matfuse sd
1.0.0
Giuseppe Vecchio,Renato Sortino,Simone Palazzo和Concetto Spampinato

纸质官方的Pytorch实施“ Matfuse:具有扩散模型的可控材料生成” 。
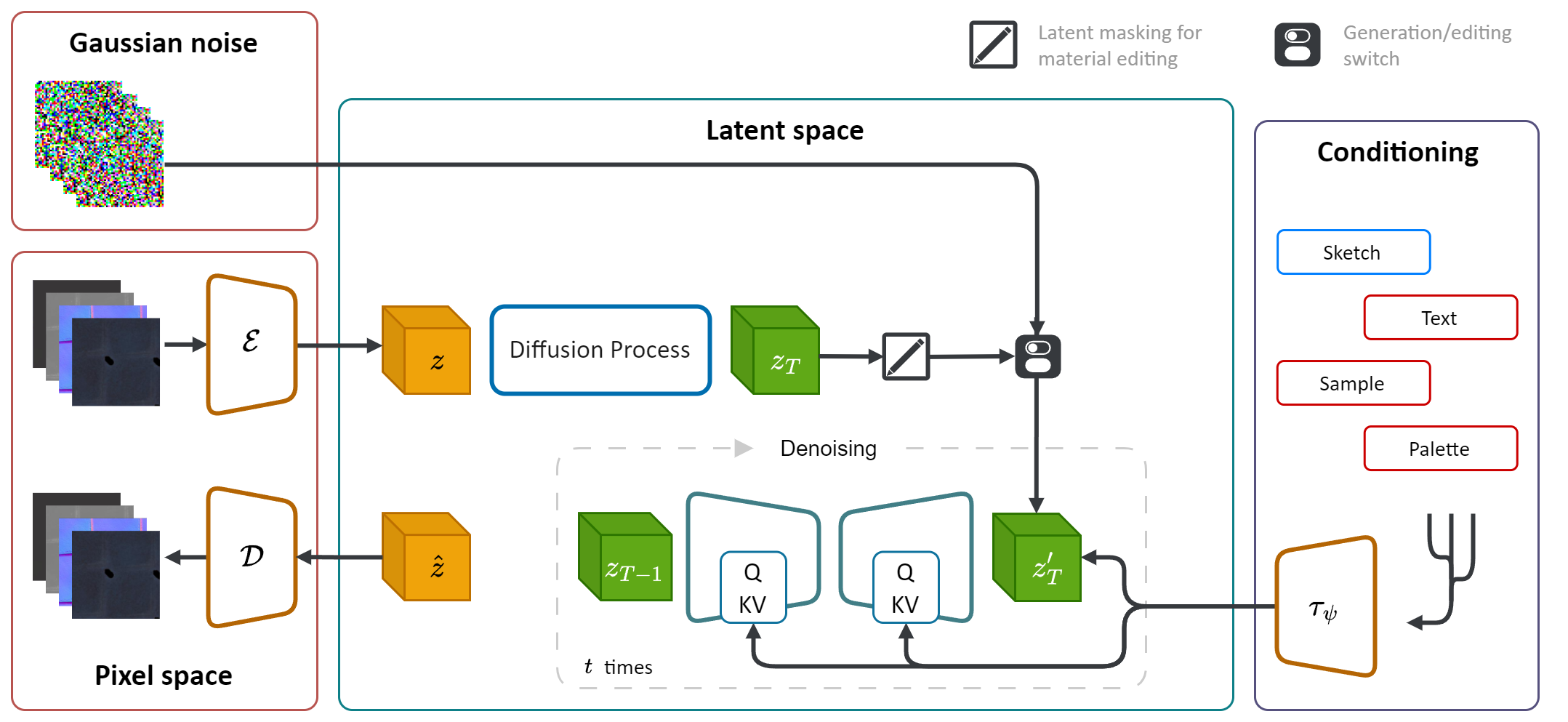
Matfuse是一种新颖的方法,可以简化SVBRDF(空间变化的双向反射分布函数)映射的创建。
它利用扩散模型(DM)的生成能力简化材料合成过程。通过整合多种调节源,包括调色板,草图,文本和图片,它在材料生成中提供了细粒度的控制和灵活性。
此外,Matfuse最初一代后启用了合成材料的编辑或完善合成材料。它通过掩盖特定地图或整个材料的特定区域来支持地图级编辑。

在计算机图形上创建高质量的材料是一项具有挑战性且耗时的任务,需要大量的专业知识。简而言之,我们引入了Matfuse ,这是一种统一的方法,它利用扩散模型的生成力量来简化SVBRDF地图的创建。我们的管道集成了多种条件来源,包括调色板,草图,文本和图片,以获得细粒度的控制和材料合成的灵活性。该设计使各种信息源(例如,草图 +文本)的结合,根据构图的原则增强了创造性的可能性。此外,我们提出了一个具有两个折叠目的的多编码压缩模型:它通过学习每个地图的单独的潜在表示来提高重建性能,并启用地图级材料编辑能力。我们证明了Matfuse在多种条件设置下的有效性,并探讨了材料编辑的潜力。我们还根据夹子IQA和FID得分来定量评估生成材料的质量。
此存储库依赖于原始的潜在扩散实现(https://github.com/compvis/stable-diffusion),该实现已修改为包括Matfuse Paper中所述的功能。如果您熟悉原始稳定的扩散代码库,则可以没有任何问题。
最相关的更改是:
Deschaintre等人对Matfuse的数据集进行了训练。 (2018年)和polyheaven库中的材料。我们不打算释放可以轻松收集的数据集。无论如何,如果您打算培训自己的矩阵,我们会使用最近发布的数据集Matsynth强烈推荐,该数据集Matsynth包含更广泛的高分辨率材料和注释。
git clone https://github.com/giuvecchio/matfuse-sd.git
cd matfuse-sd这是假设您在克隆之后已导航到matfuse-sd根。
注意:这是根据python3.10进行的。对于其他Python版本,您可能会遇到版本冲突。
Pytorch 1.13.1
# create environment (can use venv instead of conda)
conda create -n matfuse python==3.10.13
conda activate matfuse
