deal.II Assistant github
1.0.0
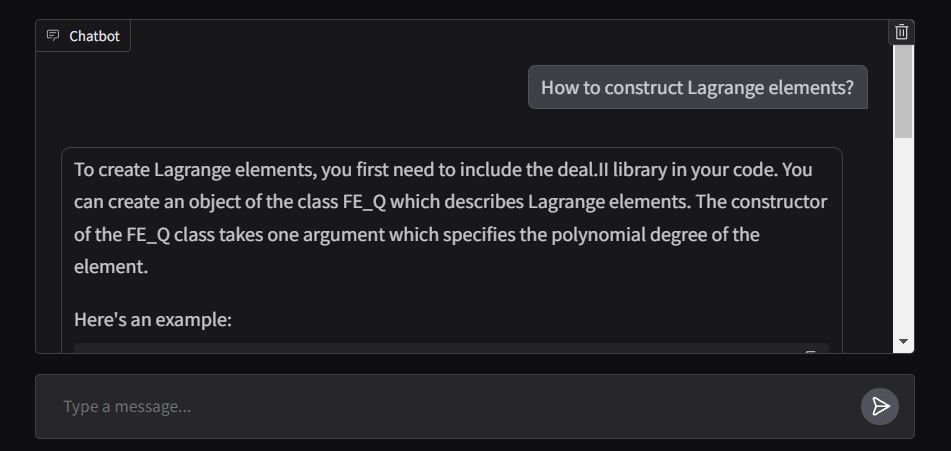
LLMS最强大的应用程序之一是创建复杂的提问(Q&A)聊天机器人,能够根据特定的源信息提供准确的答案。该项目着重于为Deal.II库(开源C ++有限元库)开发虚拟助手。该数据集来自官方Deal.ii文档中可用的90个教程步骤,可以在此处访问。大型语言模型(LLM)引擎由Cohere提供,该引擎以提供嵌入和聊天服务的高质量LLM模型而闻名。对于矢量数据库,由于其开源性质,速度和效率在搜索和检索矢量方面,我们选择了Chroma。 Langchain框架用于有效地管理用户输入,查询处理以及从矢量数据库中检索相关信息之间的交互,从而确保模型的各个组件之间的无缝集成。
准备数据库的过程如下:首先,从网站上以Langchain文档对象检索教程页面。为了提高访问速度(在测试时间),将这些文档对象保存为JSON文件在本地磁盘上。接下来,将文档分为适当尺寸的块(每块约400个令牌,重叠40个令牌)。数据集总共包含230万个令牌。最后,这些拆分文档嵌入到矢量数据库中。
该模型是使用四个链和三个及时模板构建的。
重新格式链:该链收到用户的问题和对话历史,然后根据以前的对话重新提出问题。例如,如果第一个问题是“什么是fe_nothing?”第二个问题是“我可以在哪里使用?”,重新制定链会将第二个问题修改为“我可以在哪里使用fe_nothing?”此步骤本质上为对话添加了内存,从而确保上下文连续性。
多问题链:该链提出了重新的问题,并产生了五个类似的问题,提供了多种观点。它使用简单的lambda函数输出问题列表,并使用remove_empty_string函数作为最后一步删除任何空行。
检索链:该链从上一个链中获取五个问题,并查询矢量数据库。向量数据库搜索类似的向量并检索相关文档。由于可以多次检索相同的文档在不同的问题上,因此使用get_unique_union函数作为最后一步创建了一组唯一的文档。
抹布链:该链使用问题,对话历史记录和从上一个链中检索的文档作为生成最终答案的上下文。
应用程序的前端是使用Gradio的ChatInterface构建的,其响应函数旨在实时流出输出。该应用程序部署在拥抱面积中,可以在此处访问。


