alfy
v2.1.0
轻松创建Alfred工作流程
node二进制。await 。.catch()顶级承诺。 您需要Node.js 18+和Alfred 4或更高版本的付费PowerPack升级。
npm install alfy重要的是:您的脚本将作为ESM运行。
创建一个新的空白Alfred工作流程。
添加Script Filter (右键单击帆布→ Inputs → Script Filter ),将Language设置为/bin/bash ,然后添加以下脚本:
./node_modules/.bin/run-node index.js "$1"
我们不能直接调用node ,因为MACOS上的GUI应用程序不会继承$路径。
提示:您可以使用Generator-Alfred来踩踏基于
alfy的工作流程。如果是这样,您可以跳过其余步骤,直接转到index.js并做您的事情。
设置要调用工作流程的Keyword 。
转到您的新工作流目录(右键单击侧边栏中的工作流→ Open in Finder )。
用npm init初始化回购。
将"type": "module"添加到package.json。
使用npm install alfy ALFY。
在工作流目录中,创建一个index.js文件,导入alfy ,然后做您的事情。
在这里,我们从占位符API中获取一些JSON,并将匹配的项目呈现给用户:
import alfy from 'alfy' ;
const data = await alfy . fetch ( 'https://jsonplaceholder.typicode.com/posts' ) ;
const items = alfy
. inputMatches ( data , 'title' )
. map ( element => ( {
title : element . title ,
subtitle : element . body ,
arg : element . id
} ) ) ;
alfy . output ( items ) ; 
野外的一些例子: alfred-npms , alfred-emoj , alfred-ng 。
ALFY在后台使用Alfred-Notifier在可用的工作流程时显示通知。
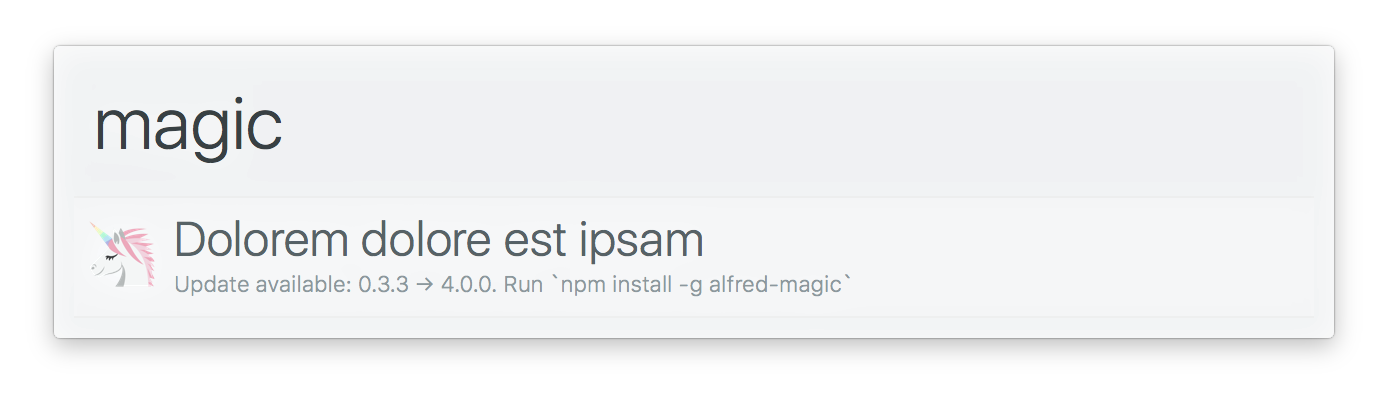
ALFY提供了缓存数据的可能性,无论是以fetch而直接通过缓存对象。
要注意的一个重要的事情是,当您更新工作流程时,缓存的数据会自动无效。这为开发人员提供了更改工作流程之间缓存数据的结构的灵活性,而不必担心无效的旧数据。
通过将alfy-init添加为postinstall和alfy-cleanup作为preuninstall脚本,您可以将软件包发布到NPM而不是将其发布到Packal中。这样,您的软件包只是一个简单的npm install命令。
{
"name" : " alfred-unicorn " ,
"version" : " 1.0.0 " ,
"description" : " My awesome unicorn workflow " ,
"author" : {
"name" : " Sindre Sorhus " ,
"email" : " [email protected] " ,
