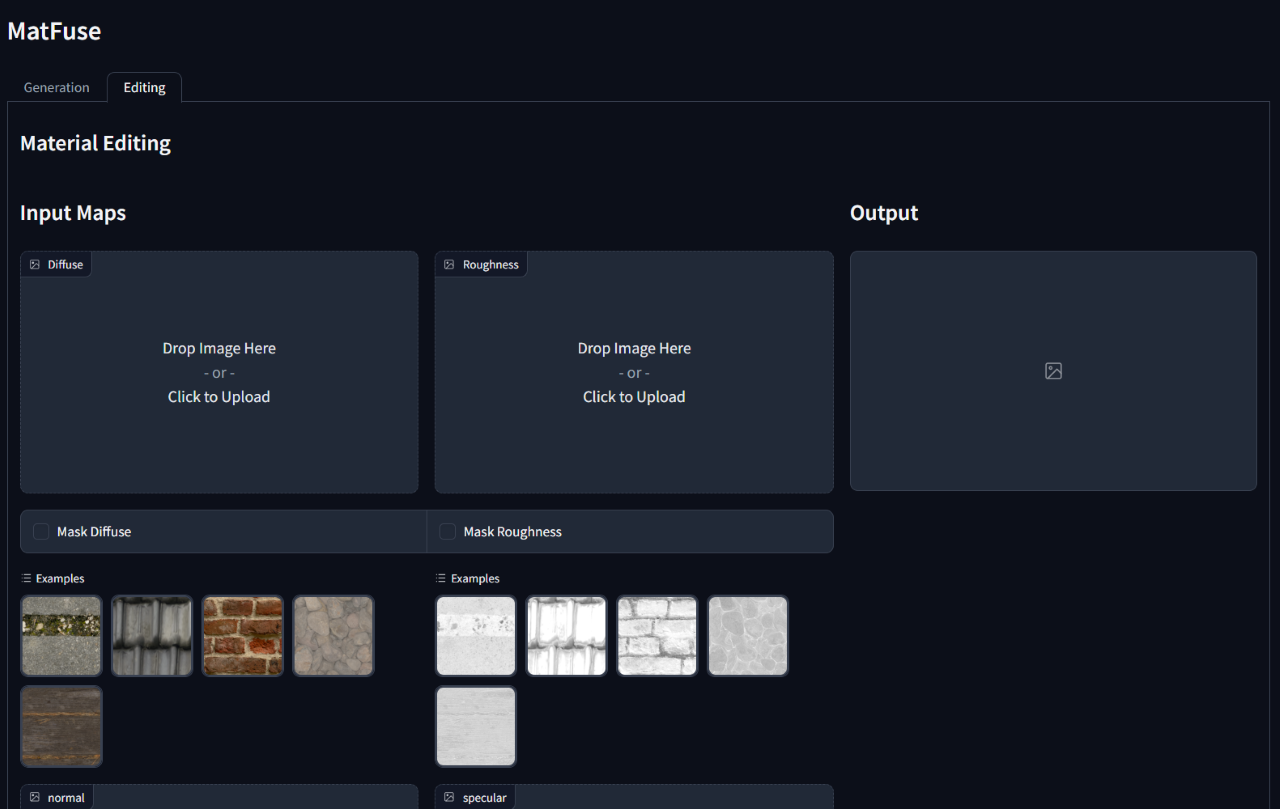
此外,Matfuse最初一代後啟用了合成材料的編輯或完善合成材料。它通過掩蓋特定地圖或整個材料的特定區域來支持地圖級編輯。

在計算機圖形上創建高質量的材料是一項具有挑戰性且耗時的任務,需要大量的專業知識。簡而言之,我們引入了Matfuse ,這是一種統一的方法,它利用擴散模型的生成力量來簡化SVBRDF地圖的創建。我們的管道集成了多種條件來源,包括調色板,草圖,文本和圖片,以獲得細粒度的控制和材料合成的靈活性。該設計使各種信息源(例如,草圖 +文本)的結合,根據構圖的原則增強了創造性的可能性。此外,我們提出了一個具有兩個折疊目的的多編碼壓縮模型:它通過學習每個地圖的單獨的潛在表示來提高重建性能,並啟用地圖級材料編輯能力。我們證明了Matfuse在多種條件設置下的有效性,並探討了材料編輯的潛力。我們還根據夾子IQA和FID得分來定量評估生成材料的質量。
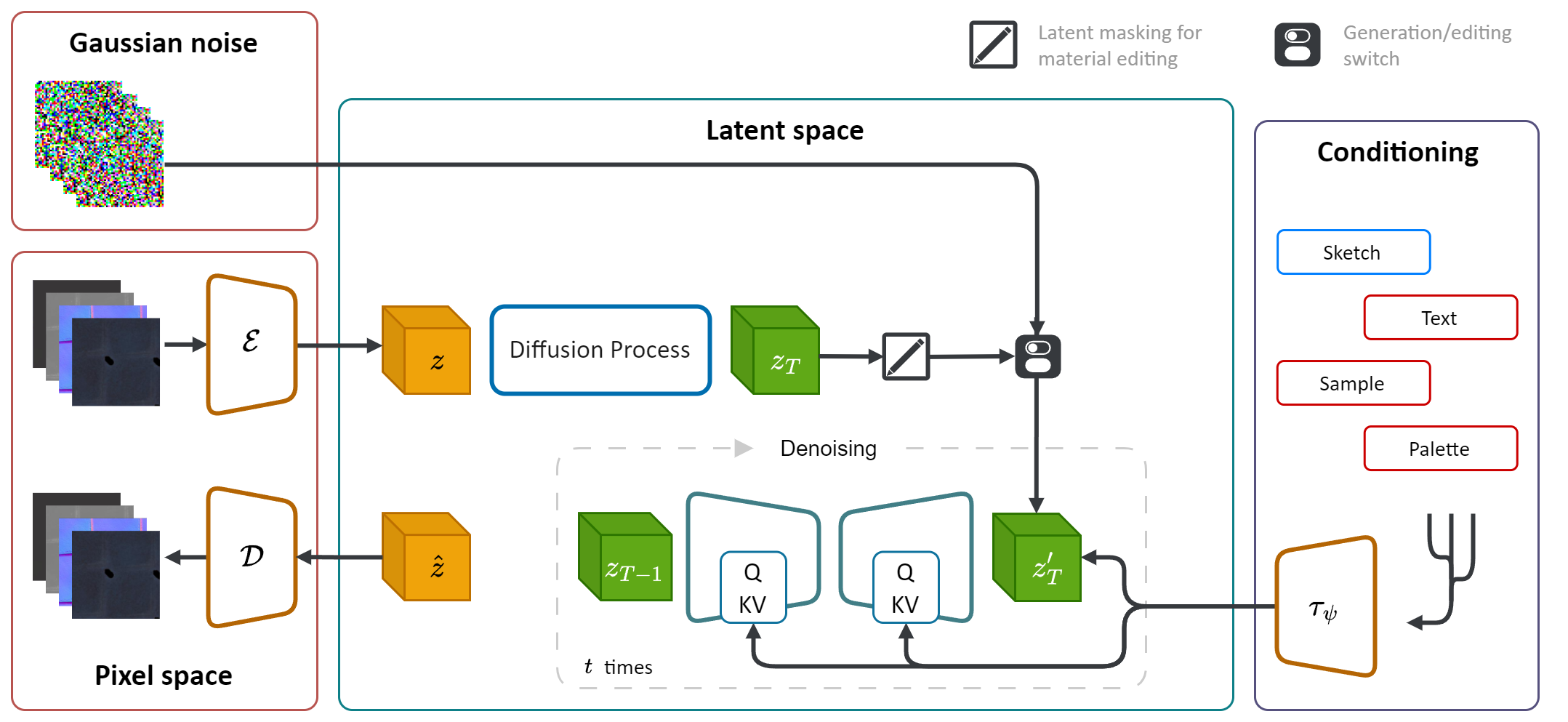
此存儲庫依賴於原始的潛在擴散實現(https://github.com/compvis/stable-diffusion),該實現已修改為包括Matfuse Paper中所述的功能。如果您熟悉原始穩定的擴散代碼庫,則可以沒有任何問題。
最相關的更改是:
Deschaintre等人對Matfuse的數據集進行了訓練。 (2018年)和polyheaven庫中的材料。我們不打算釋放可以輕鬆收集的數據集。無論如何,如果您打算培訓自己的矩陣,我們會使用最近發布的數據集Matsynth強烈推薦,該數據集Matsynth包含更廣泛的高分辨率材料和註釋。
