pgroll
v0.8.0
pgroll est un outil de ligne de commande open source qui propose des migrations de schéma sûres et réversibles pour PostgreSQL en servant plusieurs versions de schéma simultanément. Il s'occupe des opérations de migration complexes pour s'assurer que les applications client continuent de fonctionner pendant que le schéma de la base de données est mis à jour. Cela comprend la garantie de modifications appliquées sans verrouiller la base de données, et que les versions de schéma ancien et nouveaux fonctionnent simultanément (même lorsque des changements de rupture sont apportés!). Cela supprime les risques liés aux migrations de schéma et simplifie considérablement le déploiement des applications du client, permettant également des reculs.
Voir le billet de blog d'introduction pour en savoir plus sur les problèmes résolus par pgroll .
pgroll fonctionne en créant des schémas virtuels en utilisant des vues au-dessus des tables physiques. Cela permet d'effectuer tous les changements nécessaires nécessaires à une migration sans affecter les clients existants.
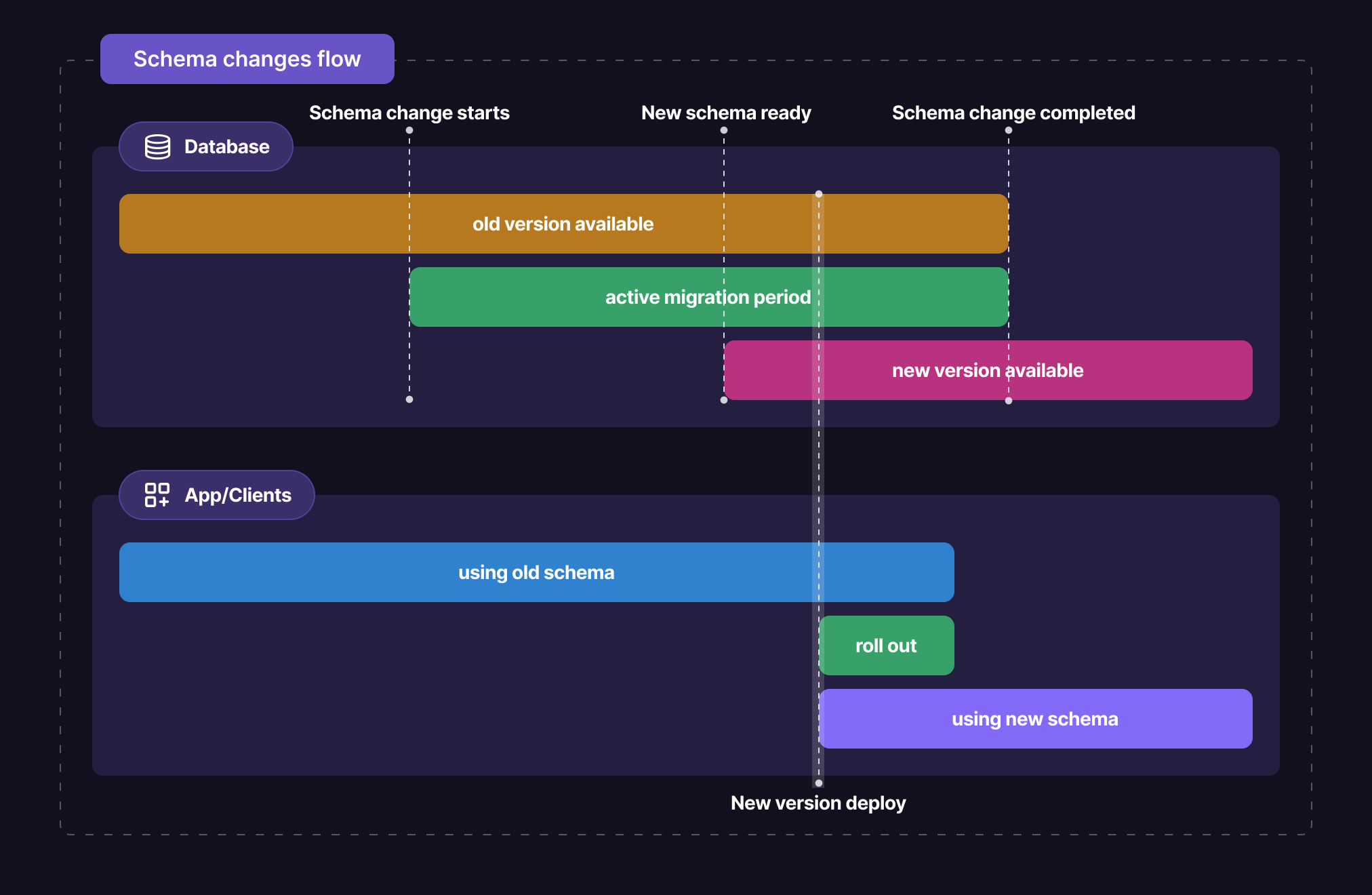
pgroll suit un flux de travail d'extension / contrat. Au début de la migration, il effectuera toutes les modifications additives (créer des tables, ajouter des colonnes, etc.) dans le schéma physique, sans le casser.
