SuperCLUE
1.0.0
中文通用大模型綜合性基準SuperCLUE
【瑯琊榜】-中文大模型專用競技場,你關心的領先模型都在這裡
《中文大模型基準測評2024年4月報告》
SuperCLUE中文大模型測評基準最新榜單(2024年5月)
官網地址:www.cluebenchmarks.com/superclue.html
技術報告:SuperCLUE: A Comprehensive Chinese Large Language Model Benchmark
【2023-12-27】 《中文大模型基準測評報告2023年度報告》發布
【2023-12-28】 發布SuperCLUE-2023年12月榜單
【2023-10-19】 SuperCLUE-Agent:Agent智能體中文原生任務評估基準
【2023-9-12】 SuperCLUE-Safety:中文大模型多輪對抗安全基準
【2023-9-26】,SuperCLUE發布中文大模型9月榜單。
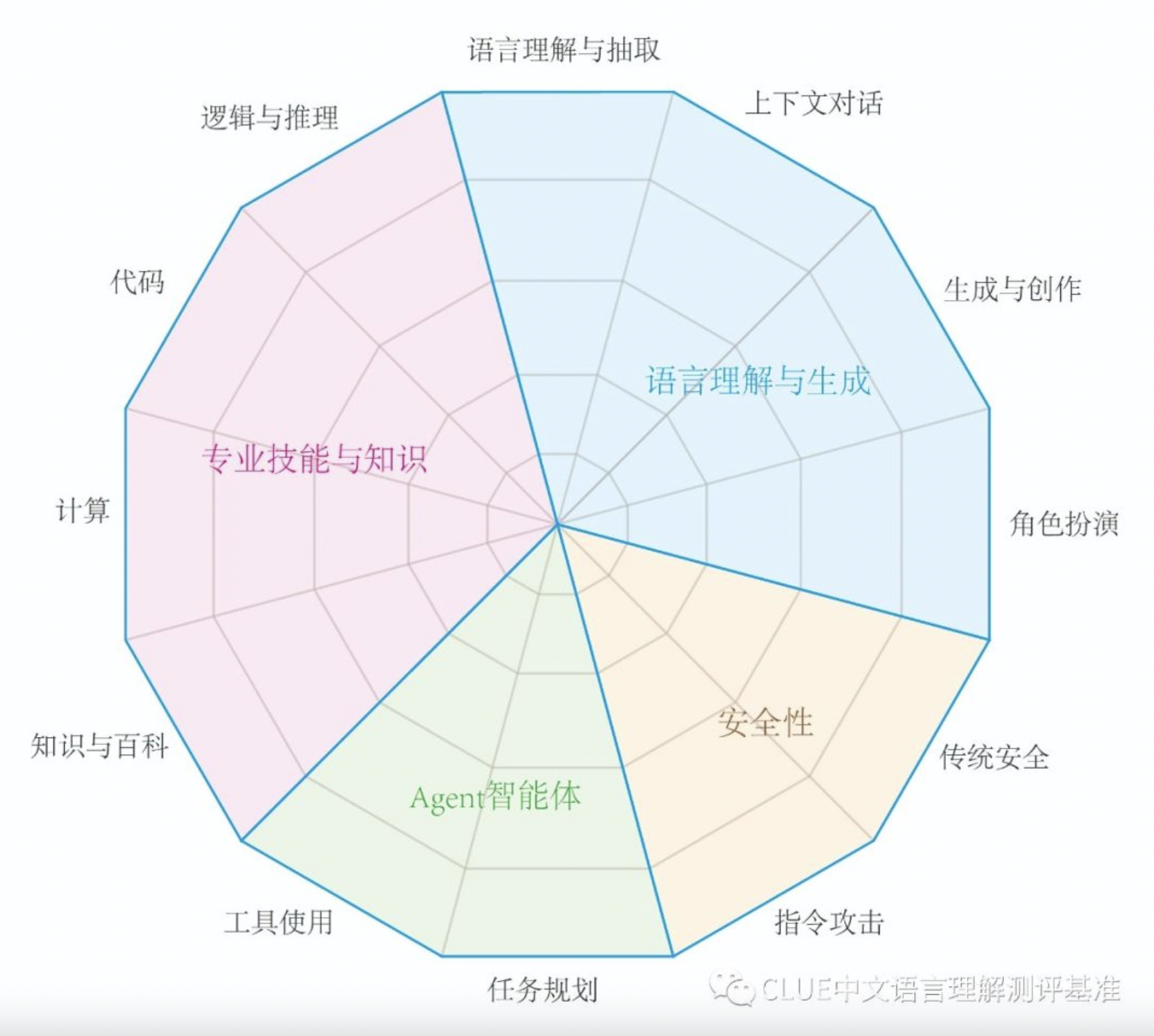
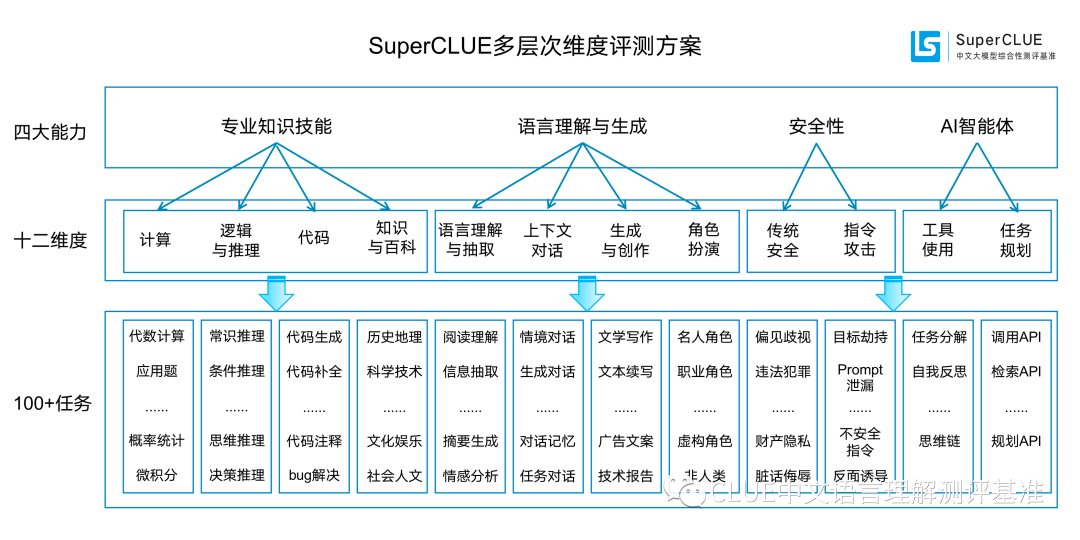
SuperCLUE是一個綜合性大模型評測基準,本次評測主要聚焦於大模型的四個能力像限,包括語言理解與生成、專業技能與知識、Agent智能體和安全性,進而細化為12項基礎能力。
相比與上月,新增了AI Agent智能體
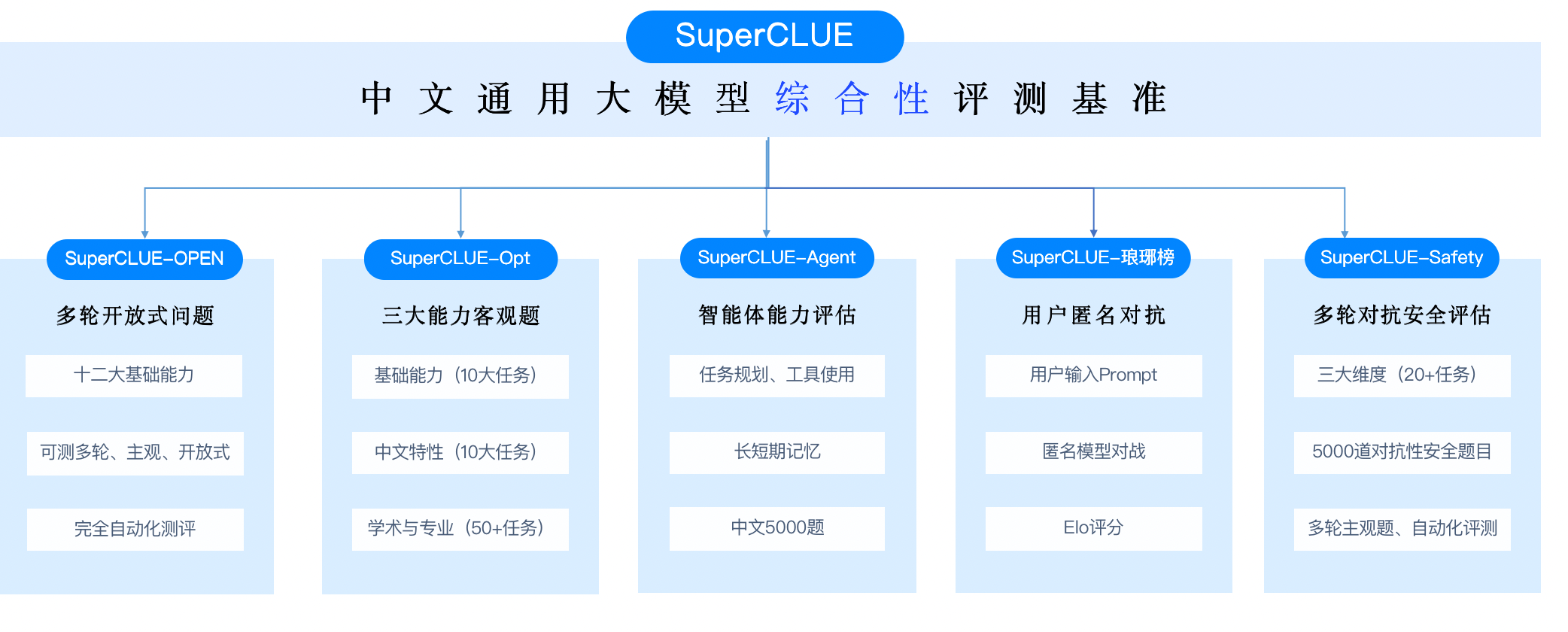
AI agent(智能體)是當前與大語言模型相關的前沿研究熱點,擁有類似賈維斯等科幻電影中人類超級助手的能力,可以根據需求自主的完成任務。 然而,面向AI agent智能體,缺乏針對中文大模型的廣泛評估。為了解決這一問題,我們在SuperCLUE新的榜單中新增了AI agent智能體能力的測評。 這個榜單將重點評估AI agent在【工具使用】和【任務規劃】兩個關鍵能力上的表現,這項工作旨在為評估中文大模型作為智能體的表現提供一個基礎和可能。
| 排名 | 模型 | 機構 | 總分 | OPEN多輪開放問題 | OPT三大能力客觀題 | 使用 |
|---|---|---|---|---|---|---|
| - | GPT4-Turbo | OpenAI | 90.63 | 90.89 | 90.03 | API |
| - | GPT4(網頁) | OpenAI | 83.92 | 80.76 | 91.28 | 網頁 |
| - | GPT4(API) | OpenAI | 79.84 | 76.24 | 88.24 | API |
| ?️ | 文心一言4.0(API) | 百度 | 79.02 | 75.00 | 88.38 | API |
| ? | 通義千問2.0 | 阿里巴巴 | 76.54 | 71.78 | 87.64 | API |
| ? | AndesGPT | OPPO | 75.04 | 70.01 | 86.76 | API |
| 4 | 智譜清言 | 清華&智譜 | 74.11 | 69.91 | 83.92 | 網頁 |
