alfy
v2.1.0
Crear flujos de trabajo de Alfred con facilidad
node binario.await de nivel superior..catch() . Necesita Node.js 18+ y Alfred 4 o posterior con la actualización PowerPack pagada.
npm install alfyIMPORTANTE: Su script se ejecutará como ESM.
Cree un nuevo flujo de trabajo Alfred en blanco.
Agregue un Script Filter (haga clic con el botón derecho en el lienzo → Inputs → Script Filter ), configure Language en /bin/bash y agregue el siguiente script:
./node_modules/.bin/run-node index.js "$1"
No podemos llamar node directamente, ya que las aplicaciones GUI en MacOS no heredan la ruta $.
Consejo: puede usar Generator-Alfred para andamiar un flujo de trabajo basado en
alfy. Si es así, puede omitir el resto de los pasos, ir directamente alindex.jsy hacer lo suyo.
Establezca la Keyword por la cual desea invocar su flujo de trabajo.
Vaya a su nuevo directorio de flujo de trabajo (haga clic con el botón derecho en el flujo de trabajo en la barra lateral → Open in Finder ).
Inicializar un repositorio con npm init .
Agregue "type": "module" a paquete.json.
Instale Alfy con npm install alfy .
En el directorio de flujo de trabajo, cree un archivo index.js , importe alfy y haga lo suyo.
Aquí obtenemos algunos JSON de una API de marcador de posición y presentamos elementos coincidentes al usuario:
import alfy from 'alfy' ;
const data = await alfy . fetch ( 'https://jsonplaceholder.typicode.com/posts' ) ;
const items = alfy
. inputMatches ( data , 'title' )
. map ( element => ( {
title : element . title ,
subtitle : element . body ,
arg : element . id
} ) ) ;
alfy . output ( items ) ; 
Algunos ejemplos de uso en la naturaleza: alfred-npms , alfred-emoj , alfred-ng .
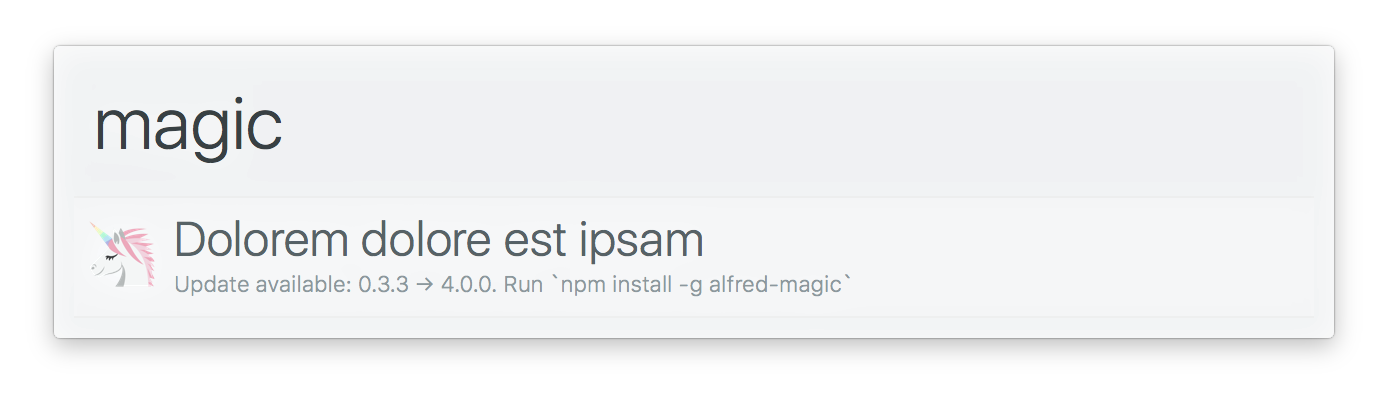
Alfy usa Alfred-Notifier en el fondo para mostrar una notificación cuando hay una actualización para su flujo de trabajo disponible.
Alfy ofrece la posibilidad de almacenar datos en caché, ya sea con la búsqueda o directamente a través del objeto de caché.
Una cosa importante a tener en cuenta es que los datos en caché se invalidan automáticamente cuando actualiza su flujo de trabajo. Esto ofrece la flexibilidad para que los desarrolladores cambien la estructura de los datos almacenados en caché entre los flujos de trabajo sin tener que preocuparse por los datos más antiguos no válidos.