git clone https://github.com/giuvecchio/matfuse-sd.git
cd matfuse-sd這是假設您在克隆之後已導航到matfuse-sd根。
注意:這是根據python3.10進行的。對於其他Python版本,您可能會遇到版本衝突。
Pytorch 1.13.1
# create environment (can use venv instead of conda)
conda create -n matfuse python==3.10.13
conda activate matfuse
# install required packages
pip install -r requirements.txt對矩陣的培訓需要兩個步驟:
兩者都可以通過src文件夾中的main.py腳本訪問,並依賴於使用配置文件來設置模型,數據集和損失。
配置文件位於src/configs/下,在autoencoder和diffusion子文件夾中分配。
根據要訓練的模型部分,使用正確的配置文件。
發起培訓的一般命令是:
python src/main.py --base src/configs/ < model > / < config.yaml > --train --gpus < indices, > 我們提供一個數據集課程,用於培訓Matfuse。該數據集希望將數據文件夾構造,如下所示。
./data/MatFuse/{split}/
├── bricks_045
│ ├── metadata.json
│ ├── diffuse.png
│ ├── normal.png
│ ├── roughness.png
│ ├── specular.png
│ ├── sketch.png
│ ├── renders
│ ├── render_00.png
│ ├── render_01.png
│ ├── ...
├── ...
數據應分配在train和test集之間。每個材料文件夾都包含所需的SVBRDF地圖(漫射,正常,粗糙度,鏡面),草圖和帶有文本標題和調色板的metadata.json數據。
data_root屬性,以指向存儲數據集的文件夾。
我們提供一個腳本來從src/scripts/data文件夾下的渲染器中提取調色板。運行它運行:
python src/scripts/data/extract_palette.py --data < path/to/dataset > 用於培訓的配置,可在src/configs/autoencoder上提供自動編碼器。
Matfuse使用VQ調查模型。有關更多信息,請參見Taming-Transformers存儲庫。
可以通過跑步開始訓練
python src/main.py --base src/configs/autoencoder/multi-vq_f8.yaml --train --gpus 0,在src/configs/diffusion/我們提供用於培訓矩陣LDMS的配置。first_stage_config下更新ckpt_path ,在matfuse-ldm-vq_f8.yaml中指向您的VQ-VAE檢查點。
可以通過跑步開始訓練
python src/main.py --base src/configs/diffusion/matfuse-ldm-vq_f8.yaml --train --gpus 0,要恢復培訓,請將參數--resume <log/folder>附加到培訓命令。
如果您在Windows上進行培訓,請記住將分佈式後端設置為gloo 。其他人不受支持!