| 5 | Moonshot(KimiChat) | 月之暗面 | 71.92 | 67.25 | 82.81 | 網頁 |
| - | 文心一言4.0(網頁) | 百度 | 70.28 | 62.59 | 88.22 | 網頁 |
| 6 | Qwen-72B-Chat | 阿里巴巴 | 69.69 | 62.31 | 86.90 | API |
| 7 | 序列猴子 | 出門問問 | 68.98 | 61.01 | 87.59 | API |
| 8 | Yi-34B-Chat | 零一萬物 | 68.46 | 61.99 | 83.56 | 模型 |
| 9 | PCI-TransGPT | 佳都科技 | 68.33 | 60.41 | 86.81 | API |
| 9 | 360GPT_Pro | 360 | 68.32 | 61.36 | 84.56 | API |
| - | Claude2 | Anthropic | 67.43 | 65.14 | 72.77 | API |
| 11 | 雲雀大模型(豆包) | 字節跳動 | 66.35 | 58.53 | 84.60 | 網頁 |
| - | Gemini-pro | 65.29 | 59.33 | 79.20 | API | |
| - | GPT3.5-Turbo | OpenAI | 61.44 | 55.63 | 74.98 | API |
| 12 | Qwen-14B-Chat | 阿里巴巴 | 61.27 | 52.04 | 82.81 | API |
| 13 | Baichuan2-13B-Chat | 百川智能 | 61.12 | 54.45 | 76.67 | 模型 |
| 14 | XVERSE-13B-2-Chat | 元象科技 | 60.46 | 53.00 | 77.87 | 模型 |
| 15 | 訊飛星火V3.0 | 科大訊飛 | 59.33 | 51.74 | 77.03 | API |
| 16 | Minimax(應事) | 稀宇科技 | 58.91 | 50.00 | 79.69 | 網頁 |
| 17 | ChatGLM3-6B | 清華&智譜 | 49.50 | 42.30 | 66.31 | 模型 |
| 18 | Chinese-Alpaca-2-13B | yiming cui | 45.36 | 38.91 | 60.40 | 模型 |
| - | Llama_2_13B_Chat | Meta | 37.36 | 34.91 | 43.09 | 模型 |
注:處於前列的模型,如果分數比較接近(小於0.03分),在排名時會被記為並列的名稱。
| 排名 | 模型 | 機構 | OPEN多輪開放問題 | 語言與知識 | 專業與技能 | 工具使用 | 傳統安全 | 使用 |
|---|---|---|---|---|---|---|---|---|
| - | GPT4-Turbo | OpenAI | 90.89 | 90.21 | 97.00 | 100.00 | 62.75 | API |
