docspell
Docspell 0.42.0

DocSpellは個人の文書オーガナイザーです。または、「ドキュメント管理システム」(DMS)と呼ばれることもあります。論文をファイルに変換するにはスキャナーが必要です。 DocSpellは、結果として生じる混乱の整理を支援できます。スキャナー、電子メール、その他のソースからファイルを統合できます。これは、家庭用、すなわち家族、世帯、および小規模なグループ/企業を対象としています。
タグを関連付けたり、対応したり、他の多くの事前定義されたカスタムメタデータを関連付けたりできます。ドキュメントがそのようなメタデータに関連付けられている場合、検索機能を使用して後ですぐにそれらを見つけることができます。しかし、これを手動で追加することは退屈な作業です。 DocSpellは、特派員を提案したり、タグを推測したり、機械学習を使用して日付を見つけたりすることで役立ちます。既存のドキュメントからメタデータを学習し、NLPを使用して物を見つけることができます。これにより、ドキュメントにメタデータを追加しやすくなります。機械学習のために、フリー(GPL)スタンフォードコアNLPライブラリに依存しています。
DocSpellは、ドキュメントでOCR(必要に応じて)を実行し、フルテキスト検索を提供し、優れた電子メール統合を備えています。すべてがREST/HTTP APIを介してアクセスできます。モバイルフレンドリーなSPA Webアプリケーションは、デフォルトのユーザーインターフェイスです。携帯電話/タブレットとCLIからファイルを便利にアップロードするためのAndroidアプリが存在します。この機能の概要には、さらにポイントがいくつかリストされています。
プロジェクトページに表示される短いデモビデオ(<1min)をチェックアウトします。ここにいくつかのスクリーンショットがあります:
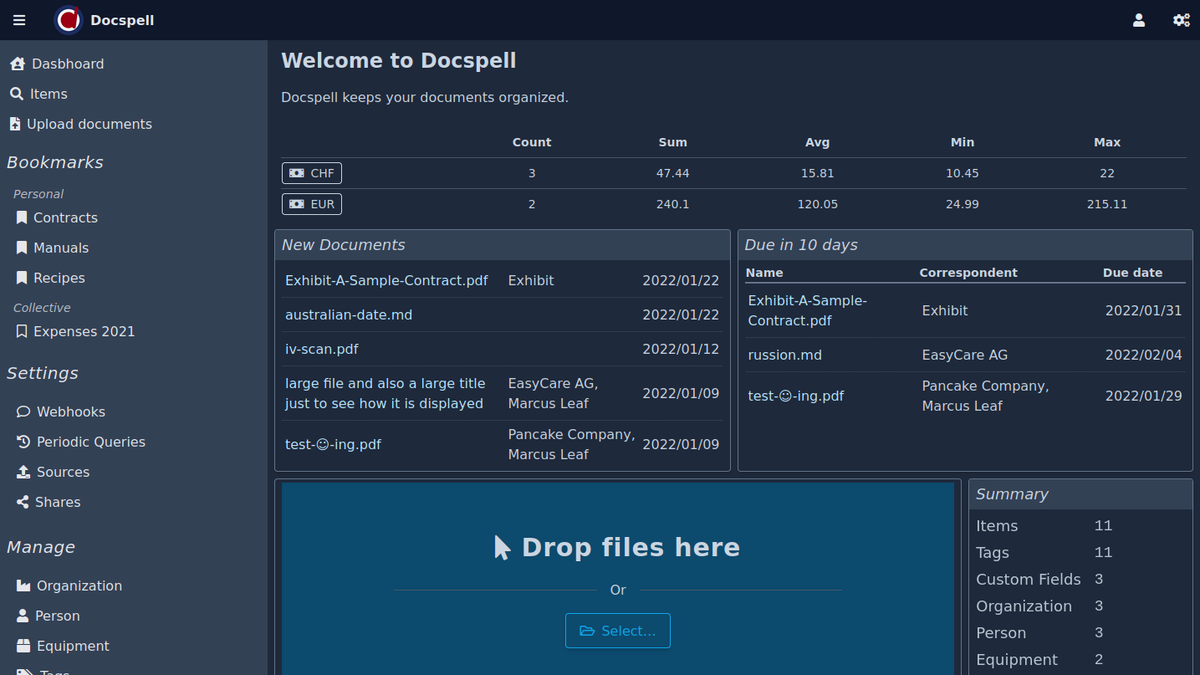
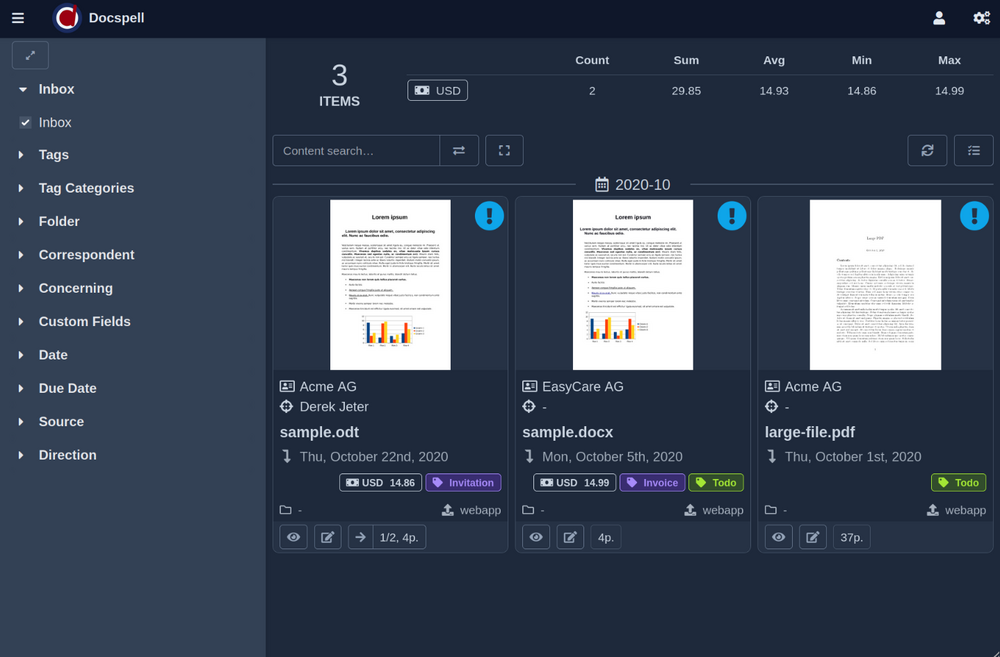
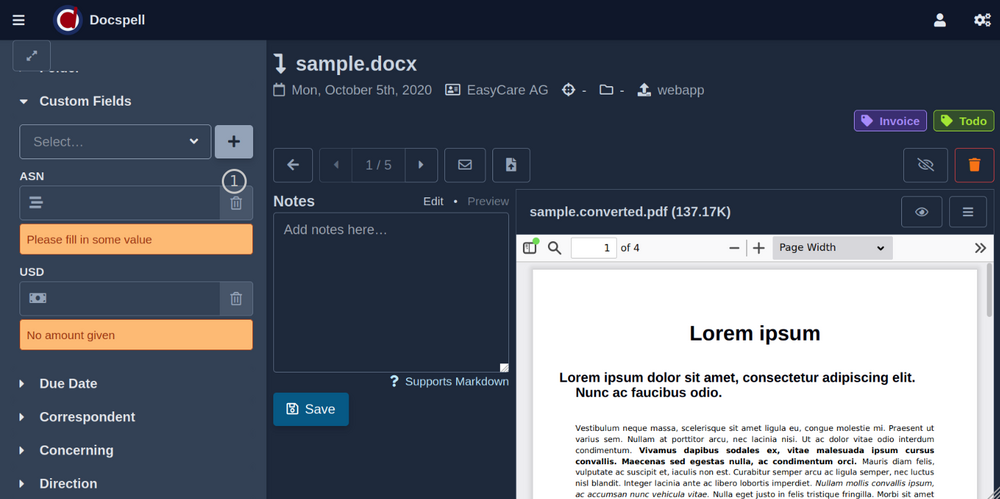
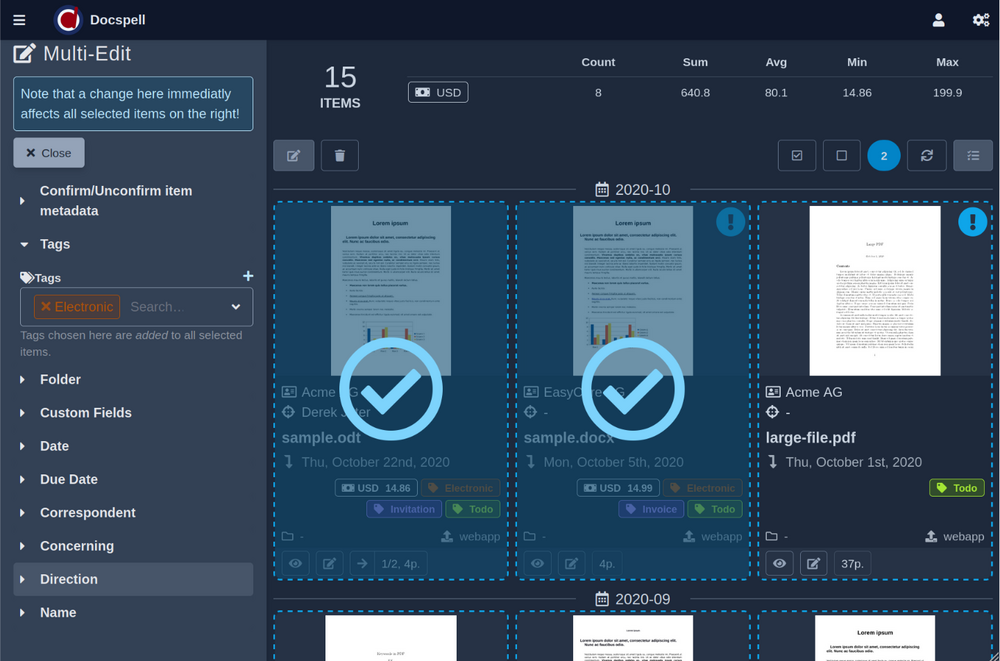
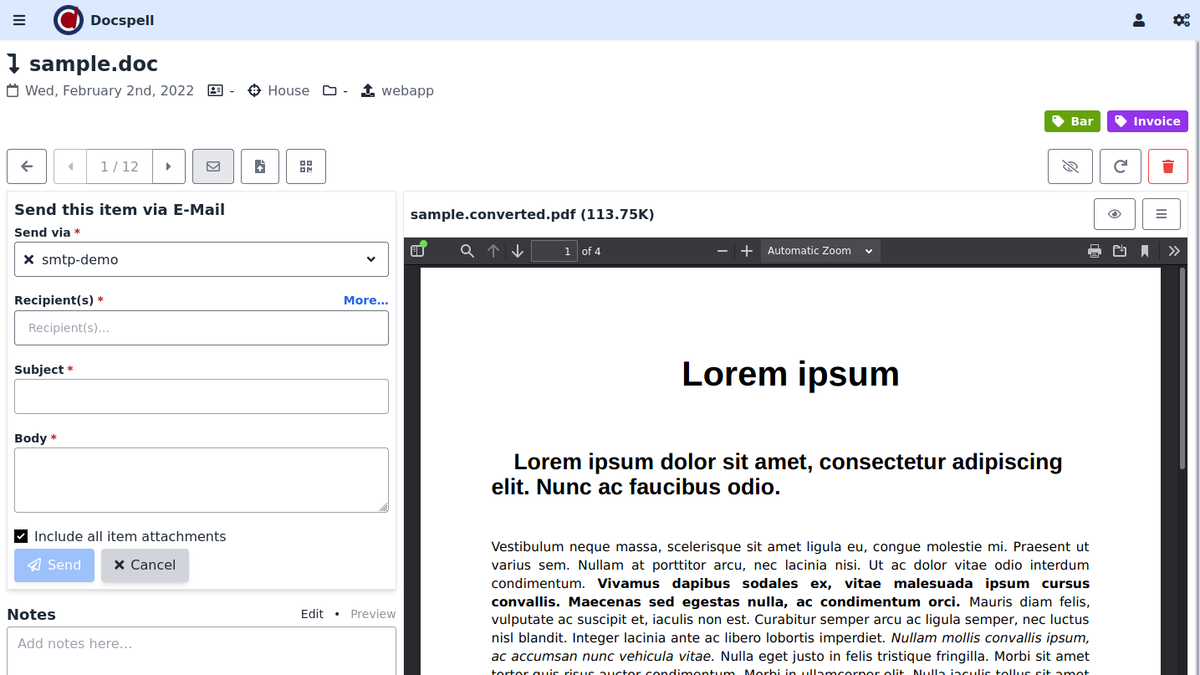
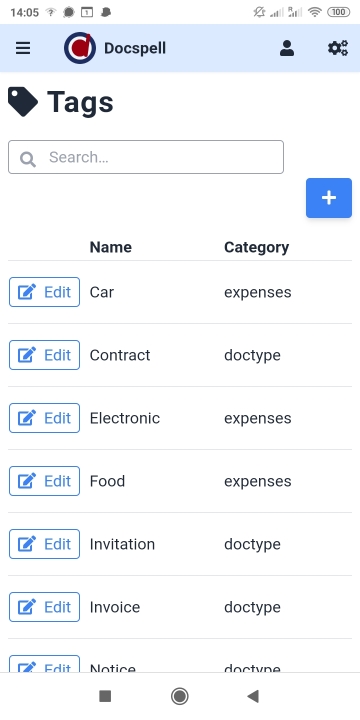

