Attendance using Face
1.0.0
Это моя попытка сделать систему распознавания лица для посещаемости в классе или офисе. Система основана на специальном типе архитектуры CNN, известной как сиамская сеть. Такая сеть обучена генерировать очень точный и почти уникальный вектор 128, учитывая, что изображения лица, которые подают в сеть, правильно выровнены и обрезаны.
Тогда еще одна плотная нейронная сеть обучена привлекать входные вкладки. Вторая нейронная сеть предназначена только для классификационных целей. Тогда человек, которого идентифицируется система, его/ее посещаемость в системе увеличивается на 1.
Когда система закрыта, создается файл Excel, состоящий из посещаемости всех студентов.
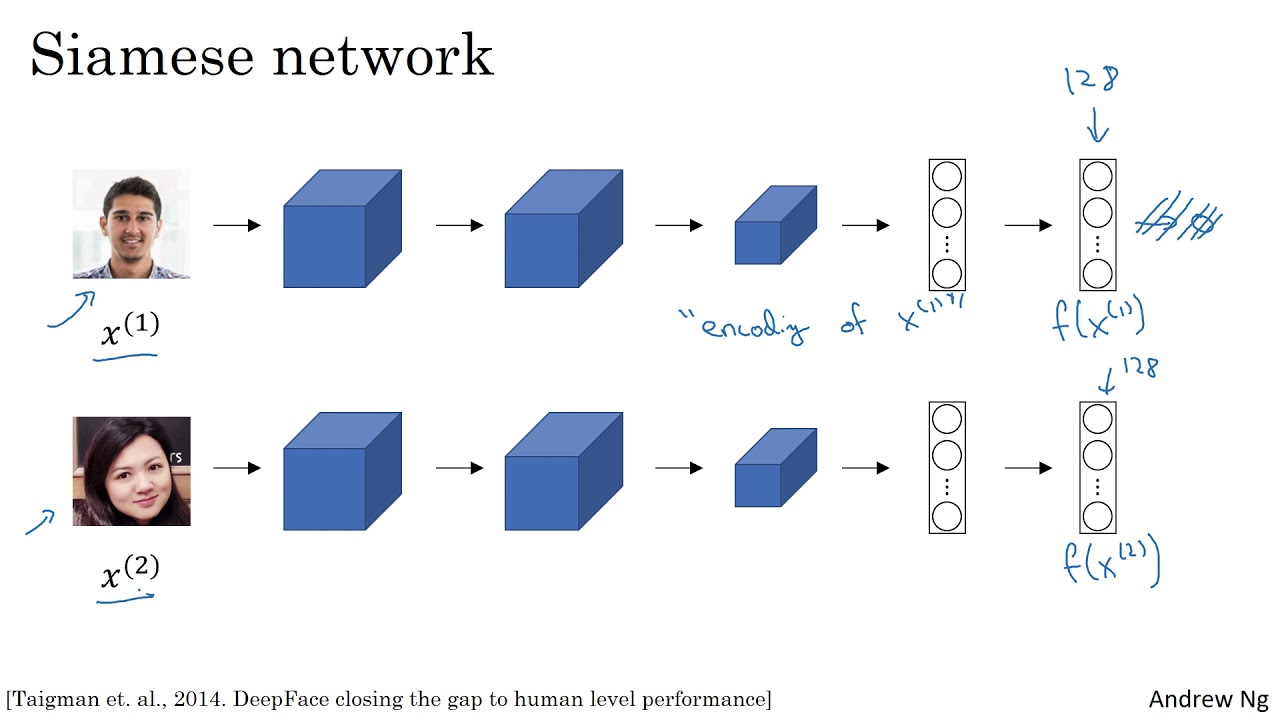 взят из Deeplearning.ai.
взят из Deeplearning.ai.
Вы можете посмотреть эти видео. Профессор Эндрю Нг дает отличное объяснение этим сетям.