Al agregar alfy-init como postinstall y alfy-cleanup como script preuninstall , puede publicar su paquete a NPM en lugar de Packal. De esta manera, sus paquetes son solo un simple comando npm install .
{
"name" : " alfred-unicorn " ,
"version" : " 1.0.0 " ,
"description" : " My awesome unicorn workflow " ,
"author" : {
"name" : " Sindre Sorhus " ,
"email" : " [email protected] " ,
"url" : " https://sindresorhus.com "
},
"scripts" : {
"postinstall" : " alfy-init " ,
"preuninstall" : " alfy-cleanup "
},
"dependencies" : {
"alfy" : " * "
}
}Consejo: prefije su flujo de trabajo con
alfred-para que sean fáciles de búsqueda a través de NPM.
Puede eliminar estas propiedades de su archivo info.plist , ya que se agregan automáticamente en la hora de instalación.
Después de publicar su flujo de trabajo a NPM, sus usuarios pueden instalar o actualizar fácilmente el flujo de trabajo.
npm install --global alfred-unicornConsejo: en lugar de actualizar manualmente cada flujo de trabajo usted mismo, use el flujo de trabajo Alfred-Updater para hacerlo por usted.
Los flujos de trabajo se pueden probar fácilmente con Alfy-Test. Aquí hay un pequeño ejemplo.
import test from 'ava' ;
import alfyTest from 'alfy-test' ;
test ( 'main' , async t => {
const alfy = alfyTest ( ) ;
const result = await alfy ( 'workflow input' ) ;
t . deepEqual ( result , [
{
title : 'foo' ,
subtitle : 'bar'
}
] ) ;
} ) ; Al desarrollar su flujo de trabajo, puede ser útil poder depurarlo cuando algo no funciona. Esto es cuando el depurador de flujo de trabajo es útil. Puede encontrarlo en su vista de flujo de trabajo en Alfred. Presione el icono de insecto para abrirlo. Le mostrará la salida de texto sin formato de alfy.output() y cualquier cosa que registre con alfy.log() ::
import alfy from 'alfy' ;
const unicorn = getUnicorn ( ) ;
alfy . log ( unicorn ) ; Alfred permite a los usuarios establecer variables de entorno para un flujo de trabajo que luego puede ser utilizado por ese flujo de trabajo. Esto puede ser útil si, por ejemplo, necesita que el usuario especifique un token API para un servicio. Puede acceder a las variables de entorno de flujo de trabajo desde process.env . Por ejemplo, process.env.apiToken .
Tipo: string
Entrada de Alfred. Lo que el usuario escribió en el cuadro de entrada.
Devuelve la salida a Alfred.
Tipo: object[]
Lista de object con cualquiera de las propiedades compatibles.
