rl 6 nimmt
1.0.0
6 NIMMT! 1994 년부터 2 ~ 10 명의 선수를위한 수상 경력에 빛나는 카드 게임입니다. Wikipedia 인용 :
이 게임에는 104 개의 카드가 있으며 각각은 숫자가 있고 페널티 포인트를 나타내는 1 ~ 7 개의 황소의 머리 기호가 있습니다. 모든 플레이어가 선택한 카드 하나를 테이블에 놓는 곳에서 10 턴이 진행됩니다. 배치 된 카드는 고정 규칙에 따라 4 개의 행으로 배열됩니다. 이미 5 장의 카드가있는 행에 배치 된 경우 플레이어는 5 장의 카드를받습니다.
6 NIMMT! 불완전한 정보와 많은 확률 론적 경쟁 게임입니다. 잘 플레이하려면 상당한 계획이 필요합니다. 동시 게임 플레이는 마음의 게임과 블러 핑에 적합하며, 어려운 종료 게임 위치에서 끝나는 것을 피하기 위해서는 장기 전략이 필요합니다.
우리는 6 NIMMT의 약간 단순화 된 버전을 구현했습니다! Openai 체육관 환경으로. 원래 게임과 달리 모든 스택에서 마지막 카드보다 낮은 카드를 플레이 할 때 플레이어는 교체 할 스택을 자유롭게 선택할 수는 없지만 대신 가장 적은 수의 페널티 포인트로 스택을 가져갑니다.
지금까지 우리는 다음 에이전트를 구현했습니다.
첫 번째 테스트로서, 우리는 간단한 셀프 플레이 토너먼트를 운영했습니다. 훈련받지 않은 5 명의 에이전트로 시작하여 총 4000 개의 게임을했습니다. 각 게임마다 우리는 무작위로 2, 3 또는 4 명의 에이전트를 선택하고 배웁니다. 400 개 게임마다 우리는 최고의 성과를 거두는 에이전트를 복제하고 가난한 성과를 거두었습니다. 결국 우리는 방금 각 에이전트 유형의 최상의 인스턴스를 유지했습니다.
모든 게임에 대한 결과 :
| 대리인 | 게임이 재생되었습니다 | 평균 점수 | 분수 승리 | 엘로 |
|---|---|---|---|---|
| alpha0.5 | 2246 | -7.79 | 0.42 | 1806 |
| MC | 2314 | -8.06 | 0.40 | 1745 |
| 에이커 | 1408 | -12.28 | 0.18 | 1629 |
| D3QN | 1151 | -13.32 | 0.17 | 1577 |
| 무작위의 | 1382 | -13.49 | 0.19 | 1556 |
이것이 토너먼트 과정에서 개발 된 모델의 성능 (ELO로 측정)을 수행하는 방법입니다.
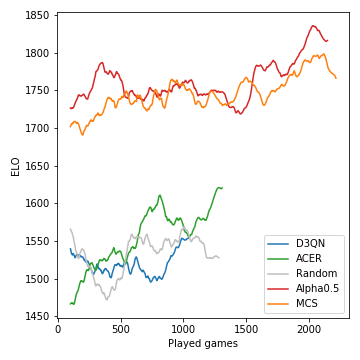
Monte-Carlo Tree Search는 중요하며 강력한 플레이어로 이어집니다. 반면에 모델이없는 RL 에이전트는 랜덤 기준을 명확하게 성능이 우수하기 위해 고군분투합니다. 게임의 확률 론적 특성으로 인해, 승리 확률과 ELO 차이는 체스에게는 거의 과감하지 않습니다. 우리는 많은 과수 분리기를 조정하지 않았습니다.
이 자체 플레이 단계 후, Alpha0.5 에이전트는 최고의 6 NIMMT 중 하나 인 Merle을 향했습니다! 우리 친구 그룹의 플레이어, 5 게임. 이것들은 점수입니다.
| 게임 | 1 | 2 | 3 | 4 | 5 | 합집합 |
|---|---|---|---|---|---|---|
| 멀 | -10 | -16 | -11 | -3 | -4 | -44 |
| alpha0.5 | -1 | -3 | -14 | -8 | -6 | -32 |
Anaconda가 설치되어 있다고 가정하면 repo를 복제하십시오
git clone [email protected]:johannbrehmer/rl-6nimmt.git
가상 환경을 만듭니다
conda env create -f environment.yml
conda activate rl
인간 플레이어와 훈련 된 에이전트 간의 에이전트 자체 플레이와 게임은 모두 Simple_tournament.ipynb에서 시연됩니다.
Johann Brehmer와 Marcel Gutsche가 함께 모으십시오.