Я загрузил модель Facenet от Nyoki-Mtl Githubu
Эта сеть предварительно подготовлена в довольно большом наборе данных и производит уникальный 128 -размерный вектор для конкретного лица, учитывая, что подаренные его изображения обрезаны только в область лица и выявлены. Размер входа изображения для этого Netowrk составляет 160x160x3
Обнаружение лица достигается с использованием каскадов HAAR OpenCV. Обнаружение лица Haarcascade используется для обнаружения лица, и эта обнаруженная область подается в генератор встраивания.
Вторая нейронная сеть имеет плотную архитектуру и используется для классификации. Вторая нейронная сеть принимает вход 128 -размерного вектора и выявляет вероятность того, что лицо станет одним из студентов. Архитектура второй нейронной сети - это 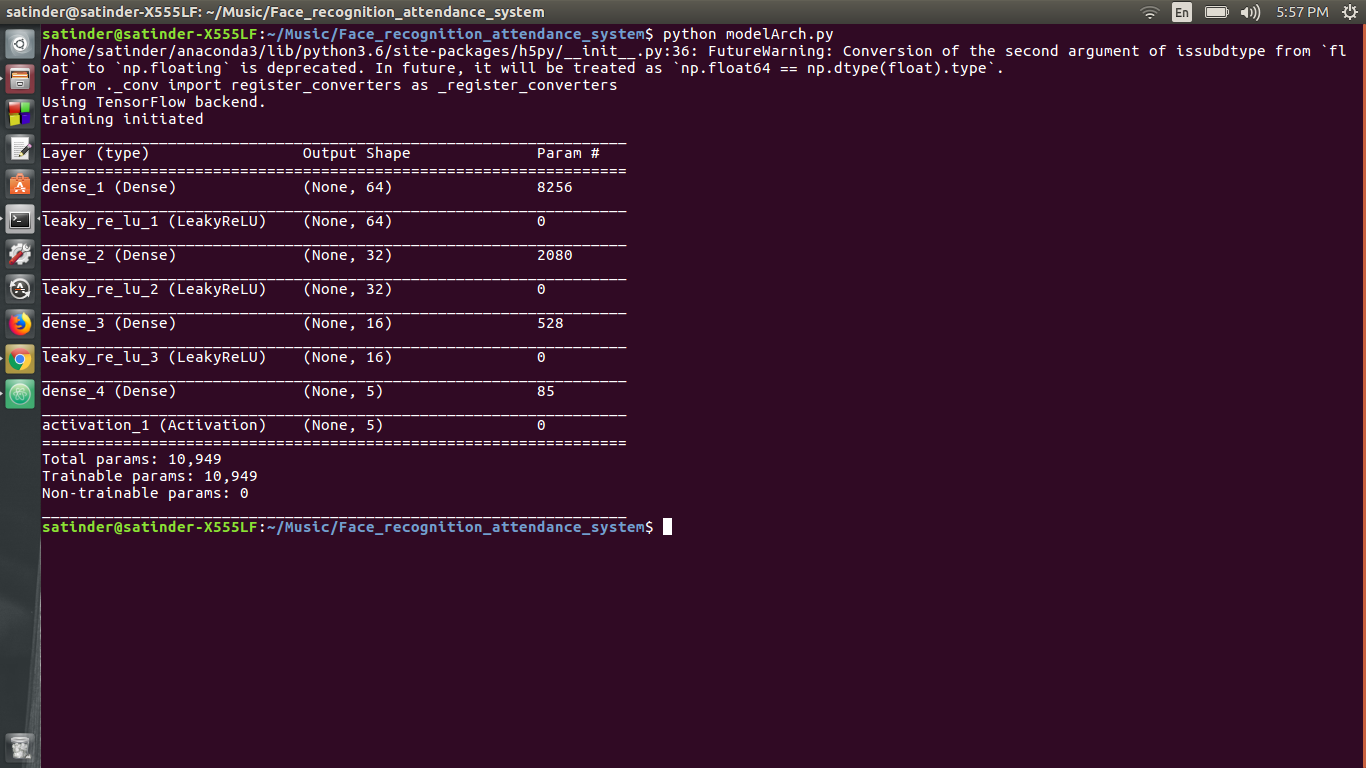
Используемая база данных является MongoDB. Pymongo используется для добавления, удаления записей, а также повышения посещаемости конкретного студента. 