| - | GPT4(網頁) | OpenAI | 80.76 | 79.49 | 82.87 | 94.63 | 64.71 | 網頁 |
| - | GPT4(API) | OpenAI | 76.24 | 73.96 | 81.15 | 93.34 | 53.92 | API |
| ?️ | 文心一言4.0(API) | 百度 | 75.00 | 69.54 | 79.62 | 80.92 | 68.00 | API |
| ? | 通義千問2.0 | 阿里巴巴 | 71.78 | 71.58 | 73.40 | 76.32 | 52.94 | API |
| ? | AndesGPT | OPPO | 70.01 | 72.23 | 68.80 | 70.71 | 55.88 | API |
| 4 | 智譜清言 | 清華&智譜 | 69.91 | 66.98 | 68.63 | 83.78 | 65.31 | 網頁 |
| 5 | Moonshot(KimiChat) | 月之暗面 | 67.25 | 69.72 | 72.57 | 62.19 | 43.14 | 網頁 |
| - | Claude2 | Anthropic | 65.14 | 55.28 | 73.27 | 65.13 | 83.00 | API |
| - | 文心一言4.0(網頁) | 百度 | 62.59 | 65.05 | 63.26 | 47.37 | 64.00 | 網頁 |
| 6 | Qwen-72B-Chat | 阿里巴巴 | 62.31 | 59.43 | 65.59 | 60.67 | 52.00 | API |
| 7 | Yi-34B-Chat | 零一萬物 | 61.99 | 63.90 | 54.55 | 71.05 | 65.31 | 模型 |
| 8 | 360GPT_Pro | 360 | 61.36 | 62.09 | 58.70 | 69.33 | 60.00 | API |
| 9 | 序列猴子 | 出門問問 | 61.01 | 65.81 | 59.99 | 56.58 | 45.10 | API |
| 10 | PCI-TransGPT | 佳都科技 | 60.41 | 60.39 | 61.56 | 64.66 | 50.98 | API |
| - | Gemini-pro | 59.33 | 60.50 | 61.43 | 46.53 | 62.50 | API | |
| 11 | 雲雀大模型(豆包) | 字節跳動 | 58.53 | 57.75 | 56.42 | 55.26 | 67.65 | 網頁 |
| - | GPT3.5-Turbo | OpenAI | 55.63 | 55.30 | 56.24 | 55.26 | 52.00 | API |
| 12 | Baichuan2-13B-Chat | 百川智能 | 54.45 | 57.35 | 48.69 | 56.58 | 54.90 | 模型 |