$env :PL_TORCH_DISTRIBUTED_BACKEND= ' gloo '限制可見GPU的使用數:
CUDA_VISIBLE_DEVICES= < GPU_ID > python src/main.py ...實驗會使用權重和偏差自動記錄。要指定自己的項目空間和項目名稱設置以下環境變量:
WANDB_PROJECT= ' {YOUR_PROJECT_NAME} '
WANDB_ENTITY= ' {YOUR_PROJECT_SPACE_NAME} '要運行訓練有素的模型,請運行gradio_app.py腳本,指定了模型檢查點和配置的路徑。
這將打開網絡接口以執行有條件的生成和材料編輯。
python src/gradio_app.py --ckpt < path/to/checkpoint.ckpt > --config src/configs/diffusion/ < config.yaml > 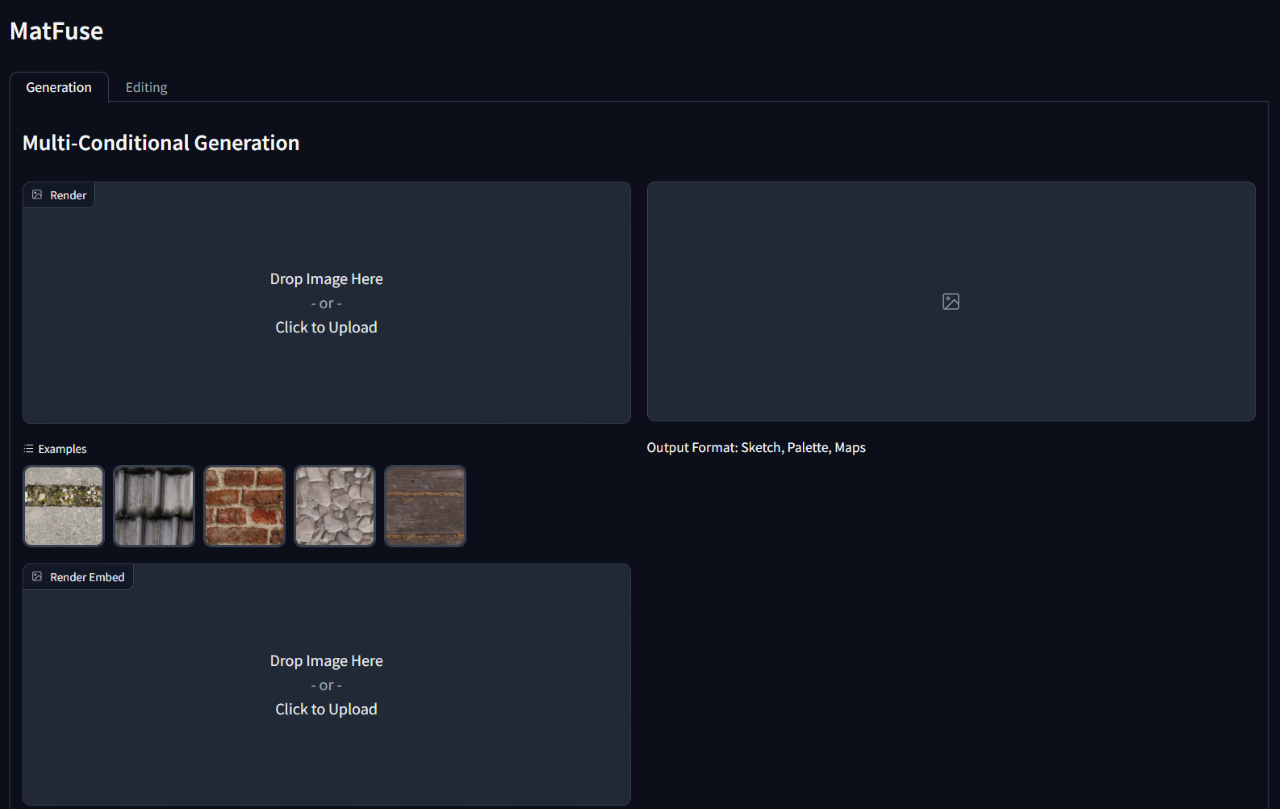
@inproceedings { vecchio2024matfuse ,
author = { Vecchio, Giuseppe and Sortino, Renato and Palazzo, Simone and Spampinato, Concetto } ,
title = { MatFuse: Controllable Material Generation with Diffusion Models } ,
booktitle = { Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
month = { June } ,
year = { 2024 } ,
pages = { 4429-4438 }
}

