Attendance using Face
1.0.0
هذه هي محاولتي لجعل نظام التعرف على الوجه للفصول الدراسية أو الحضور المكتبي. يعتمد النظام على نوع خاص من بنية CNN المعروفة باسم شبكة Siamese. يتم تدريب هذه الشبكة على إنشاء ناقل دقيق للغاية وفريد من نوعه تقريبًا بالنظر إلى أن صور الوجه التي يتم تغذيتها إلى الشبكة يتم محاذاة وتقطيع بشكل صحيح.
ثم يتم تدريب شبكة عصبية أخرى كثيفة مع إدخال هذه التضمينات. الشبكة العصبية الثانية هي فقط لأغراض التصنيف. ثم يتم زيادة الشخص الذي تم تحديده من قبل النظام ، وحضوره في النظام بمقدار 1.
عند إغلاق النظام ، يتم إنشاء ملف Excel الذي يتكون من حضور جميع الطلاب.
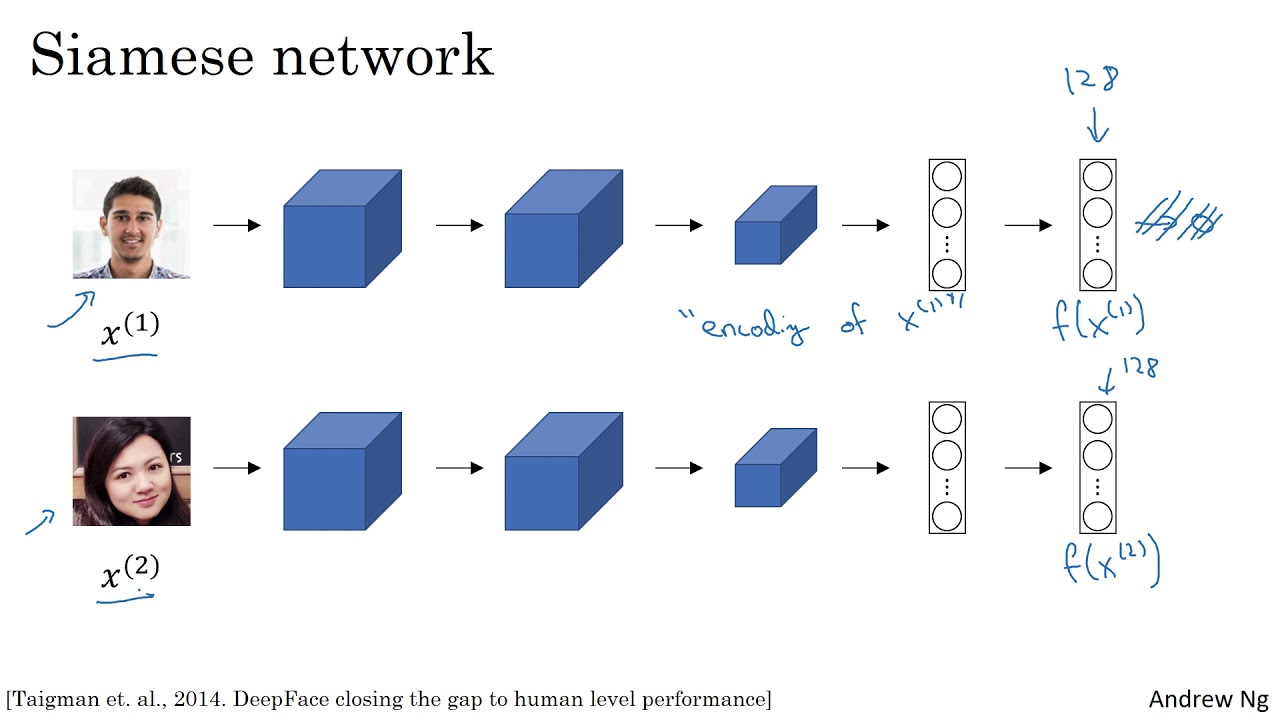 مأخوذة من deeplearning.ai.
مأخوذة من deeplearning.ai.
يمكنك مشاهدة مقاطع الفيديو هذه. يقدم البروفيسور أندرو نغ شرحًا ممتازًا لهذه الشبكات.