Ejemplo:
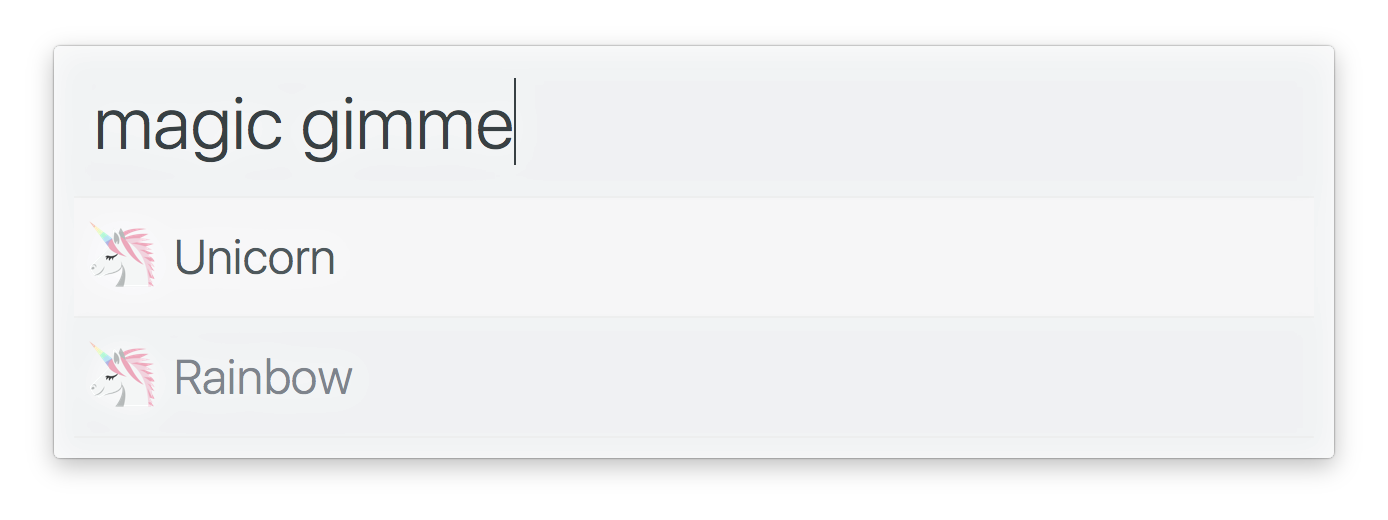
import alfy from 'alfy' ;
alfy . output ( [
{
title : 'Unicorn'
} ,
{
title : 'Rainbow'
}
] ) ; Tipo: object
Tipo: number (segundos)
Valores: 0.1...5.0
Se puede configurar un script para volver a ejecutar automáticamente después de un intervalo. El script solo se volverá a ejecutar si el filtro de script aún está activo y el usuario no ha cambiado el estado del filtro escribiendo y activando una reducción. Más información.
Por ejemplo, podría usarse para actualizar el progreso de una tarea en particular:
import alfy from 'alfy' ;
alfy . output (
[
{
title : 'Downloading Unicorns…' ,
subtitle : ` ${ progress } %` ,
}
] ,
{
// Re-run and update progress every 3 seconds.
rerunInterval : 3
}
) ; 
value de registro al depurador de flujo de trabajo Alfred.
Devuelve una string[] de elementos en list que el caso contiene insensionalmente input .
import alfy from 'alfy' ;
alfy . matches ( 'Corn' , [ 'foo' , 'unicorn' ] ) ;
//=> ['unicorn'] Tipo: string
Texto para que coincida con los elementos list .
Tipo: string[]
Lista para ser coincidente.
Tipo: string | Function
Por defecto, coincidirá con los elementos list .
Especifique una cadena para que coincida con una propiedad de objeto:
import alfy from 'alfy' ;
const list = [
{
title : 'foo'
} ,
{
title : 'unicorn'
}
] ;
alfy . matches ( 'Unicorn' , list , 'title' ) ;
//=> [{title: 'unicorn'}]O propiedad anidada:
import alfy from 'alfy' ;
const list = [
{
name : {
first : 'John' ,
last : 'Doe'
}
} ,
{
name : {
first : 'Sindre' ,
last : 'Sorhus'
}
}
] ;
alfy . matches ( 'sindre' , list , 'name.first' ) ;
//=> [{name: {first: 'Sindre', last: 'Sorhus'}}]Especifique una función para manejar la coincidencia usted mismo. La función recibe el elemento de la lista y la entrada, ambos más bajos, como argumentos, y se espera que devuelva un booleano de si coincide:
import alfy from 'alfy' ;
const list = [ 'foo' , 'unicorn' ] ;
// Here we do an exact match.
// `Foo` matches the item since it's lowercased for you.
alfy . matches ( 'Foo' , list , ( item , input ) => item === input ) ;
//=> ['foo'] Igual que matches() , pero con alfy.input como input .
Si desea que coincida con varios elementos, debe definir su propia función coincidente (como se muestra aquí). Extendamos el ejemplo desde el principio para buscar una palabra clave que aparezca dentro del title o la propiedad body o ambos.