"url" : " https://sindresorhus.com "
},
"scripts" : {
"postinstall" : " alfy-init " ,
"preuninstall" : " alfy-cleanup "
},
"dependencies" : {
"alfy" : " * "
}
}提示:与
alfred-工作流程前缀 - 使其可以通过NPM轻松搜索。
您可以从info.plist文件中删除这些属性,因为它们会在安装时自动添加。
将您的工作流发布到NPM之后,您的用户可以轻松安装或更新工作流程。
npm install --global alfred-unicorn提示:不要亲自手动更新每个工作流程,而是使用Alfred-Updater工作流程为您做到这一点。
可以通过Alfy测试轻松测试工作流程。这是一个小例子。
import test from 'ava' ;
import alfyTest from 'alfy-test' ;
test ( 'main' , async t => {
const alfy = alfyTest ( ) ;
const result = await alfy ( 'workflow input' ) ;
t . deepEqual ( result , [
{
title : 'foo' ,
subtitle : 'bar'
}
] ) ;
} ) ; 开发工作流程时,在某些东西不起作用时能够调试它可能会很有用。这是工作流调试器派上用场的时候。您可以在Alfred的工作流视图中找到它。按下昆虫图标打开它。它将向您显示alfy.output()的纯文本输出以及您使用alfy.log()登录的任何内容:
import alfy from 'alfy' ;
const unicorn = getUnicorn ( ) ;
alfy . log ( unicorn ) ; Alfred允许用户为工作流程设置环境变量,然后该工作流可以使用该变量。例如,如果您需要用户为服务指定API令牌,则这可能很有用。您可以从process.env访问工作流环境变量。例如process.env.apiToken 。
类型: string
来自阿尔弗雷德的输入。用户在输入框中写的内容。
返回输出到阿尔弗雷德。
类型: object[]
具有任何支持属性的object列表。
例子:
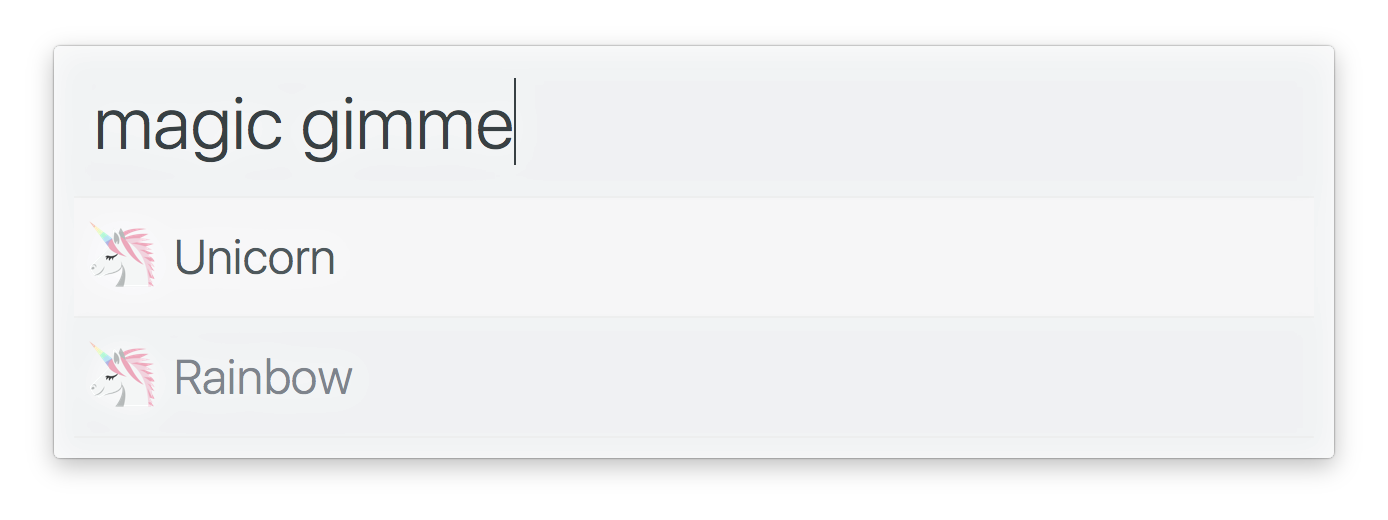
import alfy from 'alfy' ;
alfy . output ( [
{
title : 'Unicorn'
} ,
{
title : 'Rainbow'
}
] ) ; 类型: object
类型: number (秒)
值: 0.1...5.0
一定间隔后,可以将脚本设置为自动重新运行。仅当脚本过滤器仍然处于活动状态并且用户未通过键入和触发重新运行来更改过滤器状态时,该脚本才会重新运行。更多信息。
例如,它可以用来更新特定任务的进度:
import alfy from 'alfy' ;
alfy . output (
[
{
title : 'Downloading Unicorns…' ,
subtitle : ` ${ progress } %` ,
}
] ,
{
// Re-run and update progress every 3 seconds.