После закрытия приложения создается файл Excel. Этот файл Excel содержит посещаемость всех студентов.
Начните свой терминал CMD в зависимости от вашей ОС.
Если у вас есть графический процессор NVIDIA, убедитесь, что у вас есть предпосылки для установки графического процессора TensorFlow (см. Официальный сайт). Затем используйте это
PIP установка -R TERDENS_GPU.TXT
Если у вас нет графического процессора, используйте эту команду
pip install -r requirements_cpu.txt
1) Установите все требования
2) Сделайте папку с именем «Люди» без кавычек
3) Теперь запустите Generating_training_data.py, когда это запускается, введите имя человека, за которым следует индекс, начиная с нуля, например, если я хочу генерировать данные для «Рави», я напишу «Ravi0», и для следующего имени напишите «secondname1», просто убедитесь, что индекс, предоставленный всем в порядке увеличения. Теперь поместите все эти папки в папку People 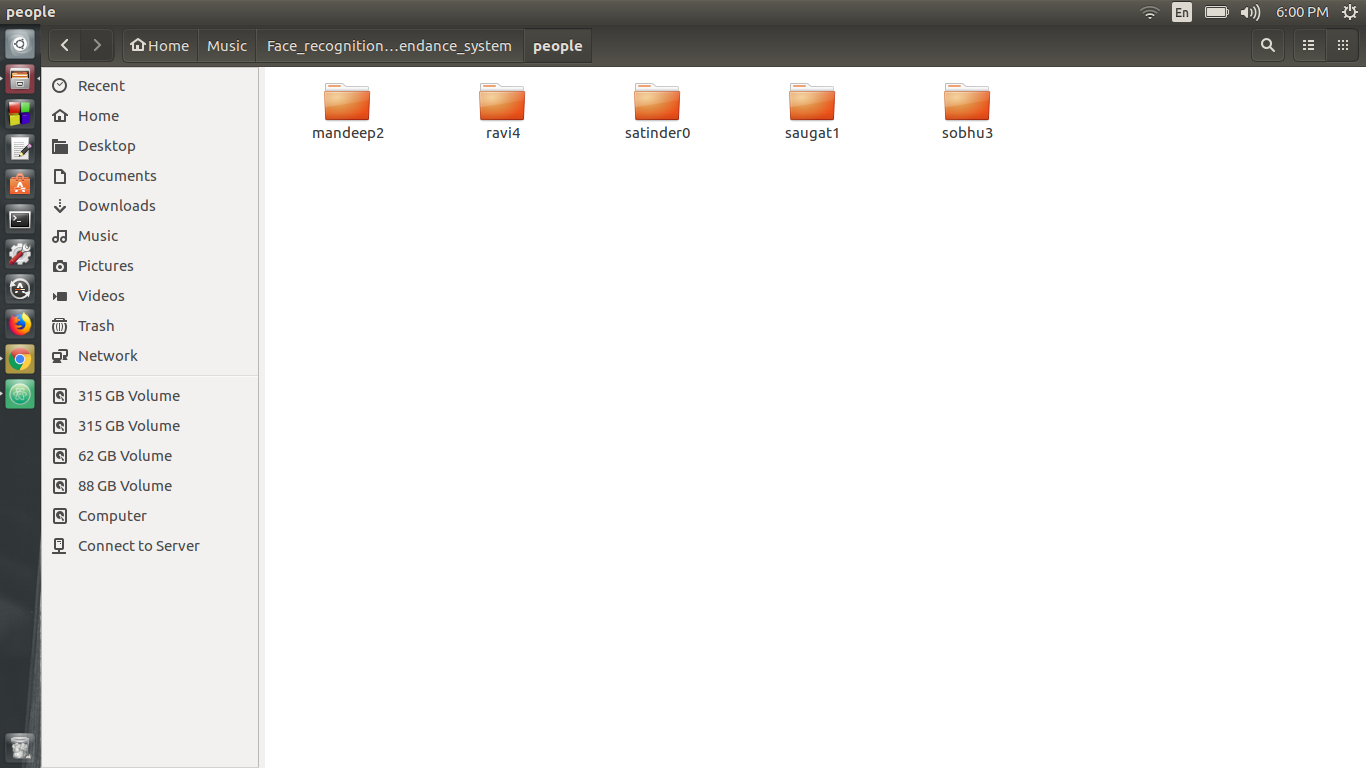
4) Теперь в Trainer.py Измените количество классов в соответствии с количеством папки, а затем запустите Trainer.py
5) Модель будет обучена.