لقد قمت بتنزيل نموذج الوجه المسبق من Nyoki-MTL Githubu
تم تجهيز هذه الشبكة على مجموعة بيانات كبيرة جدًا ، وتنتج متجهًا فريدًا من 128 أبعادًا للوجه المعين بالنظر إلى الصور التي يتم تغذيتها إلى منطقة الوجه فقط ويتم ربطها. حجم إدخال الصورة لهذا NetOwrk هو 160x160x3
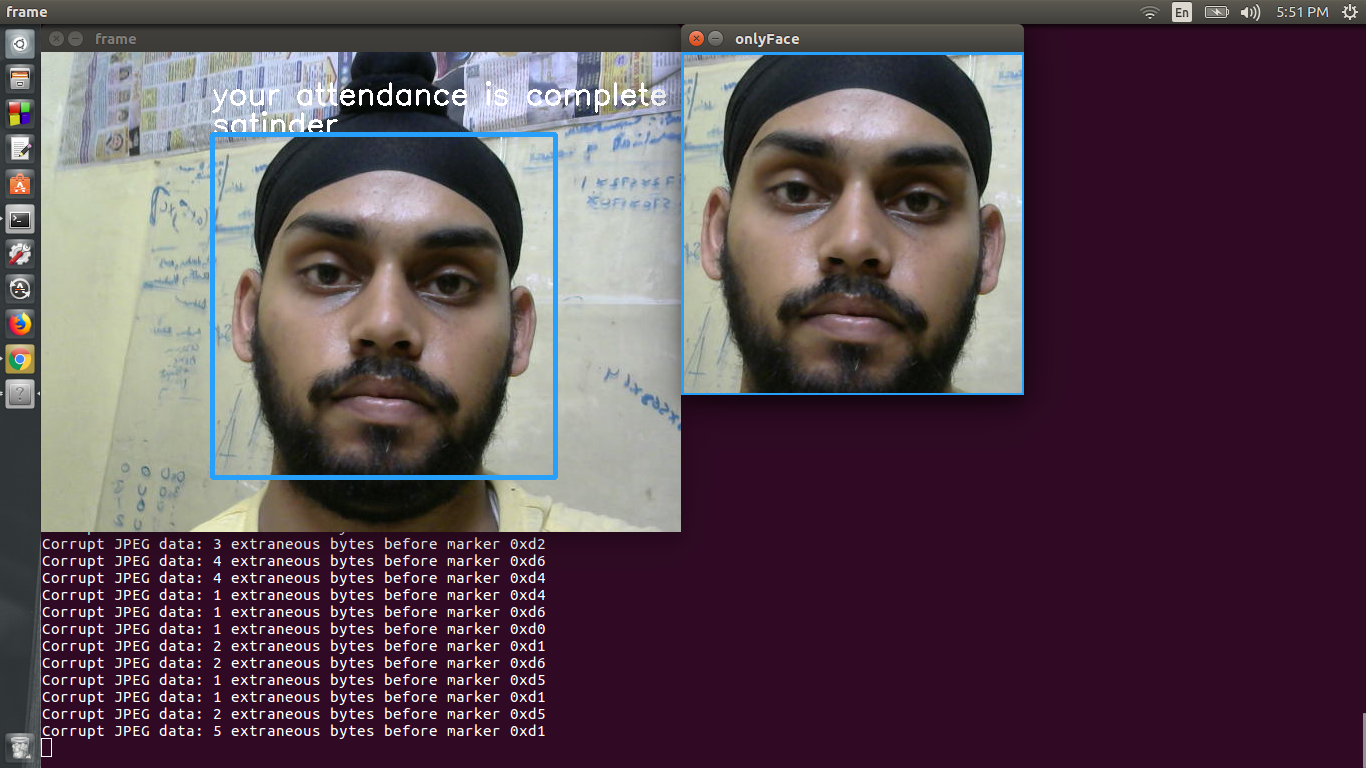
يتم اكتشاف الوجه باستخدام شلالات HAAR من OpenCV. يتم استخدام Haarcascade للكشف عن الوجه للكشف عن الوجه ويتم تغذية هذه المنطقة المكتشفة إلى مولد التضمين.