Lorsqu'un changement de rupture est requis sur une colonne, il créera une nouvelle colonne dans le schéma physique et le remplit à partir de l'ancienne colonne. En outre, configurez les déclencheurs pour vous assurer que toutes les écritures à l'ancienne / nouvelle colonne se propagent à son homologue pendant toute la période de migration active. La nouvelle colonne sera ensuite exposée dans la nouvelle version du schéma.
Une fois la phase de démarrage terminée, la nouvelle version de schéma est prête, cartographie toutes les vues sur les tables et colonnes appropriées. Les applications client peuvent ensuite accéder à la nouvelle version de schéma, tandis que l'ancienne est toujours disponible. C'est le moment de commencer à déployer la nouvelle version de l'application client.
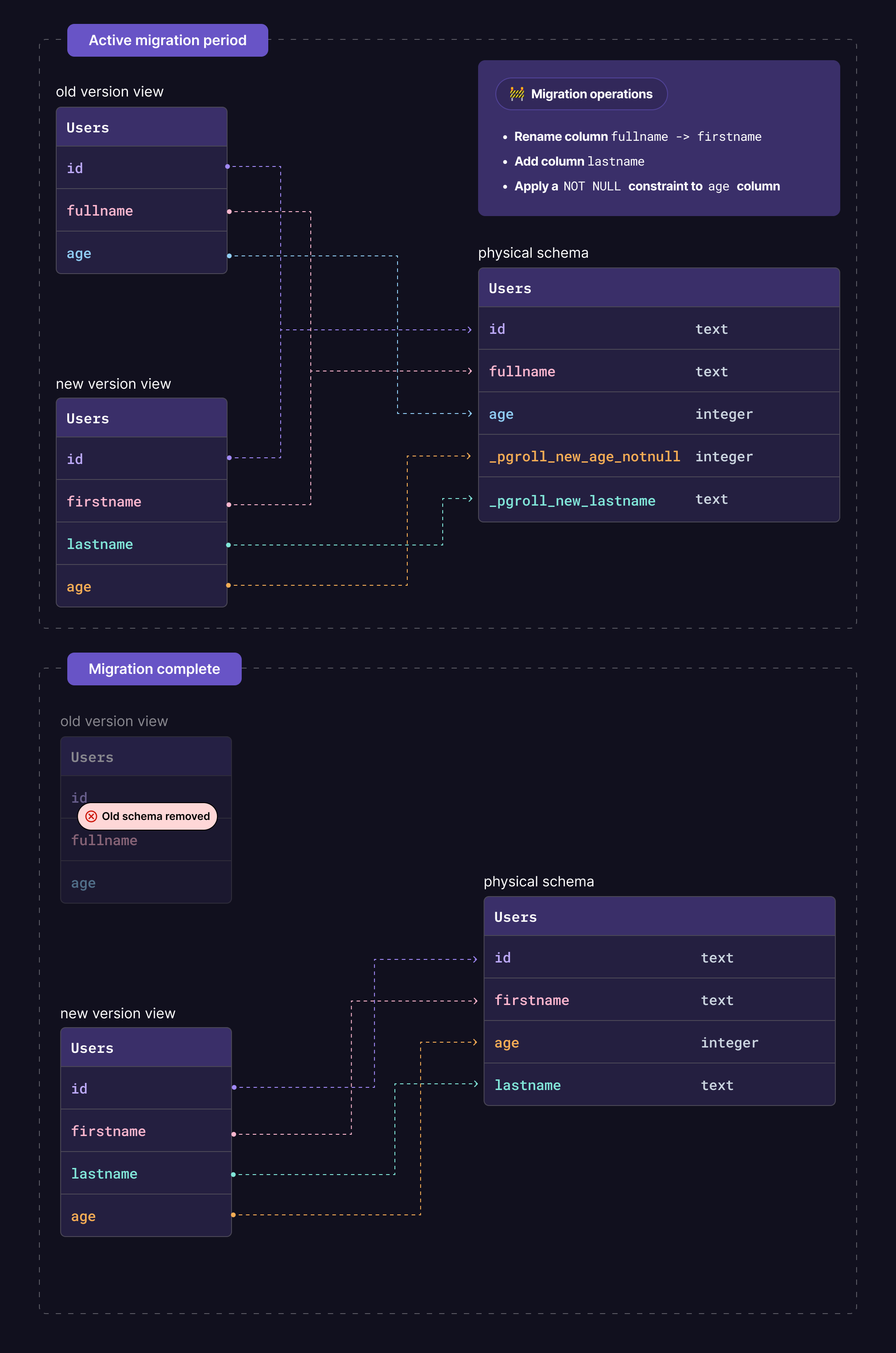
Lorsqu'aucune autre application client n'utilise l'ancienne version de schéma, la migration peut être terminée. Cela supprimera l'ancien schéma, et le nouveau sera le seul disponible. Les tables et colonnes nécessaires ne seront plus nécessaires (aucun client ne l'utilise à ce stade), et les nouveaux seront renommés à leurs noms finaux. Les applications client fonctionnent toujours pendant cette phase, car les vues sont toujours à la recherche des tables et colonnes appropriées.