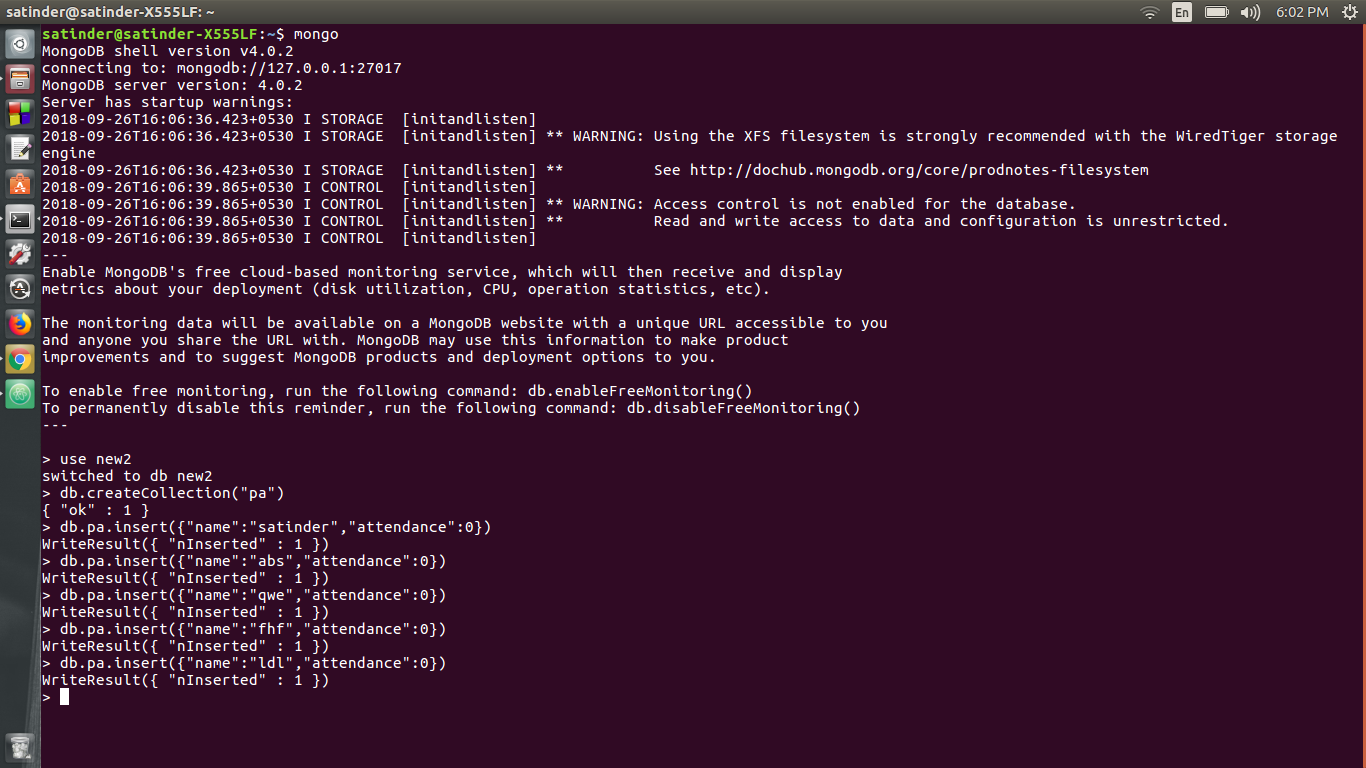
6) Теперь создайте базу данных, используя MongoDB. Введите все имена с их посещаемостью. Это может быть достигнуто
а) Создать базу данных с именем «Новая»
б) Создать коллекцию под названием "PA"
в) Добавить энтезии. Например, db.pa.insert ({"name": "satinder", "посещаемость": 0})
7) Теперь Open Inconcoverizer.py и измените словарь «A» и людей в соответствии с вашими данными. Ключом массива «a» является индекс людей, а данные являются указывающей переменной, которая используется для указания того, что в конкретном сеансе, если посещаемость человека была взята.