rerunInterval : 3
}
) ; 
对Alfred Workflow调试器的日志value 。
返回list中的项目的string[]该案例不敏感地包含input 。
import alfy from 'alfy' ;
alfy . matches ( 'Corn' , [ 'foo' , 'unicorn' ] ) ;
//=> ['unicorn'] 类型: string
与list项目匹配的文字。
类型: string[]
列表要匹配。
类型: string | Function
默认情况下,它将与list项目匹配。
指定一个字符串与对象属性匹配:
import alfy from 'alfy' ;
const list = [
{
title : 'foo'
} ,
{
title : 'unicorn'
}
] ;
alfy . matches ( 'Unicorn' , list , 'title' ) ;
//=> [{title: 'unicorn'}]或嵌套属性:
import alfy from 'alfy' ;
const list = [
{
name : {
first : 'John' ,
last : 'Doe'
}
} ,
{
name : {
first : 'Sindre' ,
last : 'Sorhus'
}
}
] ;
alfy . matches ( 'sindre' , list , 'name.first' ) ;
//=> [{name: {first: 'Sindre', last: 'Sorhus'}}]指定自己处理匹配的函数。该函数接收列表项目和输入,均为参数,并且有望返回其是否匹配的布尔值:
import alfy from 'alfy' ;
const list = [ 'foo' , 'unicorn' ] ;
// Here we do an exact match.
// `Foo` matches the item since it's lowercased for you.
alfy . matches ( 'Foo' , list , ( item , input ) => item === input ) ;
//=> ['foo'] 与matches()相同,但使用alfy.input作为input 。
如果要与多个项目匹配,则必须定义自己的匹配功能(如下所示)。让我们将示例从开始到搜索title或body属性或两者兼而有之的关键字。
import alfy from 'alfy' ;
const data = await alfy . fetch ( 'https://jsonplaceholder.typicode.com/posts' ) ;
const items = alfy
. inputMatches (
data ,
( item , input ) =>
item . title ?. toLowerCase ( ) . includes ( input ) ||
item . body ?. toLowerCase ( ) . includes ( input )
)
. map ( ( element ) => ( {
title : element . title ,
subtitle : element . body ,
arg : element . id ,
} ) ) ;
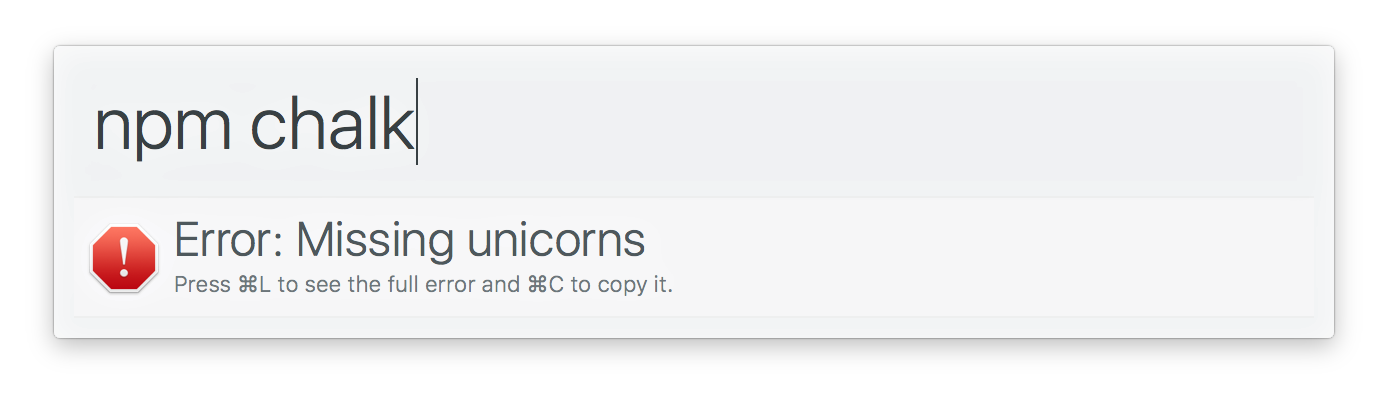
alfy . output ( items ) ; 在Alfred中显示错误或错误消息。
注意:您不需要.catch()顶级承诺。 Alfy为您处理。
类型: Error | string
要显示的错误或错误消息。
返回一个返回响应身体的Promise 。
类型: string
url提取。
类型: object
任何got选项和以下选项。
类型: boolean
默认值: true
用JSON.parse和设置accept application/json套装响应主体。
类型: number
该请求的数量应缓存。
类型: boolean
默认值: true
是只用身体解决还是完全反应。
import alfy from 'alfy' ;
await alfy . fetch ( 'https://api.foo.com' ) ;
//=> {foo: 'bar'}
await alfy . fetch ( 'https://api.foo.com' , {
resolveBodyOnly : false
} ) ;
/*
{
body: {
foo: 'bar'
},
headers: {
'content-type': 'application/json'
}
}
*/ 类型: Function
在缓存之前改变响应主体。
import alfy from 'alfy' ;
await alfy . fetch ( 'https://api.foo.com' , {
transform : body => {
body . foo = 'bar' ;
return body ;
}
} )改变响应。
import alfy from 'alfy' ;
await alfy . fetch ( 'https://api.foo.com' , {
resolveBodyOnly : false ,
transform : response => {
response . body . foo = 'bar' ;
return response ;
}
} )您也可以回报承诺。
import alfy from 'alfy' ;
import xml2js from 'xml2js' ;
import pify from 'pify' ;