الشبكة العصبية الثانية لها بنية كثيفة وتستخدم للتصنيف. تأخذ الشبكة العصبية الثانية مدخلات المتجه 128 الأبعاد و ouputs احتمال أن يكون الوجه أحد الطالب. بنية الشبكة العصبية الثانية هي 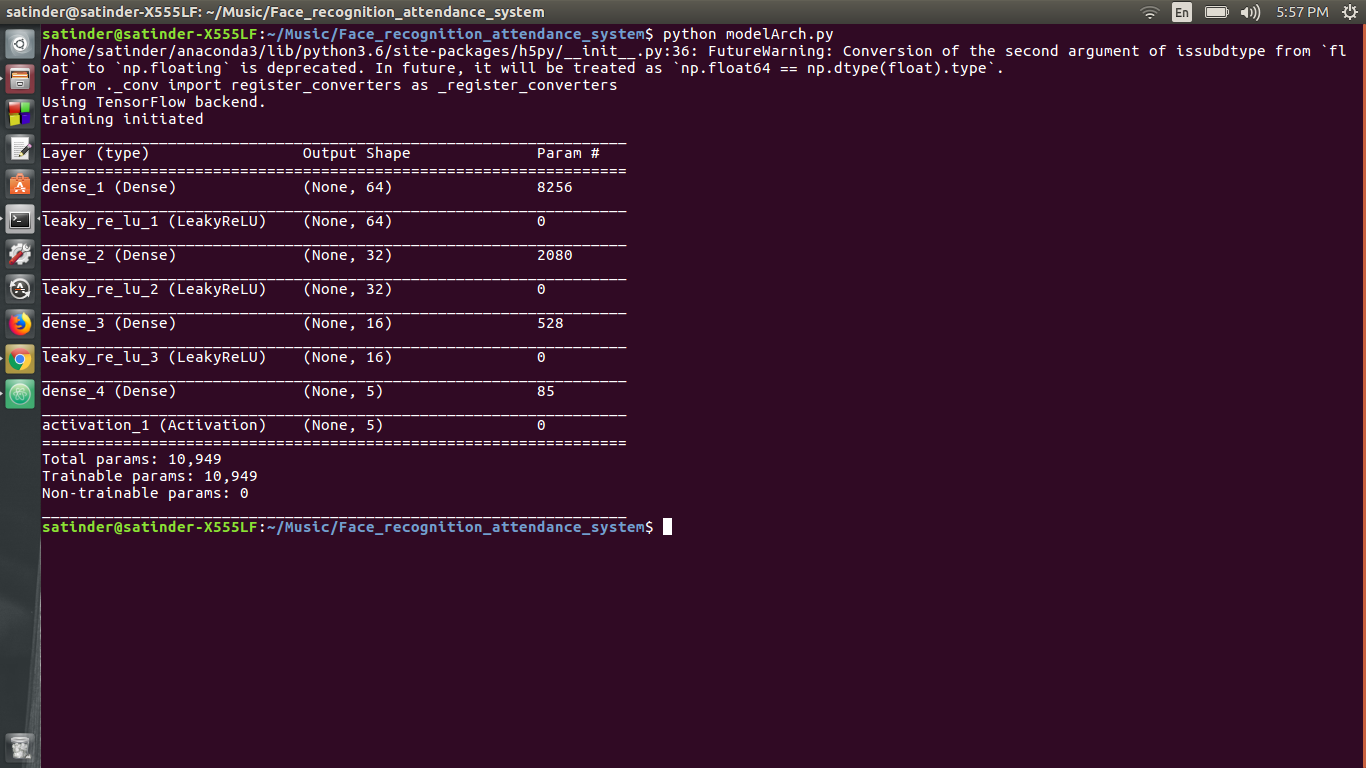
قاعدة البيانات المستخدمة هي mongodb. يتم استخدام Pymongo لإضافة وحذف السجلات وكذلك زيادة حضور الطالب المعين. 
بعد إغلاق التطبيق ، يتم إنشاء ملف Excel. يحتوي ملف Excel هذا على حضور جميع الطالب.
ابدأ محطة CMD الخاصة بك اعتمادًا على نظام التشغيل الخاص بك.