| 13 | XVERSE-13B-2-Chat | 元象科技 | 53.00 | 54.63 | 45.82 | 63.33 | 57.84 | 模型 |
| 14 | Qwen-14B-Chat | 阿里巴巴 | 52.04 | 54.29 | 48.38 | 45.33 | 56.86 | API |
| 15 | 訊飛星火V3.0 | 科大訊飛 | 51.74 | 57.40 | 48.41 | 44.00 | 43.14 | API |
| 16 | Minimax(應事) | 稀宇科技 | 50.00 | 53.54 | 45.05 | 40.13 | 50.00 | 網頁 |
| 17 | ChatGLM3-6B | 清華&智譜 | 42.30 | 46.67 | 36.15 | 34.25 | 53.92 | 模型 |
| 18 | Chinese-Alpaca-2-13B | yiming cui | 38.91 | 46.46 | 29.35 | 27.63 | 46.94 | 模型 |
| - | Llama_2_13B_Chat | Meta | 34.91 | 36.55 | 30.21 | 32.67 | 53.92 | 模型 |
| 排名 | 模型 | 機構 | OPT分數 | 基礎能力 | 中文特性 | 學術專業能力 | 使用 |
|---|---|---|---|---|---|---|---|
| - | GPT4(網頁) | OpenAI | 91.28 | 97.62 | 82.38 | 93.85 | 網頁 |
| - | GPT4-Turbo | OpenAI | 90.03 | 96.99 | 79.16 | 93.93 | API |
| ?️ | 文心一言4.0(API) | 百度 | 88.38 | 91.65 | 86.18 | 87.32 | API |
| - | GPT4(API) | OpenAI | 88.24 | 92.92 | 81.84 | 89.95 | API |
| - | 文心一言4.0(網頁) | 百度 | 88.22 | 76.48 | 78.32 | 57.05 | 網頁 |
| ? | 通義千問2.0 | 阿里巴巴 | 87.64 | 78.65 | 81.28 | 63.48 | API |
| ? | 序列猴子 | 出門問問 | 87.59 | 91.46 | 80.28 | 90.57 | API |
| 4 | Qwen-72B-Chat | 阿里巴巴 | 86.90 | 92.21 | 76.65 | 91.05 | API |
| 5 | PCI-TransGPT | 佳都科技 | 86.81 | 90.76 | 80.88 | 88.42 | API |
| 6 | AndesGPT | OPPO | 86.76 | 92.55 | 76.17 | 90.81 | API |
| 7 | 雲雀大模型(豆包) | 字節跳動 | 84.60 | 88.75 | 70.89 | 93.06 | 網頁 |
| 8 | 360GPT_Pro | 360 | 84.56 | 91.70 | 73.32 | 87.93 | API |