const parseString = pify ( xml2js . parseString ) ;
await alfy . fetch ( 'https://api.foo.com' , {
transform : body => parseString ( body )
} ) 类型: object
持久配置数据。
用正确的配置路径集导出conf实例。
例子:
import alfy from 'alfy' ;
alfy . config . set ( 'unicorn' , '?' ) ;
alfy . config . get ( 'unicorn' ) ;
//=> '?' 类型: Map
用用户工作流配置导出地图。工作流程配置使您的用户可以为工作流提供配置信息。例如,如果您正在开发GitHub工作流程,则可以让用户提供自己的API令牌。
有关更多详细信息,请参见alfred-config 。
例子:
import alfy from 'alfy' ;
alfy . userConfig . get ( 'apiKey' ) ;
//=> '16811cad1b8547478b3e53eae2e0f083' 类型: object
持久缓存数据。
带有正确的高速缓存路径集的修改后的conf实例。
例子:
import alfy from 'alfy' ;
alfy . cache . set ( 'unicorn' , '?' ) ;
alfy . cache . get ( 'unicorn' ) ;
//=> '?' 此实例的set方法接受可选的第三个参数,您可以在其中提供maxAge选项。 maxAge是该值在缓存中有效的毫秒数。
例子:
import alfy from 'alfy' ;
import delay from 'delay' ;
alfy . cache . set ( 'foo' , 'bar' , { maxAge : 5000 } ) ;
alfy . cache . get ( 'foo' ) ;
//=> 'bar'
// Wait 5 seconds
await delay ( 5000 ) ;
alfy . cache . get ( 'foo' ) ;
//=> undefined 类型: boolean
用户当前是否打开工作流调试器。
类型: object
密钥: 'info' | 'warning' | 'error' | 'alert' | 'like' | 'delete'
获取各种默认系统图标。
最有用的键作为钥匙。您可以使用icon.get()获得其余的。访问/System/Library/CoreServices/CoreTypes.bundle/Contents/Resources in Finder中查看所有内容。
例子:
import alfy from 'alfy' ;
console . log ( alfy . icon . error ) ;
//=> '/System/Library/CoreServices/CoreTypes.bundle/Contents/Resources/AlertStopIcon.icns'
console . log ( alfy . icon . get ( 'Clock' ) ) ;
//=> '/System/Library/CoreServices/CoreTypes.bundle/Contents/Resources/Clock.icns' 类型: object
例子:
{
name : 'Emoj' ,
version : '0.2.5' ,
uid : 'user.workflow.B0AC54EC-601C-479A-9428-01F9FD732959' ,
bundleId : 'com.sindresorhus.emoj'
} 类型: object
阿尔弗雷德元数据。
示例: '3.0.2'
找出用户当前正在运行的版本。如果您的工作流程取决于特定的Alfred版本的功能,这可能很有用。
示例: 'alfred.theme.yosemite'
当前的主题使用。
示例: 'rgba(255,255,255,0.98)'
如果您正在飞行创建图标,这使您可以找出主题背景的颜色。
示例: 'rgba(255,255,255,0.98)'
所选结果的颜色。
示例: 3
找出用户在外观首选项中选择的潜台词模式。
可用性注意:这是可用的,因此开发人员可以根据用户的选定模式调整结果文本,但是工作流的结果文本不应基于此不必要地肿,因为用户通常隐藏潜台词的主要原因是使Alfred看起来更清洁。
示例: '/Users/sindresorhus/Library/Application Support/Alfred/Workflow Data/com.sindresorhus.npms'
推荐的非易失性数据的位置。只需使用使用此路径的alfy.data即可。
示例: '/Users/sindresorhus/Library/Caches/com.runningwithcrayons.Alfred/Workflow Data/com.sindresorhus.npms'
推荐的位置挥发性数据。只需使用使用此路径的alfy.cache即可。
示例: '/Users/sindresorhus/Dropbox/Alfred/Alfred.alfredpreferences'
这是Alfred.alfredpreferences的位置。如果用户已同步设置,这将使您能够找出其设置在哪里,无论同步状态如何。
示例: 'adbd4f66bc3ae8493832af61a41ee609b20d8705'
非同步本地首选项存储在Alfred.alfredpreferences中…/preferences/local/${preferencesLocalHash}/ 。
使用Alfy的Alfred工作流程