import alfy from 'alfy' ;
const data = await alfy . fetch ( 'https://jsonplaceholder.typicode.com/posts' ) ;
const items = alfy
. inputMatches (
data ,
( item , input ) =>
item . title ?. toLowerCase ( ) . includes ( input ) ||
item . body ?. toLowerCase ( ) . includes ( input )
)
. map ( ( element ) => ( {
title : element . title ,
subtitle : element . body ,
arg : element . id ,
} ) ) ;
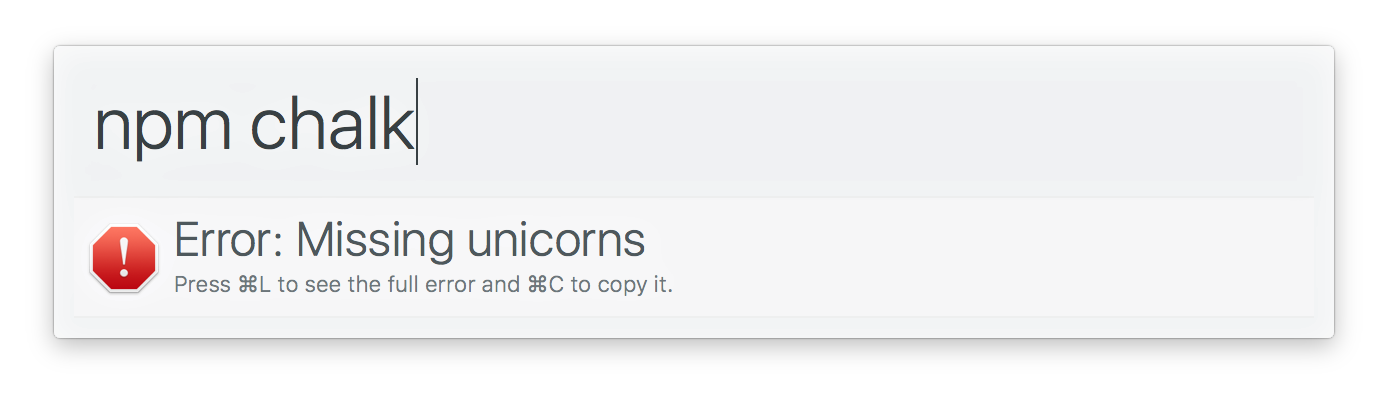
alfy . output ( items ) ; Muestre un mensaje de error o error en Alfred.
Nota: No necesita .catch() Promesas de nivel superior. Alfy maneja eso para ti.
Tipo: Error | string
Se mostrará un mensaje de error o error.
Devuelve una Promise que devuelve el cuerpo de la respuesta.
Tipo: string
Url para buscar.
Tipo: object
Cualquiera de las opciones got y las siguientes opciones.
Tipo: boolean
Valor predeterminado: true
Cuerpo de respuesta de analizador con JSON.parse y establece accept encabezado en application/json .
Tipo: number
Número de milisegundos Esta solicitud debe almacenarse en caché.
Tipo: boolean
Valor predeterminado: true
Si resolver solo con el cuerpo o una respuesta completa.
import alfy from 'alfy' ;
await alfy . fetch ( 'https://api.foo.com' ) ;
//=> {foo: 'bar'}
await alfy . fetch ( 'https://api.foo.com' , {
resolveBodyOnly : false
} ) ;
/*
{
body: {
foo: 'bar'
},
headers: {
'content-type': 'application/json'
}
}
*/ Tipo: Function
Transforme el cuerpo de respuesta antes de que se almacene en caché.
import alfy from 'alfy' ;
await alfy . fetch ( 'https://api.foo.com' , {
transform : body => {
body . foo = 'bar' ;
return body ;
}
} )Transformar la respuesta.
import alfy from 'alfy' ;
await alfy . fetch ( 'https://api.foo.com' , {
resolveBodyOnly : false ,
transform : response => {
response . body . foo = 'bar' ;
return response ;
}
} )También puedes devolver una promesa.
import alfy from 'alfy' ;
import xml2js from 'xml2js' ;
import pify from 'pify' ;
const parseString = pify ( xml2js . parseString ) ;
await alfy . fetch ( 'https://api.foo.com' , {
transform : body => parseString ( body )
} ) Tipo: object
Persistir datos de configuración.
Exporta una instancia conf con el conjunto de ruta de configuración correcto.
Ejemplo:
import alfy from 'alfy' ;
alfy . config . set ( 'unicorn' , '?' ) ;
alfy . config . get ( 'unicorn' ) ;
//=> '?' Tipo: Map
Exporta un mapa con la configuración del flujo de trabajo del usuario. Una configuración de flujo de trabajo permite a sus usuarios proporcionar información de configuración para el flujo de trabajo. Por ejemplo, si está desarrollando un flujo de trabajo GitHub, podría dejar que sus usuarios proporcionen sus propios tokens API.
Ver alfred-config para más detalles.