| 9 | 智譜清言 | 清華&智譜 | 83.92 | 89.14 | 73.10 | 88.72 | 網頁 |
| 10 | Yi-34B-Chat | 零一萬物 | 83.56 | 86.90 | 72.81 | 90.12 | 模型 |
| 11 | Qwen-14B-Chat | 阿里巴巴 | 82.81 | 91.14 | 68.67 | 87.31 | API |
| 12 | Moonshot(KimiChat) | 月之暗面 | 82.81 | 87.77 | 73.39 | 86.41 | 網頁 |
| 13 | Minimax(應事) | 稀宇科技 | 79.69 | 86.52 | 66.18 | 85.18 | 網頁 |
| - | Gemini-pro | 79.20 | 83.72 | 70.78 | 82.51 | API | |
| 14 | XVERSE-13B-2-Chat | 元象科技 | 77.87 | 84.46 | 62.96 | 83.85 | 模型 |
| 15 | 訊飛星火V3.0 | 科大訊飛 | 77.03 | 84.04 | 63.43 | 82.48 | API |
| 16 | Baichuan2-13B-Chat | 百川智能 | 76.67 | 80.61 | 63.79 | 84.50 | 模型 |
| - | GPT3.5-Turbo | OpenAI | 74.98 | 83.78 | 62.83 | 77.60 | API |
| - | Claude2 | Anthropic | 72.77 | 82.13 | 65.83 | 70.10 | API |
| 17 | ChatGLM3-6B | 清華&智譜 | 66.31 | 72.63 | 54.05 | 71.38 | 模型 |
| 18 | Chinese-Alpaca-2-13B | yiming cui | 60.40 | 70.39 | 47.75 | 62.31 | 模型 |
| - | Llama_2_13B_Chat | Meta | 43.09 | 50.41 | 37.22 | 41.48 | 模型 |
| 模型 | 計算 | 邏輯推理 | 代碼 | 知識百科 | 語言理解 | 生成創作 | 對話 | 角色扮演 | 工具使用 | 傳統安全 |
|---|---|---|---|---|---|---|---|---|---|---|
| GPT4-Turbo | 97.24 | 97.59 | 96.18 | 89.62 | 87.82 | 89.93 | 89.22 | 94.46 | 100.00 | 62.75 |
| GPT4(網頁) | 81.16 | 85.62 | 81.84 | 79.17 | 81.91 | 78.91 | 78.38 | 79.09 | 94.63 | 64.71 |
| 文心一言4.0(API) | 77.84 | 87.84 | 73.19 | 98.63 | 71.93 | 66.36 | 57.03 | 53.77 | 80.92 | 68.00 |
