YOLaT VectorGraphicsRecognition
1.0.0
พื้นที่เก็บข้อมูลนี้คือการใช้งาน Pytorch อย่างเป็นทางการของโมเดลการจดจำกราฟิกเวกเตอร์ที่ทรงพลังสองแบบของเรา
Neurips-2021 Paper: การจดจำกราฟิกเวกเตอร์โดยไม่ต้องแรสเตอร์
กระดาษ TPAMI-20124: กราฟิกเวกเตอร์ที่รับรู้แบบลำดับชั้นและชุดข้อมูลกราฟิกเวกเตอร์ที่ใช้แผนภูมิใหม่
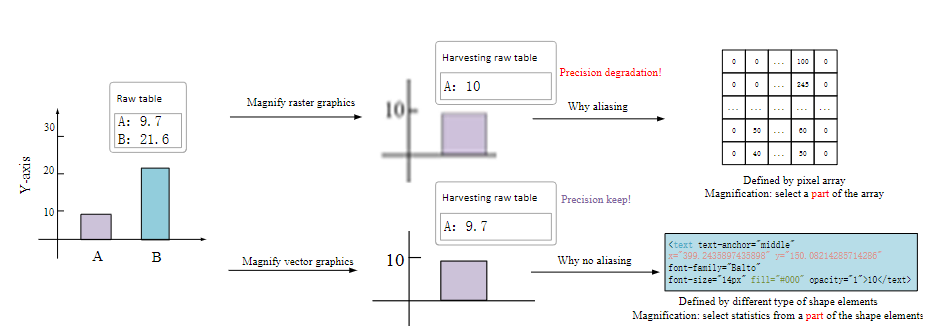
การแสดงผลกราฟิกเวกเตอร์ในอาร์เรย์พิกเซลอาจส่งผลให้ต้นทุนหน่วยความจำหรือการสูญเสียข้อมูลอย่างมีนัยสำคัญดังที่แสดงในรูปที่ 1 ข้างต้นกระบวนการนี้จะยกเลิกข้อมูลโครงสร้างระดับสูงภายในเบื้องต้นซึ่งเป็นสิ่งสำคัญสำหรับงานการจดจำเช่นการระบุมุมและรูปทรง เพื่อสรุปเราเสนอให้คุณดูซีรีย์ข้อความเท่านั้น (YOLAT & YOLAT ++) ซึ่งกล่าวถึงปัญหากับกราฟิกแรสเตอร์โดยใช้เอกสารข้อความของกราฟิกเวกเตอร์เป็นอินพุต
conda create -n your_env_name python=3.8
conda activate your_env_name
sh deepgcn_env_install.sh a) ดาวน์โหลดและคลายซิปชุดข้อมูล FloorPlans ไปยังโฟลเดอร์ชุดข้อมูล: data/FloorPlansGraph5_iter
b) เรียกใช้สคริปต์ต่อไปนี้เพื่อเตรียมชุดข้อมูลสำหรับการฝึกอบรม/การอนุมาน
cd utils
python svg_utils/build_graph_bbox.py a) ดาวน์โหลดและคลายซิปชุดข้อมูลไดอะแกรมไปยังโฟลเดอร์ชุดข้อมูล: data/diagrams
b) เรียกใช้สคริปต์ต่อไปนี้เพื่อเตรียมชุดข้อมูลสำหรับการฝึกอบรม/การอนุมาน
cd utils
python svg_utils/build_graph_bbox_diagram.py cd cad_recognition
CUDA_VISIBLE_DEVICES=0 python -u train.py --batch_size 4 --data_dir data/FloorPlansGraph5_iter --phase train --lr 2.5e-4 --lr_adjust_freq 9999999999999999999999999999999999999 --in_channels 5 --n_blocks 2 --n_blocks_out 2 --arch centernet3cc_rpn_gp_iter2 --graph bezier_cc_bb_iter --data_aug true --weight_decay 1e-5 --postname run182_2 --dropout 0.0 --do_mixup 0 --bbox_sampling_step 10 cd cad_recognition