# install required packages
pip install -r requirements.txt对矩阵的培训需要两个步骤:
两者都可以通过src文件夹中的main.py脚本访问,并依赖于使用配置文件来设置模型,数据集和损失。
配置文件位于src/configs/下,在autoencoder和diffusion子文件夹中分配。
根据要训练的模型部分,使用正确的配置文件。
发起培训的一般命令是:
python src/main.py --base src/configs/ < model > / < config.yaml > --train --gpus < indices, > 我们提供一个数据集课程,用于培训Matfuse。该数据集希望将数据文件夹构造,如下所示。
./data/MatFuse/{split}/
├── bricks_045
│ ├── metadata.json
│ ├── diffuse.png
│ ├── normal.png
│ ├── roughness.png
│ ├── specular.png
│ ├── sketch.png
│ ├── renders
│ ├── render_00.png
│ ├── render_01.png
│ ├── ...
├── ...
数据应分配在train和test集之间。每个材料文件夹都包含所需的SVBRDF地图(漫射,正常,粗糙度,镜面),草图和带有文本标题和调色板的metadata.json数据。
data_root属性,以指向存储数据集的文件夹。
我们提供一个脚本来从src/scripts/data文件夹下的渲染器中提取调色板。运行它运行:
python src/scripts/data/extract_palette.py --data < path/to/dataset > 用于培训的配置,可在src/configs/autoencoder上提供自动编码器。
Matfuse使用VQ调查模型。有关更多信息,请参见Taming-Transformers存储库。
可以通过跑步开始训练
python src/main.py --base src/configs/autoencoder/multi-vq_f8.yaml --train --gpus 0,在src/configs/diffusion/我们提供用于培训矩阵LDMS的配置。first_stage_config下更新ckpt_path ,在matfuse-ldm-vq_f8.yaml中指向您的VQ-VAE检查点。
可以通过跑步开始训练
python src/main.py --base src/configs/diffusion/matfuse-ldm-vq_f8.yaml --train --gpus 0,要恢复培训,请将参数--resume <log/folder>附加到培训命令。
如果您在Windows上进行培训,请记住将分布式后端设置为gloo 。其他人不受支持!
