rl 6 nimmt
1.0.0
6 nimmt!是一款屡获殊荣的纸牌游戏,适用于1994年的两到十名球员。引用Wikipedia:
该游戏有104张卡片,每张牌都有一个数字和一到七个公牛的头符号,代表罚球点。一轮十回合,所有玩家都将他们选择的一张卡放在桌子上。根据固定规则将放置的卡片排列在四行上。如果放置在已经拥有五张牌的行上,那么玩家将收到这五张牌,这是在回合结束时总计上的罚球点。
6 nimmt!是一款不完整的信息和大量随机性的竞争游戏。表现良好需要相当多的计划。同时的游戏表现出色,使自己想到游戏和虚张声势,而某些长期策略对于避免最终处于困难的最终比赛位置是必要的。
我们实施了6个NIMMT的简化版本!作为Openai健身环境。与原始游戏不同的是,在所有堆栈上玩的卡低于最后一张卡时,玩家无法自由选择要替换哪种堆栈,而是总是以最小的罚款点占用堆栈。
到目前为止,我们已经实施了以下代理:
作为第一次测试,我们进行了一个简单的自我比赛。从五个未经训练的代理商开始,我们总共打了4000场比赛。对于每个游戏,我们随机选择两个,三个或四个代理商进行游戏(和学习)。每400场比赛我们都会克隆出表现最好的代理商,并踢出了一些表现较差的球员。最后,我们只是保留了每个代理类型的最佳实例。
在所有游戏中的结果:
| 代理人 | 玩游戏 | 平均分数 | 赢得分数 | Elo |
|---|---|---|---|---|
| alpha0.5 | 2246 | -7.79 | 0.42 | 1806年 |
| MCS | 2314 | -8.06 | 0.40 | 1745年 |
| 宏cer | 1408 | -12.28 | 0.18 | 1629年 |
| D3QN | 1151 | -13.32 | 0.17 | 1577年 |
| 随机的 | 1382 | -13.49 | 0.19 | 1556年 |
这就是如何在比赛过程中开发的模型的性能(以ELO的测量):
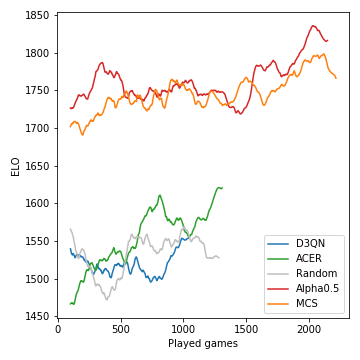
蒙特卡洛树搜索至关重要,并导致了强大的玩家。另一方面,无模型的RL代理甚至努力清楚地表现出随机基线的表现。由于游戏的随机性质,赢得概率和ELO差异并不像国际象棋那样激烈。请注意,我们没有调整许多超参数。
在这个自我播放阶段之后,Alpha0.5代理人面对Merle,这是最好的6个NIMMT之一!我们小组的朋友参加了5场比赛。这些是分数:
| 游戏 | 1 | 2 | 3 | 4 | 5 | 和 |
|---|---|---|---|---|---|---|
| 梅尔 | -10 | -16 | -11 | -3 | -4 | -44 |
| alpha0.5 | -1 | -3 | -14 | -8 | -6 | -32 |
假设您安装了Anaconda,请与
git clone [email protected]:johannbrehmer/rl-6nimmt.git
并用
conda env create -f environment.yml
conda activate rl
simple_tournament.ipynb都展示了人类玩家和受过训练的代理商之间的代理人自我玩法和游戏。
由约翰·布雷默(Johann Brehmer)和马塞尔·古施(Marcel Gutsche)组合在一起。


