deal.II Assistant github
1.0.0
Eine der leistungsstärksten Anwendungen von LLMs ist die Erstellung hoch entwickelter Fragen-Answere (Q & A) Chatbots, die in der Lage sind, genaue Antworten auf der Grundlage spezifischer Quellinformationen zu geben. Dieses Projekt konzentriert sich auf die Entwicklung eines virtuellen Assistenten für die Deal.II-Bibliothek, eine Open-Source-C ++-Finite-Elemente-Bibliothek, unter Verwendung einer Technik, die als RAG-A-A-Augmented Generation (RAG) bekannt ist. Der Datensatz stammt aus 90 Tutorial -Schritten im offiziellen Deal.II -Dokumentation, auf die hier zugegriffen werden kann. Die LLM-Engine (Languor Language Model) wird von Cohere bereitgestellt, das für die Bereitstellung hochwertiger LLM-Modelle für Einbettungen und Chat-Dienste bekannt ist. Für die Vektor-Datenbank haben wir uns aufgrund ihrer Open-Source-Natur, Geschwindigkeit und Effizienz bei der Suche und Abruf von Vektoren ausgewählt. Das Langchain -Framework wird verwendet, um die Interaktion zwischen der Eingabe des Benutzers, der Verarbeitung von Abfragen und dem Abrufen relevanter Informationen aus der Vektordatenbank effizient zu verwalten, um eine nahtlose Integration zwischen verschiedenen Komponenten des Modells zu gewährleisten.
Der Prozess zur Vorbereitung der Datenbank lautet wie folgt: Erstens werden die Tutorialseiten von der Website als Langchain -Dokumentobjekte abgerufen. Um die Zugriffsgeschwindigkeit (während der Testzeit) zu verbessern, werden diese Dokumentobjekte als JSON -Dateien auf der lokalen Festplatte gespeichert. Als nächstes werden die Dokumente in Stücke entsprechend dimensioniert (etwa 400 Token pro Chunk mit einer Überlappung von 40 Token). Insgesamt umfasst der Datensatz 2,3 Millionen Token. Schließlich sind diese geteilten Dokumente in die Vektordatenbank eingebettet.
Das Modell wird unter Verwendung von vier Ketten und drei Eingabeaufenthaltsvorlagen erstellt.
Reformulate Chain : Diese Kette erhält die Frage und die Konversationsgeschichte des Benutzers und formuliert dann die Frage auf der Grundlage des vorherigen Dialogs. Wenn beispielsweise die erste Frage "Was ist fe_nothing?" Lautet, wenn die erste Frage ist? Und die zweite Frage lautet: "Wo kann ich es verwenden?", Die Reformulationskette wird die zweite Frage an "Wo kann ich Fe_nothing verwenden?" ändern? Dieser Schritt fügt der Konversation im Wesentlichen Gedächtnis hinzu, um die Kontext -Kontinuität zu gewährleisten.
Multi-Question-Kette : Diese Kette nimmt die neu formulierte Frage und erzeugt fünf ähnliche Fragen, wobei mehrere Perspektiven bereitgestellt werden. Es gibt eine Python -Liste von Fragen mit einer einfachen Lambda -Funktion aus, und alle leeren Zeilen werden unter Verwendung der Funktion remove_empty_string als letzte Schritt entfernt.
Abrufkette : Diese Kette enthält die fünf Fragen aus der vorherigen Kette und fragt die Vektordatenbank ab. Die Vektordatenbank sucht nach ähnlichen Vektoren und ruft relevante Dokumente ab. Da das gleiche Dokument möglicherweise mehrmals für verschiedene Fragen abgerufen wird, wird ein eindeutiger Satz von Dokumenten mit der Funktion get_unique_union als letzter Schritt erstellt.
RAG -Kette : Diese Kette verwendet die Frage, die Konversationshistorie und die abgerufenen Dokumente aus der vorherigen Kette als Kontext, um die endgültige Antwort zu generieren.
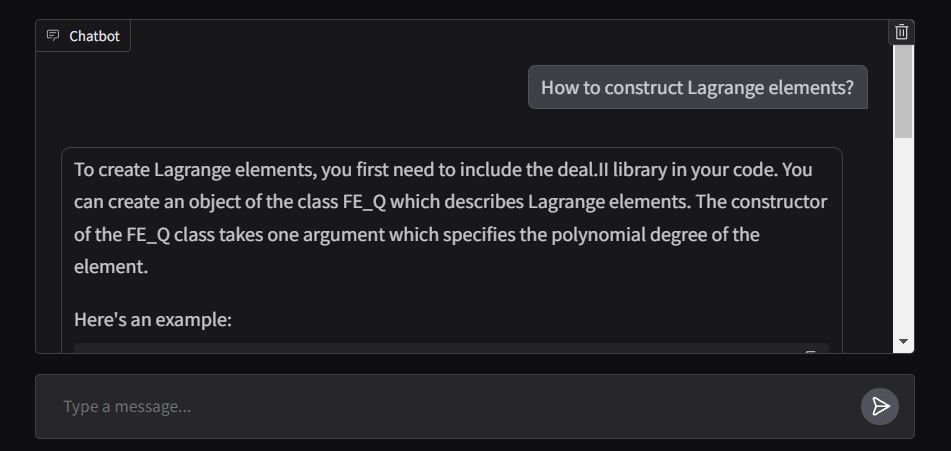
Das vordere Ende der Anwendung wird mit ChatInterface von Gradio erstellt, wobei die Antwortfunktion für die Streamen der Ausgabe in Echtzeit ausgelegt ist. Die Anwendung wird in den umarmenden Gesichtsräumen eingesetzt und kann hier zugegriffen werden.