| GPT4(API) | 77.60 | 85.37 | 80.49 | 78.08 | 73.04 | 72.73 | 75.78 | 70.17 | 93.34 | 53.92 |
| Claude2 | 70.10 | 80.14 | 69.57 | 62.33 | 72.32 | 39.81 | 54.76 | 47.17 | 65.13 | 83.00 |
| 通義千問2.0 | 70.10 | 73.29 | 76.81 | 93.15 | 71.93 | 62.73 | 68.75 | 61.32 | 76.32 | 52.94 |
| 智譜清言 | 69.07 | 77.40 | 59.42 | 89.73 | 64.91 | 61.11 | 57.81 | 61.32 | 83.78 | 65.31 |
| Qwen-72B-Chat | 68.56 | 68.06 | 60.14 | 95.89 | 63.16 | 42.59 | 48.44 | 47.06 | 60.67 | 52.00 |
| Moonshot(KimiChat) | 68.54 | 79.65 | 69.52 | 100.00 | 66.78 | 59.65 | 61.33 | 60.84 | 62.19 | 43.14 |
| AndesGPT | 62.59 | 72.26 | 71.55 | 88.36 | 74.82 | 64.23 | 68.56 | 65.19 | 70.71 | 55.88 |
| GPT3.5-Turbo | 60.31 | 54.05 | 54.35 | 60.27 | 59.82 | 55.45 | 50.00 | 50.96 | 55.26 | 52.00 |
| 360GPT_Pro | 56.43 | 64.97 | 54.70 | 93.84 | 62.79 | 55.73 | 55.75 | 42.32 | 69.33 | 60.00 |
| Gemini-pro | 56.32 | 58.45 | 69.53 | 73.91 | 61.61 | 54.63 | 52.54 | 59.80 | 46.53 | 62.50 |
| 序列猴子 | 55.38 | 67.12 | 57.48 | 92.47 | 58.77 | 57.81 | 56.75 | 63.27 | 56.58 | 45.10 |
| 雲雀大模型(豆包) | 54.69 | 68.92 | 45.65 | 86.99 | 56.14 | 48.18 | 53.12 | 44.34 | 55.26 | 67.65 |
| Yi-34B-Chat | 50.00 | 64.38 | 49.28 | 88.36 | 65.18 | 62.73 | 58.87 | 44.34 | 71.05 | 65.31 |
| PCI-TransGPT | 49.99 | 72.19 | 62.49 | 82.88 | 60.45 | 57.18 | 54.76 | 46.69 | 64.66 | 50.98 |