$env :PL_TORCH_DISTRIBUTED_BACKEND= ' gloo '限制可见GPU的使用数:
CUDA_VISIBLE_DEVICES= < GPU_ID > python src/main.py ...实验会使用权重和偏差自动记录。要指定自己的项目空间和项目名称设置以下环境变量:
WANDB_PROJECT= ' {YOUR_PROJECT_NAME} '
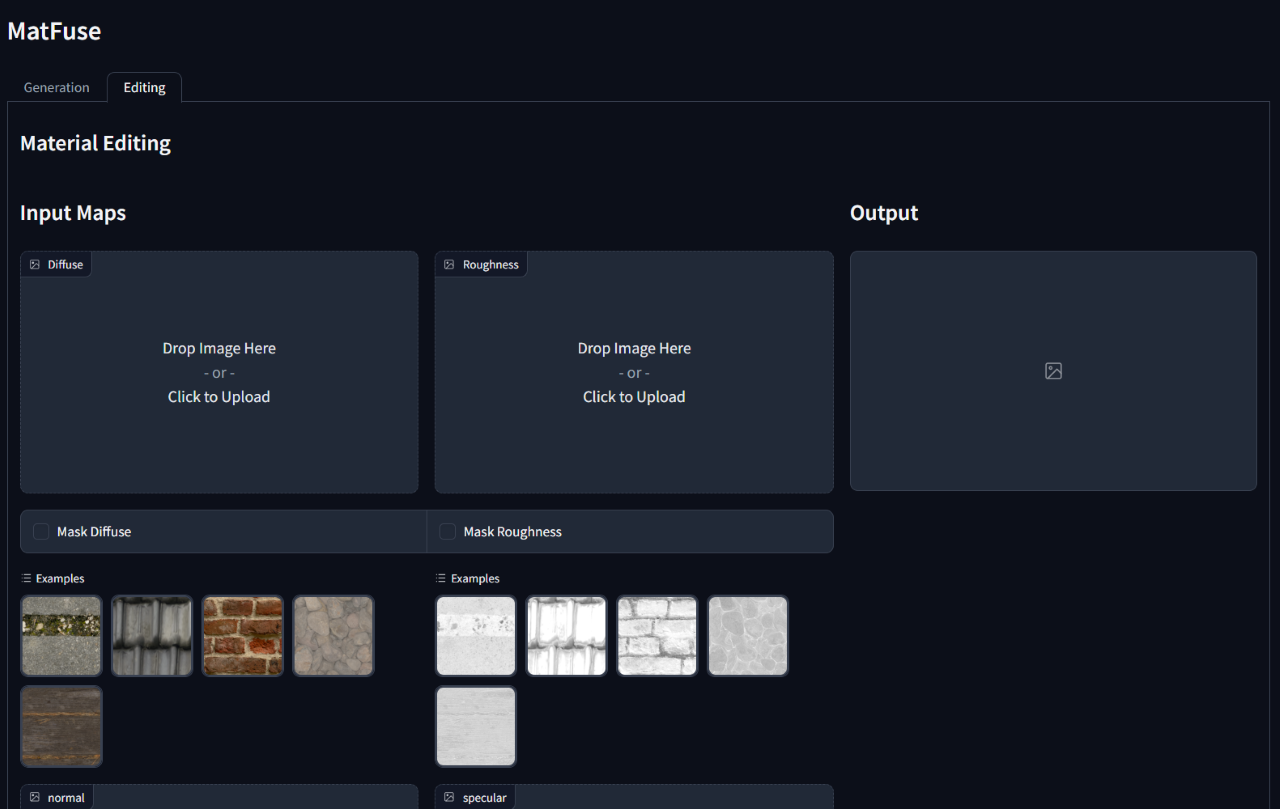
WANDB_ENTITY= ' {YOUR_PROJECT_SPACE_NAME} '要运行训练有素的模型,请运行gradio_app.py脚本,指定了模型检查点和配置的路径。
这将打开网络接口以执行有条件的生成和材料编辑。
python src/gradio_app.py --ckpt < path/to/checkpoint.ckpt > --config