Ejemplo:
import alfy from 'alfy' ;
alfy . userConfig . get ( 'apiKey' ) ;
//=> '16811cad1b8547478b3e53eae2e0f083' Tipo: object
Persistir datos de caché.
Exporta una instancia conf modificada con el conjunto de ruta de caché correcto.
Ejemplo:
import alfy from 'alfy' ;
alfy . cache . set ( 'unicorn' , '?' ) ;
alfy . cache . get ( 'unicorn' ) ;
//=> '?' El método set de esta instancia acepta un tercer argumento opcional donde puede proporcionar una opción de maxAge . maxAge es el número de milisegundos, el valor es válido en el caché.
Ejemplo:
import alfy from 'alfy' ;
import delay from 'delay' ;
alfy . cache . set ( 'foo' , 'bar' , { maxAge : 5000 } ) ;
alfy . cache . get ( 'foo' ) ;
//=> 'bar'
// Wait 5 seconds
await delay ( 5000 ) ;
alfy . cache . get ( 'foo' ) ;
//=> undefined Tipo: boolean
Si el usuario actualmente tiene el depurador de flujo de trabajo abierto.
Tipo: object
Keys: 'info' | 'warning' | 'error' | 'alert' | 'like' | 'delete'
Obtenga varios iconos del sistema predeterminados.
Los más útiles se incluyen como claves. El resto que puede obtener con icon.get() . Vaya a /System/Library/CoreServices/CoreTypes.bundle/Contents/Resources en Finder para verlos a todos.
Ejemplo:
import alfy from 'alfy' ;
console . log ( alfy . icon . error ) ;
//=> '/System/Library/CoreServices/CoreTypes.bundle/Contents/Resources/AlertStopIcon.icns'
console . log ( alfy . icon . get ( 'Clock' ) ) ;
//=> '/System/Library/CoreServices/CoreTypes.bundle/Contents/Resources/Clock.icns' Tipo: object
Ejemplo:
{
name : 'Emoj' ,
version : '0.2.5' ,
uid : 'user.workflow.B0AC54EC-601C-479A-9428-01F9FD732959' ,
bundleId : 'com.sindresorhus.emoj'
} Tipo: object
Metadatos de Alfred.
Ejemplo: '3.0.2'
Descubra qué versión se ejecuta el usuario actualmente. Esto puede ser útil si su flujo de trabajo depende de las características de una versión de Alfred en particular.
Ejemplo: 'alfred.theme.yosemite'
Tema actual utilizado.
Ejemplo: 'rgba(255,255,255,0.98)'
Si está creando íconos en la marcha, esto le permite descubrir el color del fondo del tema.
Ejemplo: 'rgba(255,255,255,0.98)'
El color del resultado seleccionado.
Ejemplo: 3
Descubra qué modo de subtexto ha seleccionado el usuario en las preferencias de apariencia.
Nota de usabilidad: Esto está disponible para que los desarrolladores puedan ajustar el texto de los resultados en función del modo seleccionado del usuario, pero el texto de resultados de un flujo de trabajo no debe soplarse innecesariamente en función de esto, ya que la razón principal por la que los usuarios generalmente ocultan el subtexto es hacer que Alfred se vea más limpio.
Ejemplo: '/Users/sindresorhus/Library/Application Support/Alfred/Workflow Data/com.sindresorhus.npms'
Ubicación recomendada para datos no volátiles. Simplemente use alfy.data que use esta ruta.
Ejemplo: '/Users/sindresorhus/Library/Caches/com.runningwithcrayons.Alfred/Workflow Data/com.sindresorhus.npms'
Ubicación recomendada para datos volátiles. Simplemente use alfy.cache que usa esta ruta.
Ejemplo: '/Users/sindresorhus/Dropbox/Alfred/Alfred.alfredpreferences'
Esta es la ubicación de Alfred.alfredpreferences . Si un usuario ha sincronizado su configuración, esto le permitirá averiguar dónde están su configuración independientemente de Sync State.
Ejemplo: 'adbd4f66bc3ae8493832af61a41ee609b20d8705'
Las preferencias locales no sincronizadas se almacenan dentro de Alfred.alfredpreferences en …/preferences/local/${preferencesLocalHash}/ .
Flujos de trabajo de Alfred usando Alfy


