pgroll
v0.8.0
pgroll是一种开源命令行工具,通过同时提供多个模式版本,为PostgreSQL提供安全且可逆的模式迁移。它需要照顾复杂的迁移操作,以确保在更新数据库架构时客户应用程序继续工作。这包括确保在不锁定数据库的情况下应用更改,并且新架构版本同时起作用(即使进行断裂更改也可以进行!)。这消除了与模式迁移相关的风险,并大大简化了客户端应用程序的推出,还允许即时回滚。
有关pgroll解决的问题,请参见介绍性博客文章。
pgroll通过在物理表顶部使用视图来创建虚拟模式来创建虚拟模式。这允许执行迁移所需的所有必要更改,而不会影响现有客户。
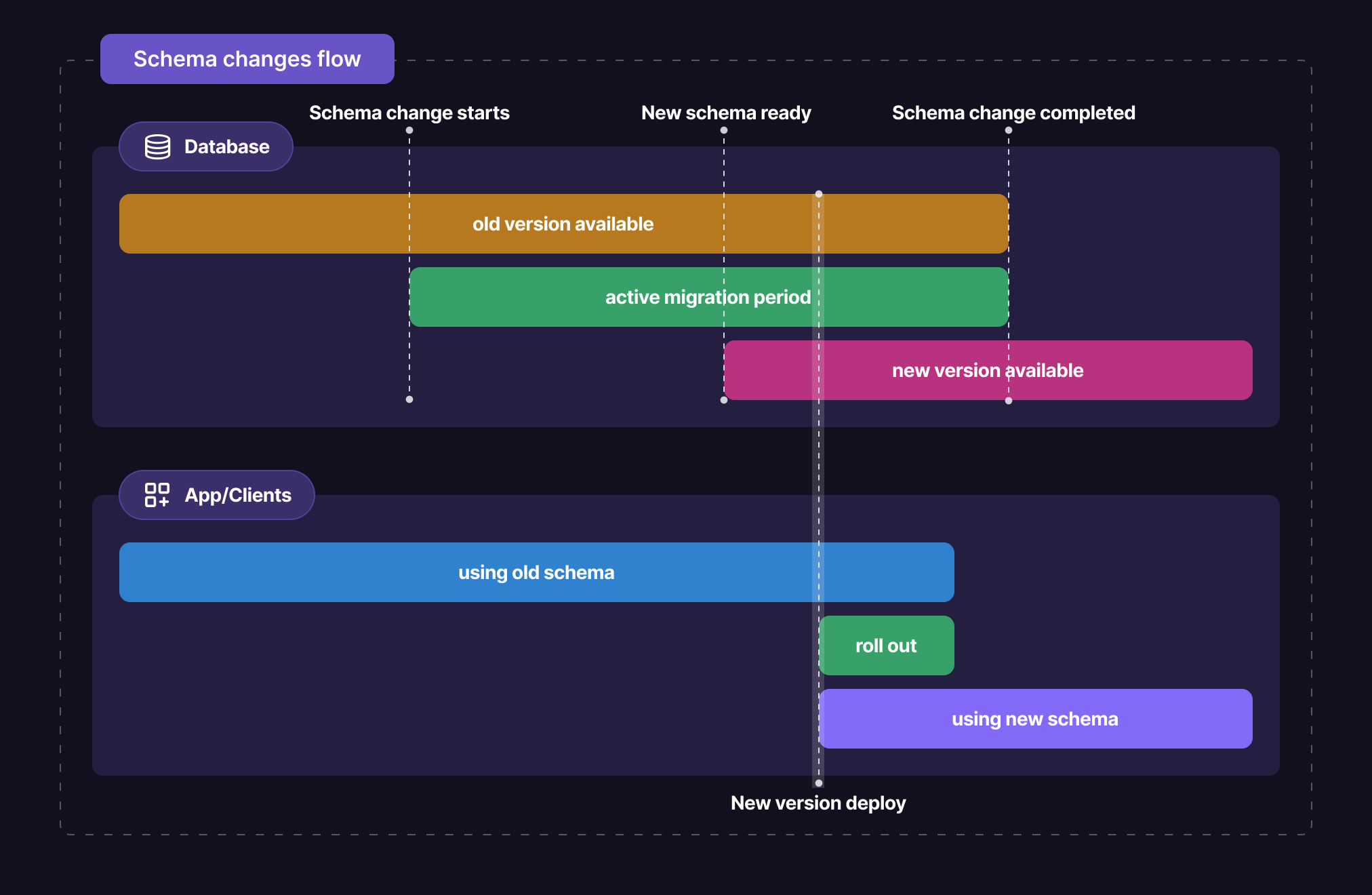
pgroll遵循扩展/合同工作流程。在迁移开始时,它将在物理模式中执行所有加法更改(创建表,添加列等),而不会破坏它。
当列在列上需要打破变化时,它将在物理模式中创建一个新列,并从旧列中回填。另外,配置触发器以确保在整个主动迁移期间都将所有写入旧/新列都会传播到其对应物。然后,新列将在新版本的架构中公开。
一旦开始阶段完成,就可以准备好新的架构版本,将所有视图映射到适当的表格和列。然后,客户端应用程序可以访问新的模式版本,而旧版本仍然可用。这是开始推出客户应用程序的新版本的时刻。
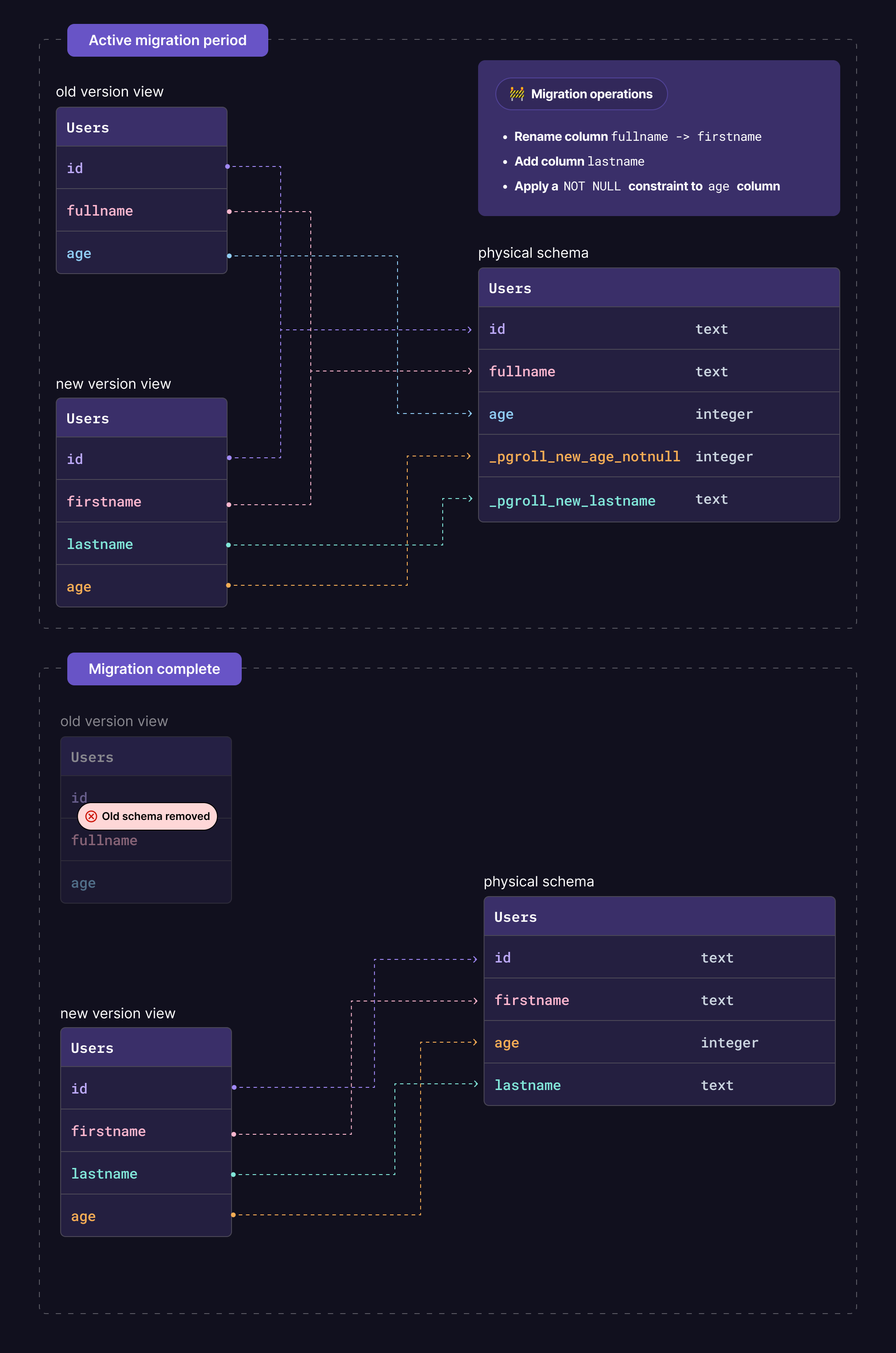
如果没有更多的客户端应用程序使用旧模式版本,则可以完成迁移。这将删除旧模式,而新模式将是唯一可用的模式。将不再需要删除所需的表和列(目前没有客户使用此列表),并且新的名称将重命名为最终名称。在此阶段,客户端应用程序仍在工作,因为视图仍在映射到适当的表和列。
二进制文件可用于Linux,MacOS和Windows,检查我们的版本。
要从源安装pgroll ,请运行以下命令:
go install github.com/xataio/pgroll@latest注意:需要1.23或更高版本。
要与Homebrew一起安装pgroll ,请运行以下命令:
# macOS or Linux
brew tap xataio/pgroll
brew install pgroll请按照以下步骤使用pgroll执行您的第一个模式迁移:
pgroll需要在数据库中存储一些内部状态。创建表可跟踪当前的模式版本和存储版本历史记录。要准备数据库,请运行以下命令:
pgroll init --postgres-url postgres://user:password@host:port/dbname创建一个迁移文件。您可以检查示例文件夹以获取一些示例。例如,使用此迁移文件创建一个新customers表:
{
"name" : " initial_migration " ,
"operations" : [
{
"create_table" : {
"name" : " customers " ,
"columns" : [
{
"name" : " id " ,
"type" : " integer " ,
"pk" : true
},
{
"name" : " name " ,
"type" : " varchar(255) " ,
"unique" : true
},
{
"name" : " bio " ,
"type" : " text " ,
"nullable" : true
}
]
}
}
]
}然后运行以下命令开始迁移:
pgroll --postgres-url postgres://user:password@host:port/dbname start initial_migration.json这将在数据库中创建一个新的模式版本,并应用迁移操作(创建表)。完成此命令后,旧版本的架构(没有客户表)和新版本(带有客户表)都可以同时访问。
启动迁移后,客户端应用程序可以开始使用新的模式版本。为了这样做,需要将它们配置为访问它。可以通过将search_path设置为新的架构版本名称(由pgroll start输出提供)来完成:例如:
SET search_path TO ' public_initial_migration ' ;一旦使用旧架构版本没有更多的客户端应用程序,就可以完成迁移。这将删除旧模式。要完成迁移,请运行以下命令:
pgroll --postgres-url postgres://user:password@host:port/dbname complete在迁移期间的任何时候,都可以回到上一个版本。这将删除新的模式,并像迁移开始之前一样将旧模式留下来。要回滚迁移,请运行以下命令:
pgroll --postgres-url postgres://user:password@host:port/dbname rollback有关更高级的用法,教程和详细选项,请参阅文档中的指南和参考。
每项提交main都会运行一些性能基准,以便随着时间的推移跟踪性能。每个基准测试都对Postgres 14.8、15.3、16.4、17.0和“最新”。图表上的每一行代表基准的行数,目前为10k,100k和300k行。
Backfill:行以价值placeholder的文本列进行回填。我们使用每批10K行的默认批处理策略,而没有退缩。WriteAmplification/NoTrigger:基线行/s在没有pgroll触发的情况下将数据写入表。pgroll触发器时,将数据写入表时WriteAmplification/WithTrigger:行/s。ReadSchema:检查read_schema函数的每秒执行次数,该函数是在迁移过程中经常执行的核心函数。他们可以在这里看到。
我们欢迎社区的捐款!如果您想为pgroll做出贡献,请遵循以下准则:
对于这个项目,我们承诺采取行动和互动,以有助于开放,热情,多样,包容和健康的社区。
这是有助于灵感的项目和文章的列表,或者与pgroll相似:
该项目已根据Apache许可证2.0的许可 - 有关详细信息,请参见许可证文件。
如果您有任何疑问,遇到问题或需要帮助,请在此存储库中打开一个问题,我们加入我们的不和谐,我们的社区将很乐意提供帮助。
由Xata用❤️制成?