Les binaires sont disponibles pour Linux, MacOS et Windows, vérifiez nos sorties.
Pour installer pgroll à partir de la source, exécutez la commande suivante:
go install github.com/xataio/pgroll@latestRemarque: nécessite GO 1.23 ou version ultérieure.
Pour installer pgroll avec HomeBrew, exécutez la commande suivante:
# macOS or Linux
brew tap xataio/pgroll
brew install pgroll Suivez ces étapes pour effectuer votre première migration de schéma à l'aide de pgroll :
pgroll doit stocker un état interne dans la base de données. Une table est créée pour suivre la version schéma actuelle et stocker l'historique des versions. Pour préparer la base de données, exécutez la commande suivante:
pgroll init --postgres-url postgres://user:password@host:port/dbname Créer un fichier de migration. Vous pouvez vérifier le dossier Exemples pour quelques exemples. Par exemple, utilisez ce fichier de migration pour créer un nouveau tableau customers :
{
"name" : " initial_migration " ,
"operations" : [
{
"create_table" : {
"name" : " customers " ,
"columns" : [
{
"name" : " id " ,
"type" : " integer " ,
"pk" : true
},
{
"name" : " name " ,
"type" : " varchar(255) " ,
"unique" : true
},
{
"name" : " bio " ,
"type" : " text " ,
"nullable" : true
}
]
}
}
]
}Ensuite, exécutez la commande suivante pour démarrer la migration:
pgroll --postgres-url postgres://user:password@host:port/dbname start initial_migration.jsonCela créera une nouvelle version de schéma dans la base de données et appliquera les opérations de migration (créer une table). Une fois cette commande terminée, l'ancienne version du schéma (sans table de clients) et la nouvelle (avec la table des clients) seront accessibles simultanément.
Après avoir démarré une migration, les applications client peuvent commencer à utiliser la nouvelle version de schéma. Pour ce faire, ils doivent être configurés pour y accéder. Cela peut être fait en définissant le search_path sur le nouveau nom de version de schéma (fourni par pgroll start Output), par exemple:
SET search_path TO ' public_initial_migration ' ;Une fois qu'il n'y a plus d'applications client utilisant l'ancienne version de schéma, la migration peut être terminée. Cela éliminera l'ancien schéma. Pour terminer la migration, exécutez la commande suivante:
pgroll --postgres-url postgres://user:password@host:port/dbname completeÀ tout moment d'une migration, il peut être reculé vers la version précédente. Cela supprimera le nouveau schéma et laissera l'ancien tel qu'il était avant le début de la migration. Pour faire reculer une migration, exécutez la commande suivante:
pgroll --postgres-url postgres://user:password@host:port/dbname rollbackPour une utilisation plus avancée, des tutoriels et des options détaillées, reportez-vous aux guides et références dans la documentation.
Certains repères de performance sont exécutés sur chaque engagement à main pour suivre les performances au fil du temps. Chaque référence est exécutée contre Postgres 14.8, 15.3, 16.4, 17.0 et "Derniter". Chaque ligne du graphique représente le nombre de lignes contre lesquelles les lignes de référence ont été exécutées, actuellement des lignes de 10k, 100k et 300k.
Backfill: lignes / s pour remplir une colonne de texte avec l' placeholder de valeur. Nous utilisons notre stratégie de lot par défaut de 10 000 lignes par lot sans revers.WriteAmplification/NoTrigger: lignes de base / s lors de l'écriture de données dans une table sans déclencheur pgroll .WriteAmplification/WithTrigger: lignes / s lors de la rédaction de données dans une table lorsqu'un déclencheur pgroll a été configuré.ReadSchema: vérifie le nombre d'exécutions par seconde de la fonction read_schema qui est une fonction principale exécutée fréquemment lors des migrations.Ils peuvent être vus ici.
Nous accueillons les contributions de la communauté! Si vous souhaitez contribuer à pgroll , veuillez suivre ces directives:
Pour ce projet, nous nous engageons à agir et à interagir de manière à contribuer à une communauté ouverte, accueillante, diversifiée, inclusive et saine.
Il s'agit d'une liste de projets et d'articles qui ont aidé à l'inspiration, ou qui sont similaires à pgroll :
Ce projet est concédé sous licence Apache 2.0 - Voir le fichier de licence pour plus de détails.
Si vous avez des questions, rencontrez des problèmes ou avez besoin d'aide, ouvrez un problème dans ce référentiel, nous rejoignez notre discorde et notre communauté sera heureuse de vous aider.
Fabriqué avec ❤️ par xata?