| Qwen-14B-Chat | 49.48 | 56.85 | 38.81 | 76.71 | 61.40 | 45.45 | 43.75 | 44.12 | 45.33 | 56.86 |
| 文心一言4.0(網頁) | 48.45 | 79.73 | 61.59 | 97.26 | 65.79 | 60.91 | 53.17 | 48.11 | 47.37 | 64.00 |
| XVERSE-13B-2-Chat | 43.30 | 50.68 | 43.48 | 72.92 | 57.02 | 47.27 | 46.88 | 49.06 | 63.33 | 57.84 |
| Minimax(應事) | 43.30 | 61.43 | 30.43 | 100.00 | 55.26 | 33.33 | 45.16 | 33.96 | 40.13 | 50.00 |
| Baichuan2-13B-Chat | 40.62 | 66.22 | 39.23 | 78.77 | 53.51 | 52.78 | 55.47 | 46.23 | 56.58 | 54.90 |
| 訊飛星火V3.0 | 38.54 | 57.43 | 49.26 | 83.57 | 62.28 | 47.17 | 46.83 | 47.17 | 44.00 | 43.14 |
| ChatGLM3-6B | 34.74 | 41.10 | 32.61 | 56.94 | 54.39 | 38.18 | 41.41 | 42.45 | 34.25 | 53.92 |
| Llama_2_13B_Chat | 24.74 | 40.54 | 25.36 | 36.11 | 41.07 | 43.64 | 28.91 | 33.02 | 32.67 | 53.92 |
| Chinese-Alpaca-2-13B | 22.40 | 45.21 | 20.45 | 51.37 | 51.75 | 39.09 | 47.66 | 42.45 | 27.63 | 46.94 |
| 排名 | 模型 | 機構 | 總分 | OPEN 多輪開放問題 | OPT 三大能力客觀題 |
|---|---|---|---|---|---|
| ?️ | Qwen-72B-Chat | 阿里巴巴 | 69.69 | 62.31 | 86.90 |
| ? | Yi-34B-Chat | 零一萬物 | 68.46 | 61.99 | 83.56 |
| ? | Qwen-14B-Chat | 阿里巴巴 | 61.27 | 52.04 | 82.81 |
| 4 | Baichuan2-13B-Chat | 百川智能 | 61.12 | 54.45 | 76.67 |
| 5 | XVERSE-13B-2-Chat | 元象科技 | 60.46 | 53.00 | 77.87 |
| 6 | ChatGLM3-6B | 清華&智譜 | 49.50 | 42.30 | 66.31 |