DocSpellはいくつかのコンポーネントで構成されています。開始するためのおそらく最も迅速な方法は、Get Start Pageで説明されているDockerセットアップを使用することです。これはわずか3つのコマンドです。
git clone https://github.com/eikek/docspell
cd docspell/docker/docker-compose
docker-compose up -d次に、 http://localhost:7880に移動し、サインアップしてログインします。今のところ、集団とユーザーに同じ名前を使用してください。そのことについては、こちらをご覧ください。
他の方法はここに文書化されています:
debファイルをインストールします。bin/でスクリプトを実行します。プロジェクトページには、DocSpellの使用方法とセットアップに関する情報がたくさんあります。
フィードバックやその他の貢献は大歓迎です!チャットや質問のためのギタールームがあります。質問、問題、その他のフィードバックの問題を開くこともできます。または、 info [at] docspell.orgにメールを送信します。私は時間内に答えようとします。いくつかの出発点についても、converting.mdを確認することをお勧めします。
このプロジェクトが便利で、他の手段でそれをサポートしたい場合、Aを与えることは常に励みになり、非常に高く評価されます。また、LiberapayまたはPayPalを介して寄付することにより、アクティビティをサポートすることもできます。
どうもありがとうございます!
バックエンド
サーバーは、Typelevel Stackのライブラリ(Cats、FS2、Doobie、HTTP4s、Circe、Pureconfig)のライブラリに基づいて、純粋な機能スタイルでScalaで記述されています。
もちろん、より多くのライブラリとテクノロジーが使用されています。 Docspellは、優れたツールとLibsのオーケストレーションにすぎません。重要な1つは、ML機能を提供するStanford-NLPです。さらに、ファイル処理は、Tesseract、UnoConv、OCRMYPDFなどの外部ツールに依存しています。すべての依存関係はproject/Dependencies.scalaで調べることができます。
フロントエンド
Webフロントエンドは、ELMに書かれたスパです。使用中のUIフレームワークはTailwindです。
docspellはフリーソフトウェアで、Agplv3以下の下で配布されます。