8) Словарь «Люди» является самоуверенем.
9) Запустите unconduction.py, чтобы распознать людей. Их посещаемость будет зарегистрирована в базе данных MongoDB.
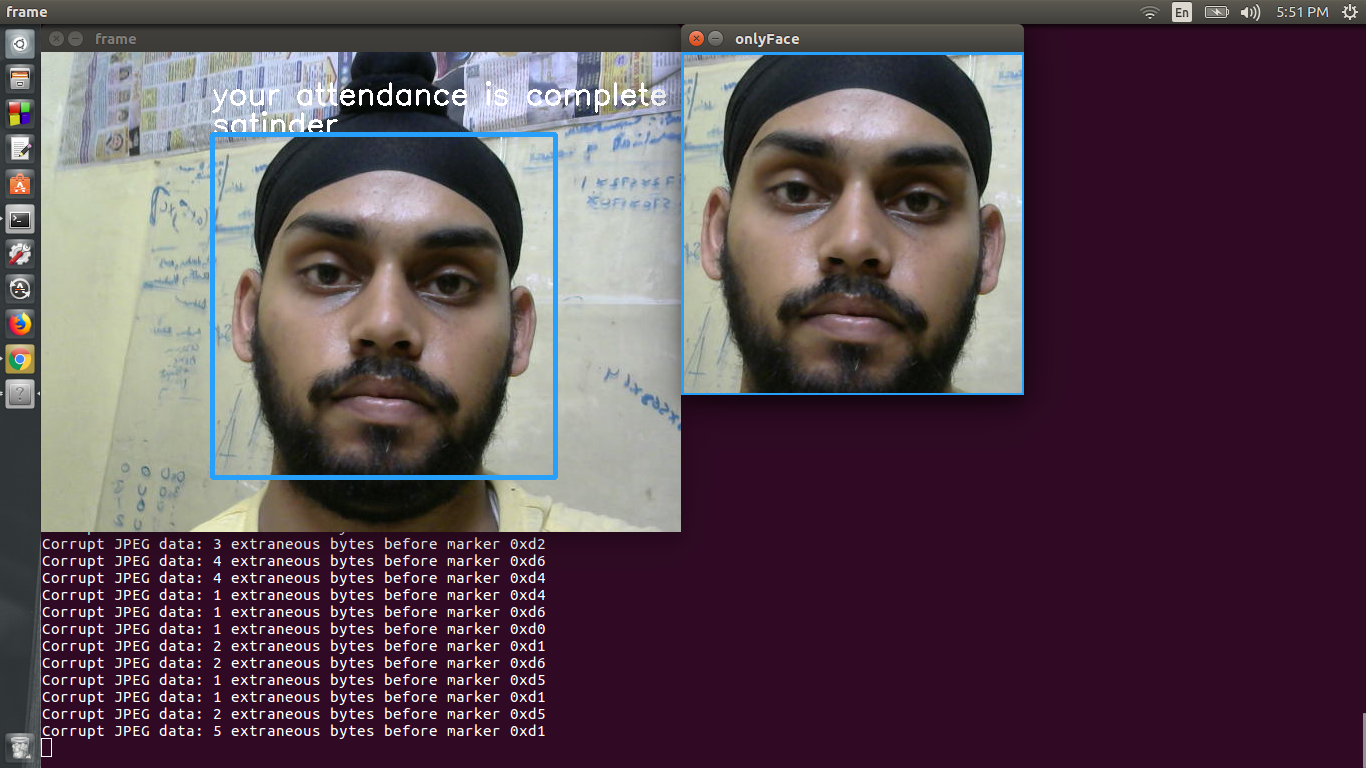
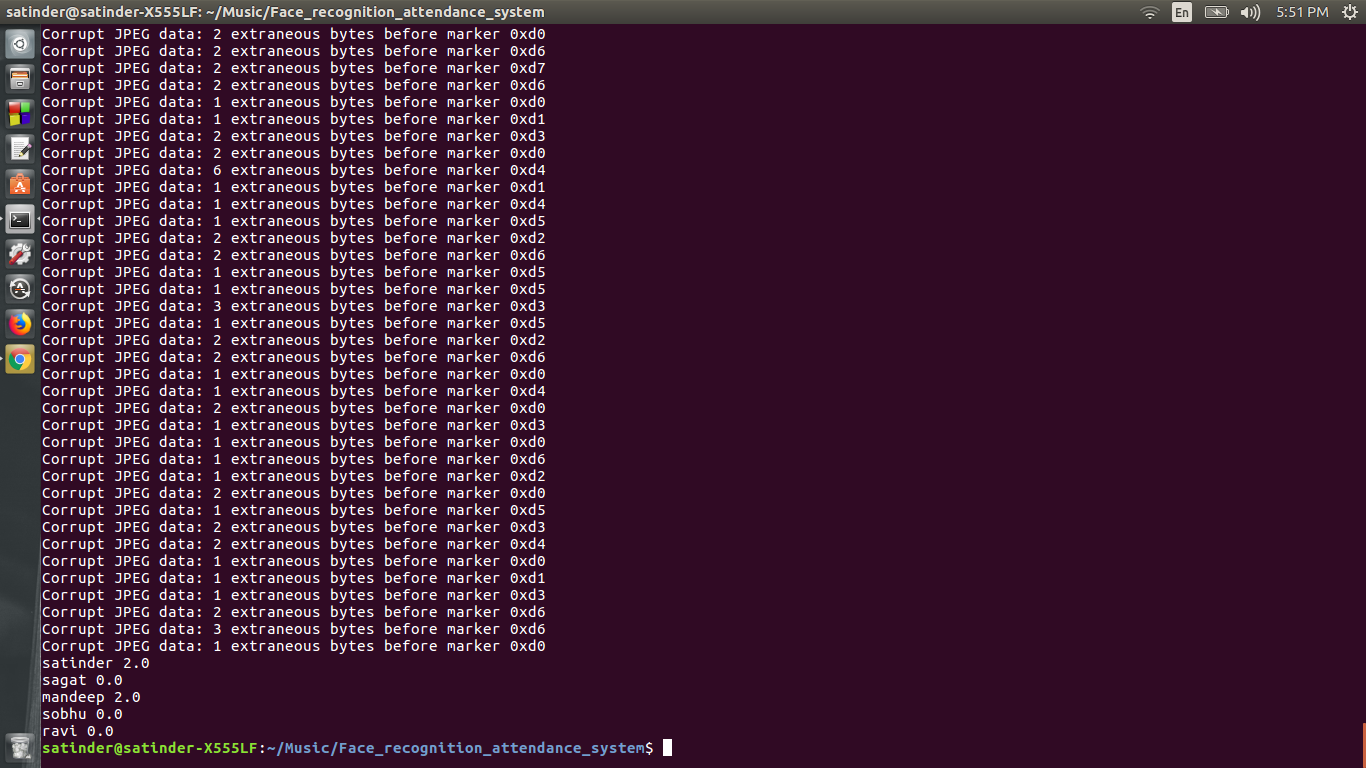
Если вам это понравится, вам наверняка понравится и другие мои репо. Вы также можете взглянуть на мой канал на YouTube "Reactor Science". Если у вас есть какие -либо сомнения, вы можете связаться со мной на моей странице в Facebook "Наука реакторов"
1) Глубокое обучение с питоном Франсуа Чолле
2) keras.io
3) Deeplearning.ai от Coursera (профессор Эндрю Нг)
4) CS231N от Стэнфорда
5) Pyimagesearch.com (Адриан Розенберг)
6) Брэндон Амос (GitHub: https: //github.com/bamos)