CUDA_VISIBLE_DEVICES=0 python -u train.py --batch_size 4 --data_dir data/diagrams --phase train --lr 2.5e-4 --lr_adjust_freq 9999999999999999999999999999999999999 --in_channels 5 --n_blocks 2 --n_blocks_out 2 --arch centernet3cc_rpn_gp_iter2 --graph bezier_cc_bb_iter --data_aug true --weight_decay 1e-5 --postname run182_2 --dropout 0.0 --do_mixup 0 --bbox_sampling_step 5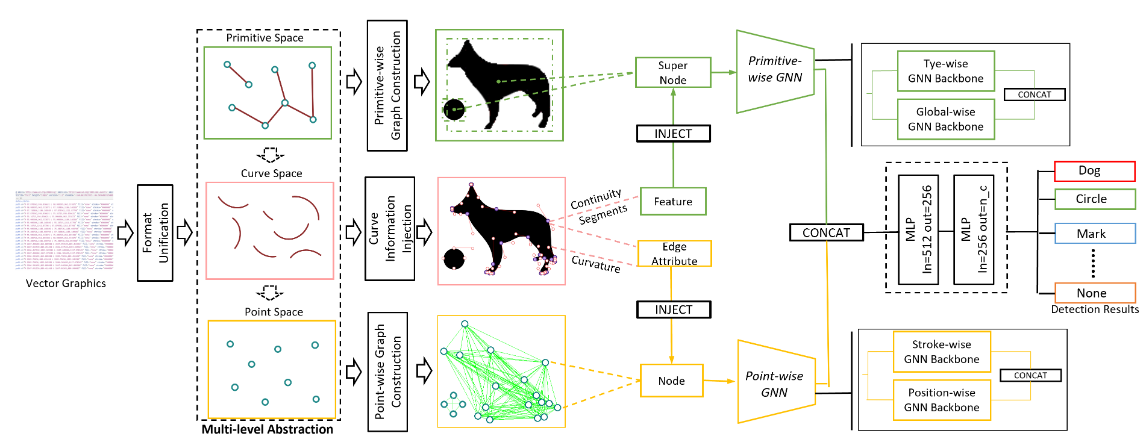
YOLAT ++ ได้รับการแนะนำโดยมีโครงสร้างแบบลำดับชั้นที่ออกแบบมาสำหรับ VGS ซึ่งประกอบไปด้วยสามระดับ: ดั้งเดิมเส้นโค้งและจุด นอกจากนี้ YOLAT ++ ยังใช้กลยุทธ์การปรับปรุงตำแหน่งที่รับรู้เพื่อสร้างความแตกต่างอย่างมีประสิทธิภาพ
bibtex:
@inproceedings{jiang2021recognizing,
title={{Recognizing Vector Graphics without Rasterization}},
author={Jiang, Xinyang and Liu, Lu and Shan, Caihua and Shen, Yifei and Dong, Xuanyi and Li, Dongsheng},
booktitle={Proceedings of Advances in Neural Information Processing Systems (NIPS)},
volume={34},
number={},
pages={},
year={2021}}
@inproceedings{yolat24,
title={{Hierarchical Recognizing Vector Graphics and A New Chart-based Vector Graphics Dataset}},
author={Shuguang Dou, Xinyang Jiang, Lu Liu, Lu Ying, Caihua Shan, Yifei Shen, Xuanyi Dong, Yun Wang, Dongsheng Li, Cairong Zhao},
booktitle={IEEE Transactions on Pattern Analysis and Machine Intelligence},
volume={},
number={},
pages={},
year={2024}}
กรุณาพิจารณา? แสดงโครงการของเราเพื่อแบ่งปันกับชุมชนของคุณหากคุณพบว่าพื้นที่เก็บข้อมูลนี้มีประโยชน์!
มาตรฐานสำหรับการตรวจจับและการทำความเข้าใจแผนภูมิที่ใช้ VG


