docspell
Docspell 0.42.0

Docspell是个人文档组织者。或有时称为“文档管理系统”(DMS)。您需要一个扫描仪来将您的论文转换为文件。然后,Docspell可以帮助组织产生的混乱。它可以从扫描仪,电子邮件和其他来源统一文件。它针对家庭使用,即家庭,家庭以及较小的团体/公司。
您可以将标签,设置对应物以及许多其他预定义和自定义元数据关联。如果您的文档与此类元数据关联,则可以在以后使用搜索功能快速找到它们。但是手动添加这是一项繁琐的任务。 Docspell可以通过建议通讯,猜测标签或使用机器学习查找日期来提供帮助。它可以从现有文档中学习元数据,并使用NLP找到东西。这使您的文档中添加元数据变得更加容易。对于机器学习,它依赖于免费(GPL)Stanford Core NLP库。
DocSpell还可以在文档上运行OCR(如果需要),可以提供完整的搜索并具有很好的电子邮件集成。一切都可以通过REST/HTTP API访问。移动友好的水疗Web应用程序是默认用户界面。存在一个Android应用程序,可方便地从手机/平板电脑和CLI上传文件。该功能概述列出了更多点。
查看项目页面上存在的简短演示视频(<1分钟)。这是一些屏幕截图:
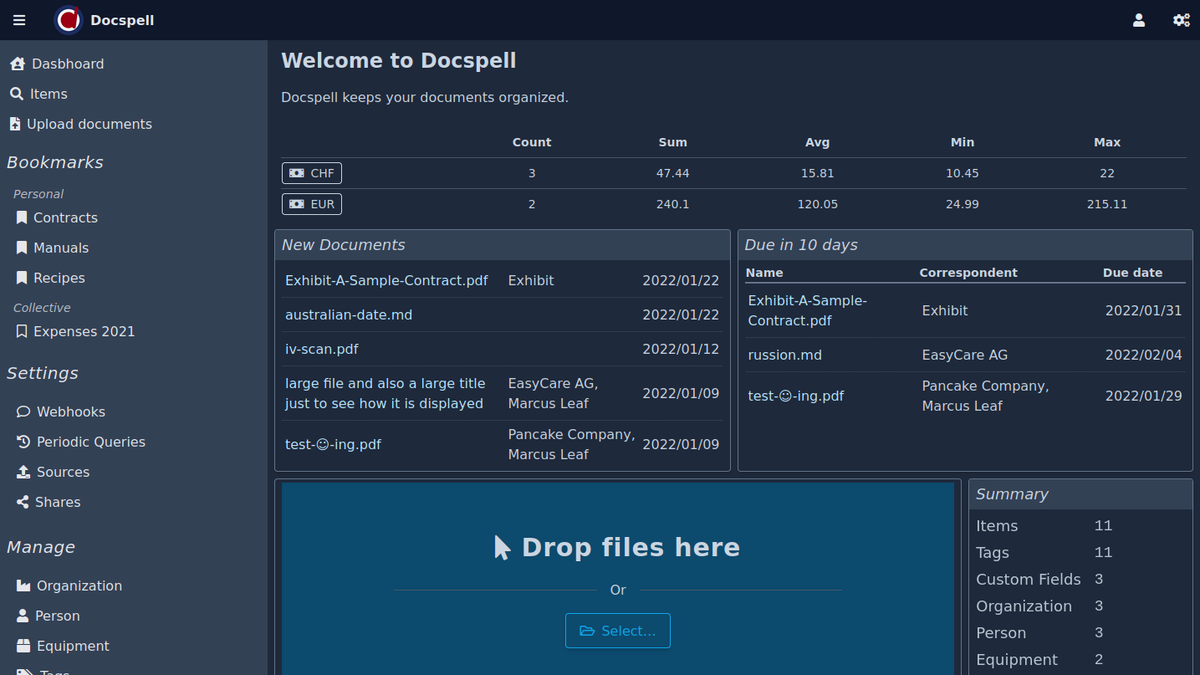
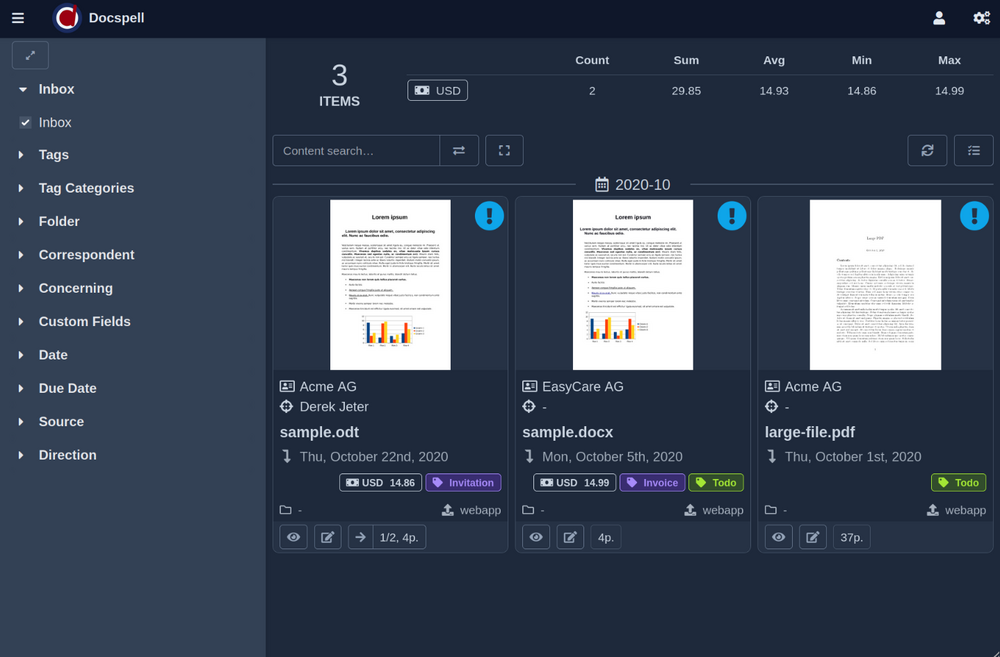
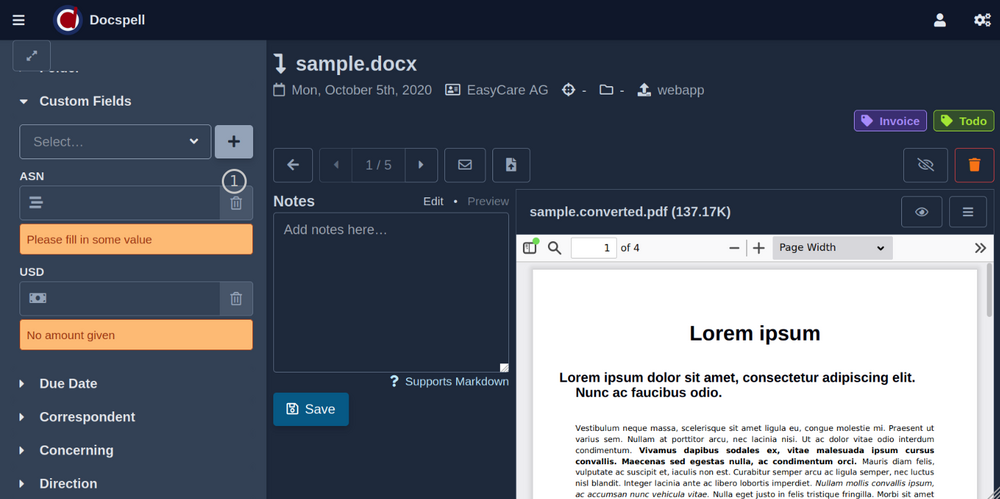
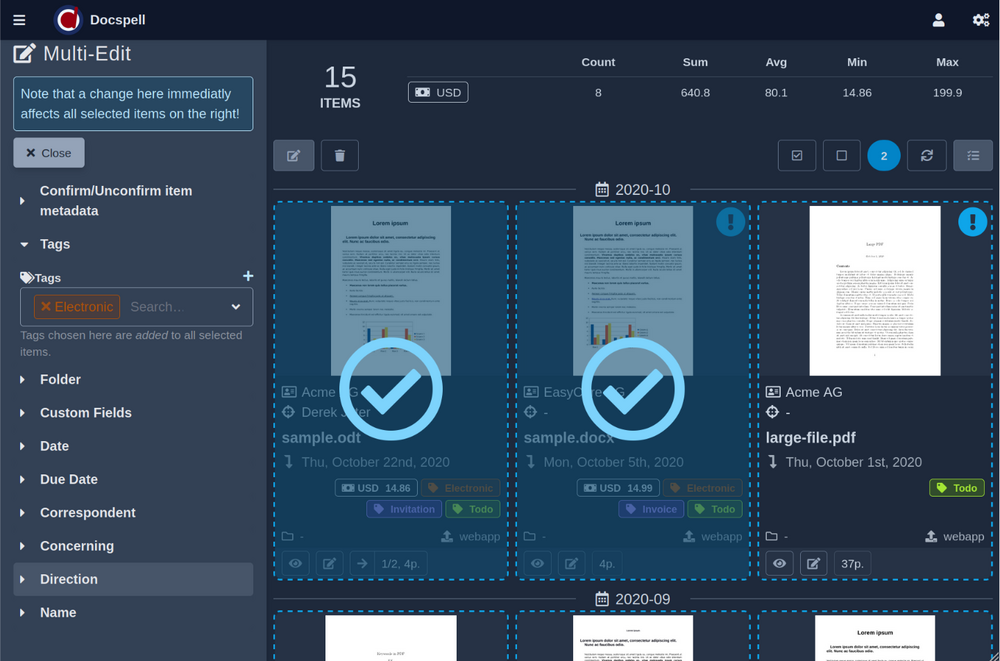
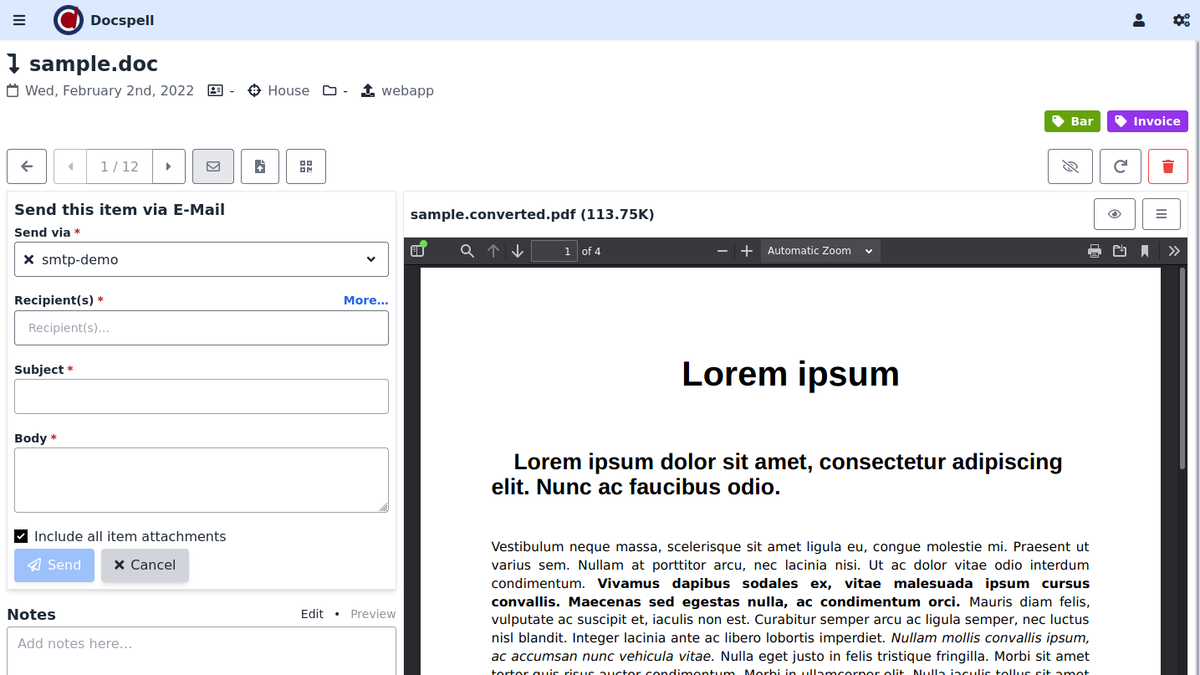
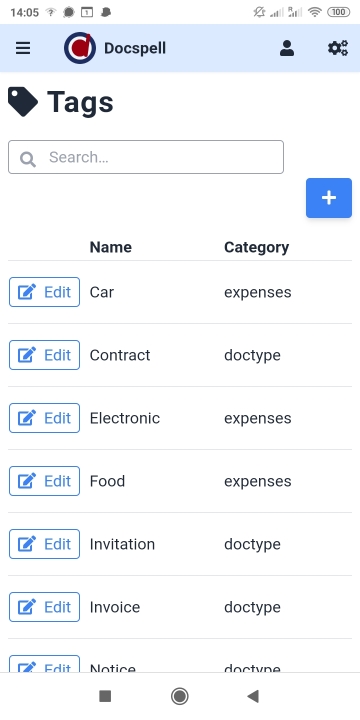

DOCSPELL由几个组件组成。开始开始的最快方法是使用“启动”页面中所述的Docker设置。这只有三个命令:
git clone https://github.com/eikek/docspell
cd docspell/docker/docker-compose
docker-compose up -d然后访问http://localhost:7880 ,注册并登录。目前使用相同名称作为集体和用户。有关此的更多信息,请参见此处。
这里记录了其他方法:
deb文件。bin/脚本运行脚本。项目页面上有很多有关如何使用和设置DOCSPELL的信息。
反馈和其他贡献非常欢迎!有一个聊天和问题的吉特室。您也可以为问题,问题和其他反馈打开一个问题;或向info [at] docspell.org 。我会及时回答。您可能还需要检查贡献。md是否有一些起点。
如果您发现该项目有用并希望通过其他方式支持它,那么给予A总是令人鼓舞和值得赞赏的。您还可以通过Liberapay或PayPal捐赠活动来支持活动。
太感谢了!
后端
该服务器根据Typelevel堆栈的库:CAT,FS2,Doobie,HTTP4S,Circe和Pureconfig以纯粹的功能样式编写。
当然,还有更多的图书馆和技术。 Docspell只是一个精彩的工具和Libs的编排。一个重要的是斯坦福 - NLP,它提供了ML功能。此外,文件处理依赖于Tesseract,unoconv和ocrmypdf等外部工具。所有依赖项都可以在project/Dependencies.scala中查找。
前端
网络前端是用榆木编写的水疗中心。使用的UI框架是逆风。
DocSpell是免费软件,分布在AGPLV3或更高版本下。