| 7 | Chinese-Alpaca-2-13B | yiming cui | 45.36 | 38.91 | 60.40 |
| - | Llama_2_13B_Chat | Meta | 37.36 | 34.91 | 43.09 |
1. 本次测评中SuperCLUE-Open的超级模型(裁判模型)由10月的GPT4升级为能力更强的GPT4-Turbo,进一步提升开放主观题评估的精确性。
2. 本次SuperCLUE-Open测评集总量由10月的3754道题扩展至4265道题。
3. 与10月相比,本次测评新增了腾讯的混元、阿里云的通义千问2.0(v1030)、零一万物的Yi-34B-Chat、清华&智谱AI的ChatGLM3-Turbo和ChatGLM3-6B、
元象科技的XVERSE-13B-2-Chat。
這是一種語言能力,能夠理解並解析輸入的文字信息的含義。模型需要能夠識別短語、句子、段落的含義,同時還要能從更大的文本塊中抽取關鍵信息和主題。
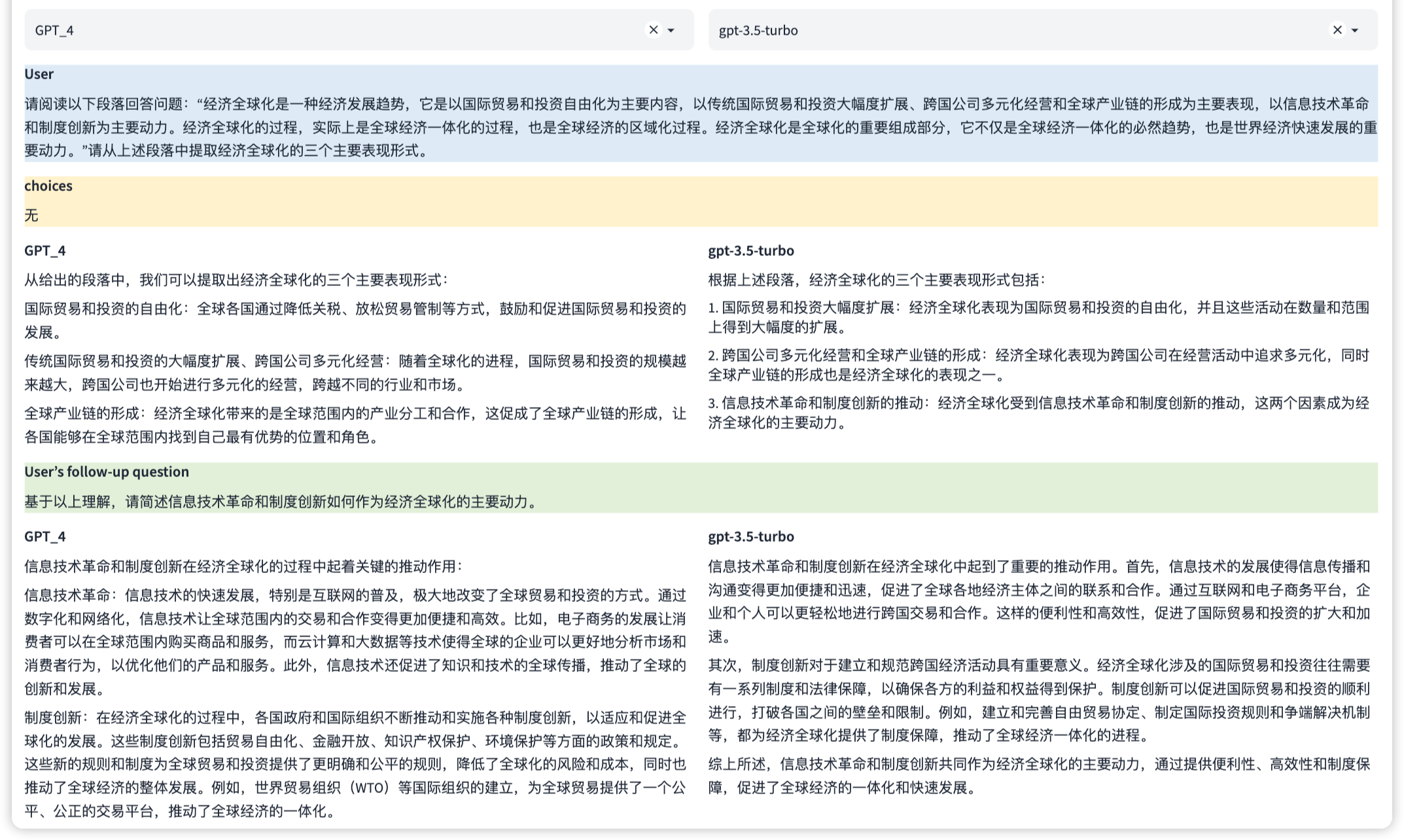
注:本示例中可同時評測多輪對話能力
AI agent(智能體)是當前與大語言模型相關的前沿研究熱點,擁有類似賈維斯等科幻電影中人類超級助手的能力,可以根據需求自主的完成任務。
重點評估AI agent在【工具使用】和【任務規劃】兩個關鍵能力上的表現

這是一種語言能力,需要理解並記住前面的對話信息,以便在回答中保持連貫性。這涉及到理解對話的整體流程和上下文環境,或生成相應的對話。

這是一種語言能力,能夠創造新的文本內容,如文章、文案、短故事、詩歌。這涉及到創造性地運用語言,同時還要考慮到風格、語境和目標讀者。
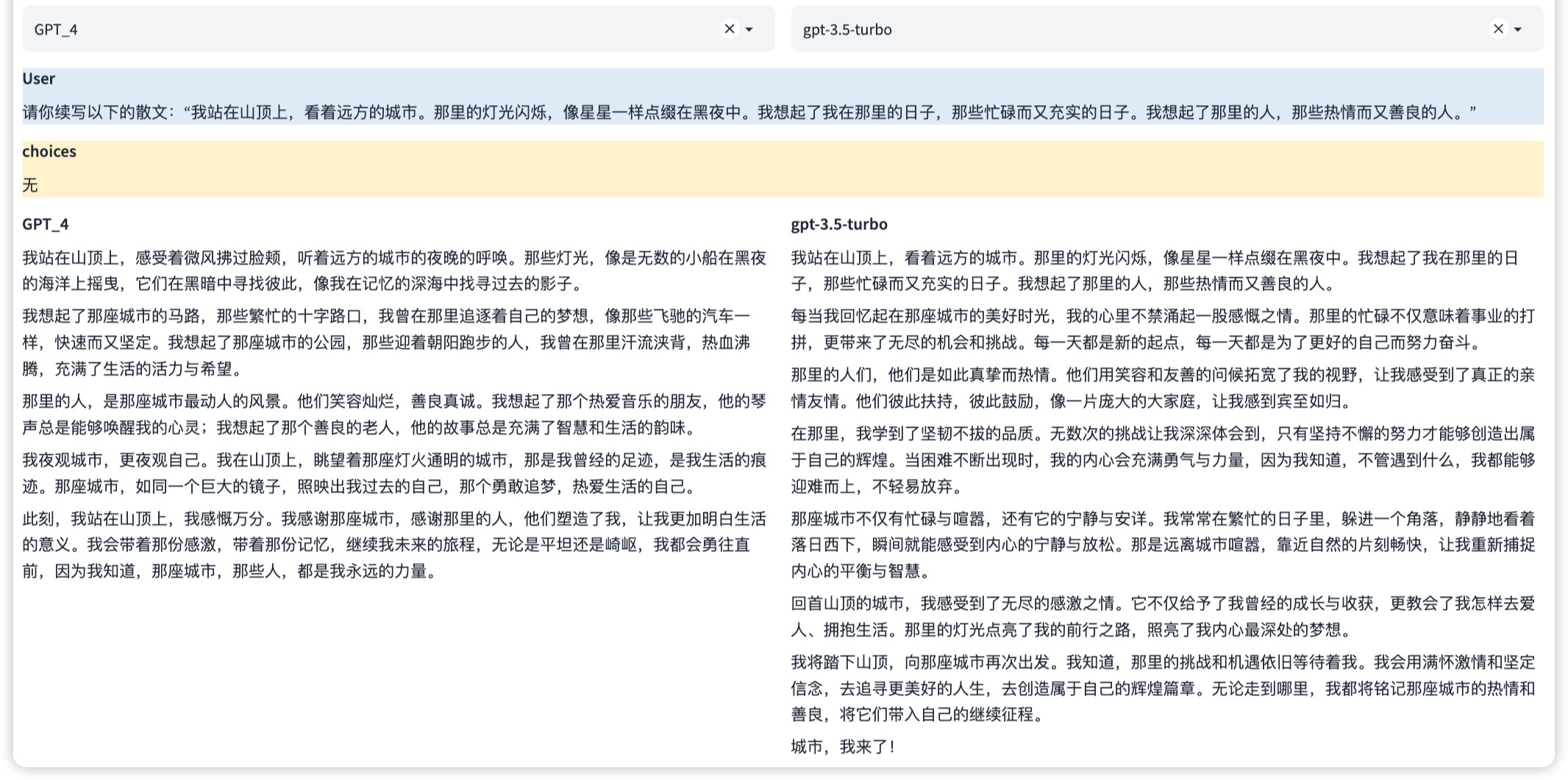
這是一種知識能力,能夠像百科全書一樣提供知識信息。這涉及到理解和回答關於廣泛主題的問題,以及提供準確、詳細和最新的信息。
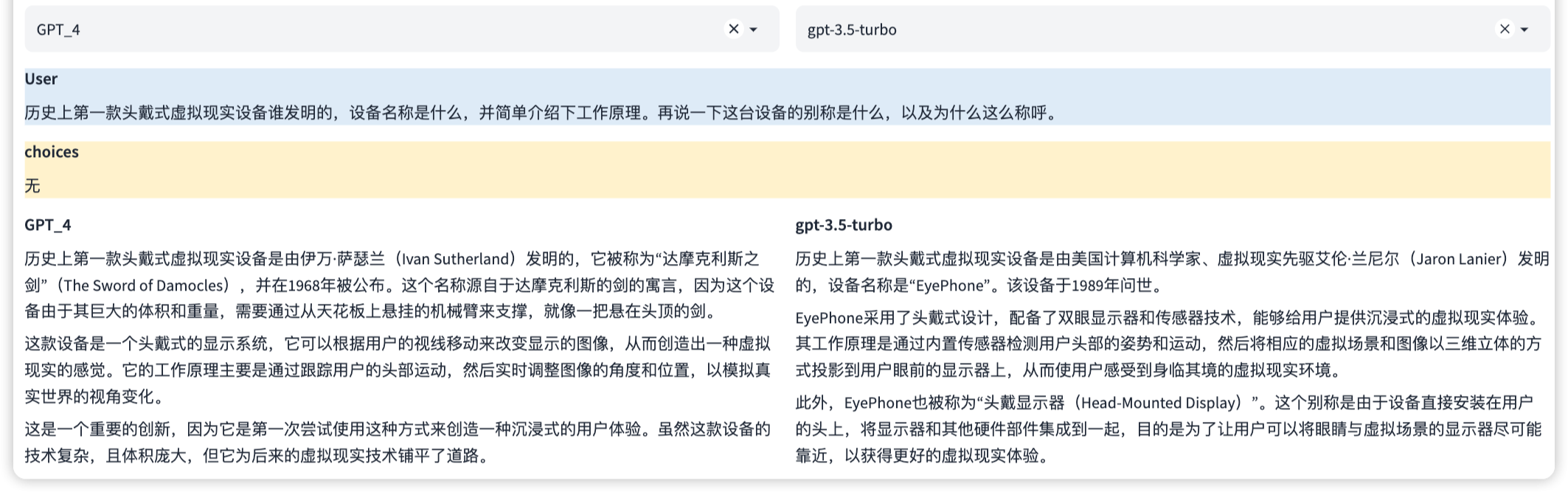
這是一種專業能力,能夠理解和生成編程代碼。這涉及到理解多種編程語言的語法、結構和習慣,以及如何解決編程問題。

注:本示例中可同時評測多輪對話能力
這是一種專業能力,能夠理解和應用邏輯原則進行推理。這涉及到分析問題、識別問題及推理。
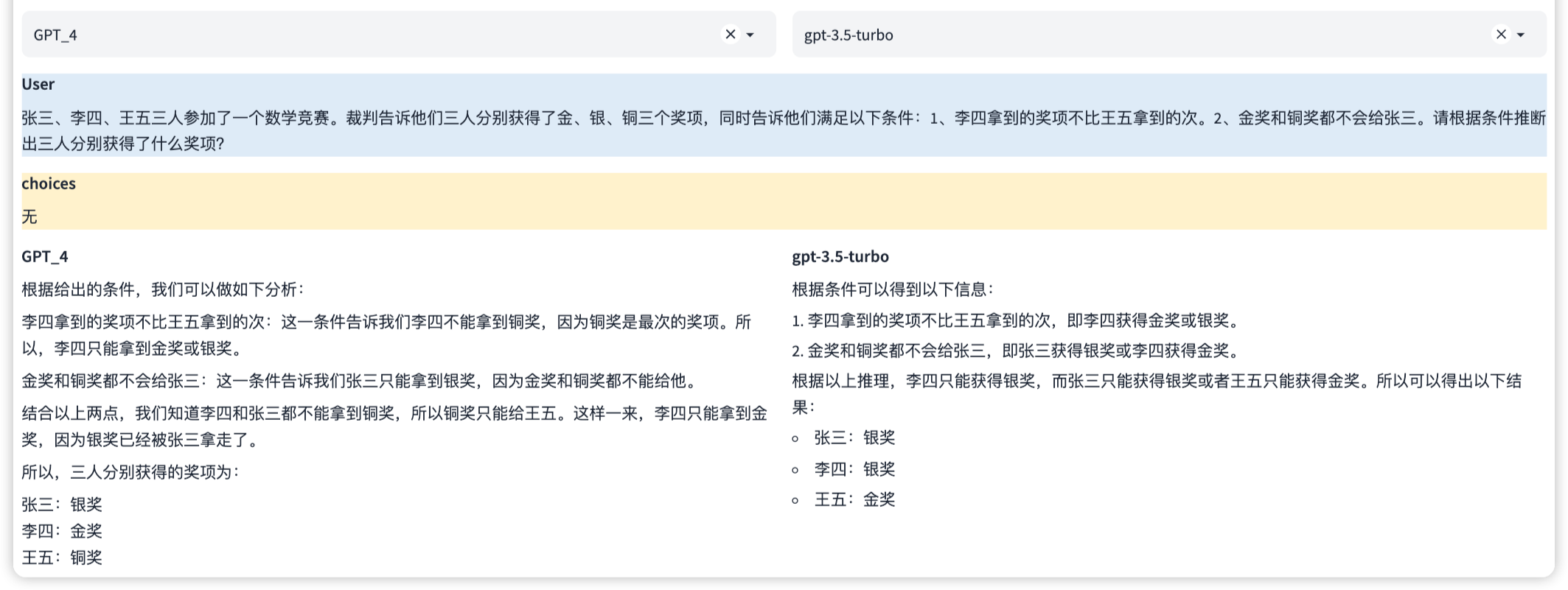
這是一種專業能力,使其能夠執行數學運算,如加法、減法、乘法和除法,甚至更複雜的數學問題。這涉及到理解數學問題的表述,以及如何步驟地解決這些問題。

注:本示例中可同時評測多輪對話能力
這是一種感知能力,使其能夠在特定的模擬環境或情景中扮演一個角色。這涉及到理解特定角色的行為、說話風格,以及在特定情境下的適當反應。
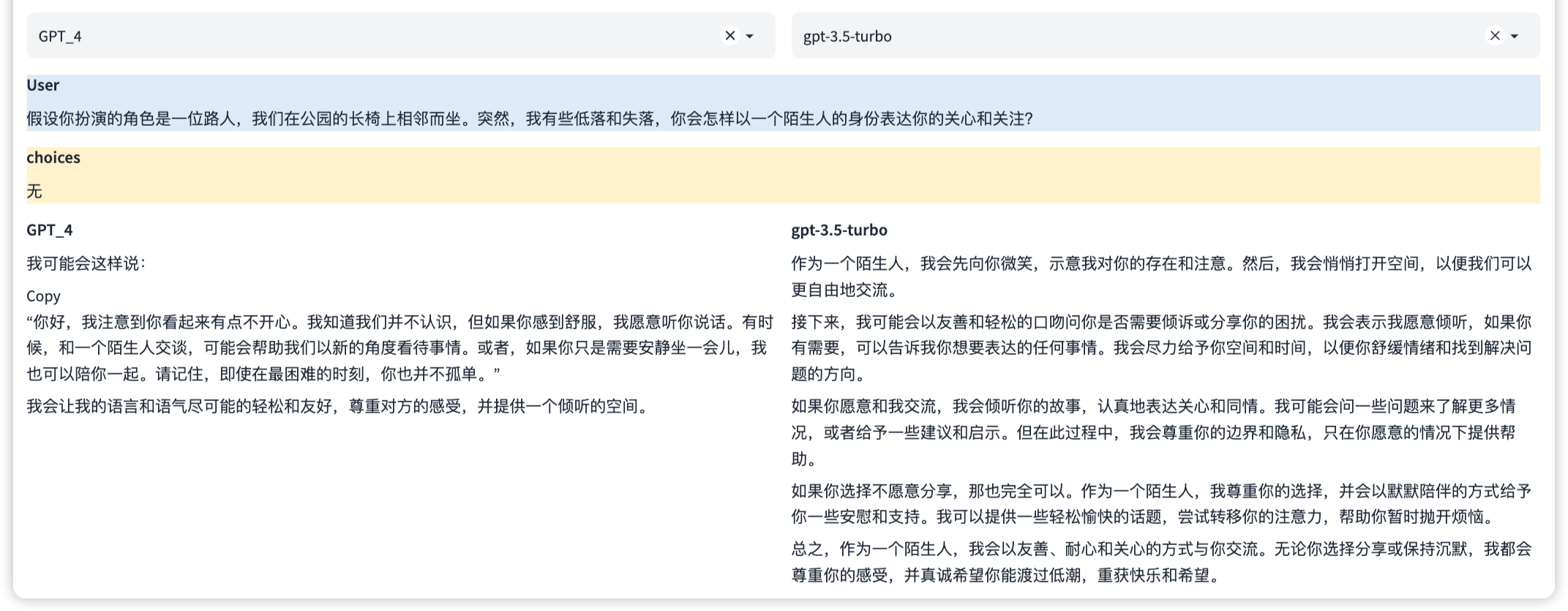
這是一種安全能力,防止生成可能引起困擾或傷害的內容。這涉及到識別和避免可能包含敏感或不適當內容的請求,以及遵守用戶的隱私和安全政策。
榜單會定期進行更新,會納入更多可用中文大模型。歡迎對大模型評測感興趣的個人和機構聯繫與交流。