src/configs/diffusion/ < config.yaml > 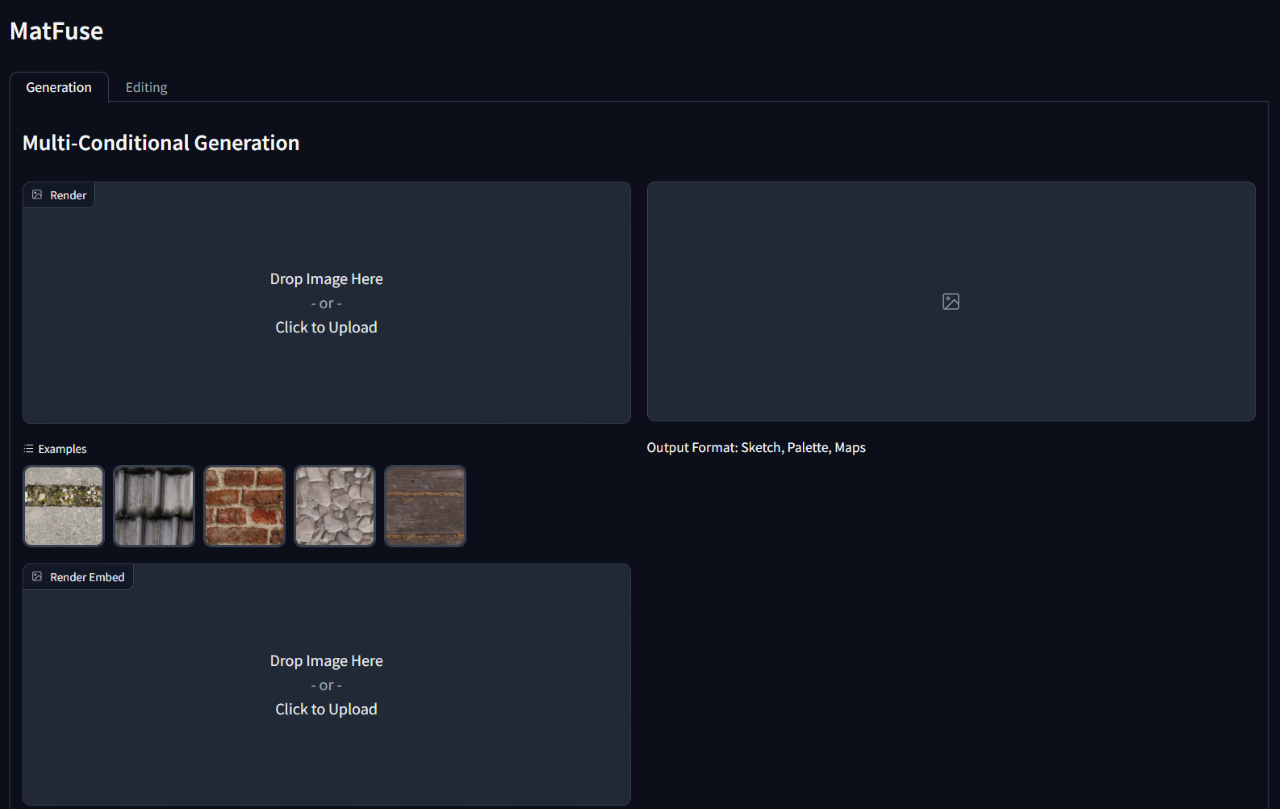
@inproceedings { vecchio2024matfuse ,
author = { Vecchio, Giuseppe and Sortino, Renato and Palazzo, Simone and Spampinato, Concetto } ,
title = { MatFuse: Controllable Material Generation with Diffusion Models } ,
booktitle = { Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
month = { June } ,
year = { 2024 } ,
pages = { 4429-4438 }
}