إذا كان لديك وحدة معالجة الرسومات NVIDIA ، فتأكد من أن لديك المتطلبات الأساسية لتركيب GPU TensorFlow (راجع الموقع الرسمي). ثم استخدم هذا commmand
PIP تثبيت -r متطلبات _gpu.txt
في حال لم يكن لديك وحدة معالجة الرسومات ثم استخدم هذا الأمر
pip install -r requirements_cpu.txt
1) تثبيت جميع المتطلبات
2) اصنع مجلد اسمه "الناس" بدون اقتباسات
3) قم الآن بتشغيل internate_training_data.py ، عند تشغيل هذا ، أدخل اسم الشخص الذي يليه فهرس يبدأ من الصفر على سبيل المثال ، إذا كنت أرغب في إنشاء بيانات لـ "Ravi" ، فسوف أكتب "Ravi0" وللاسم التالي يكتب "SecondName1" ، فقط تأكد من أن الفهرس المقدم للجميع في ترتيب متزايد. الآن ضع كل هذه المجلدات في مجلد الناس 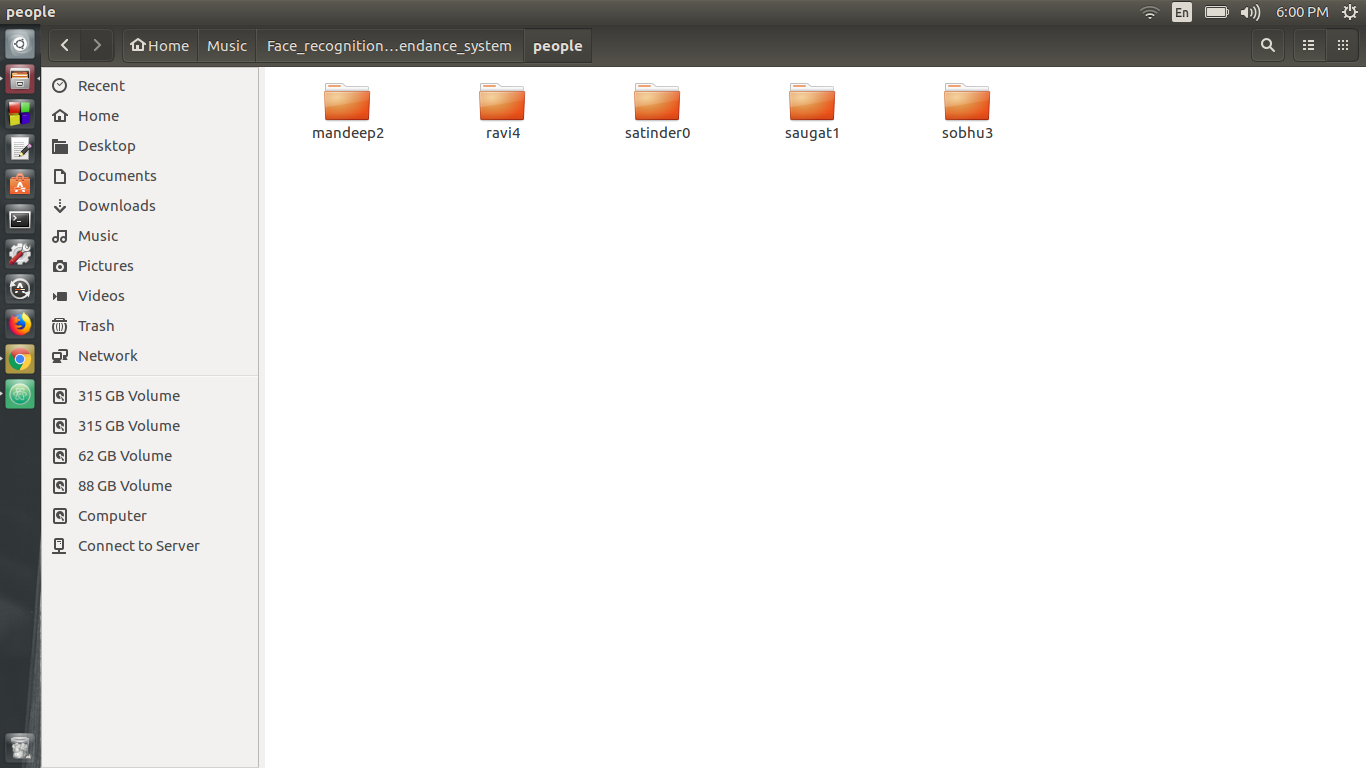
4) الآن في Trainer.py قم بتغيير عدد الفئات وفقًا لعدد المجلد ثم تشغيل Trainer.py
5) سيتم تدريب النموذج.
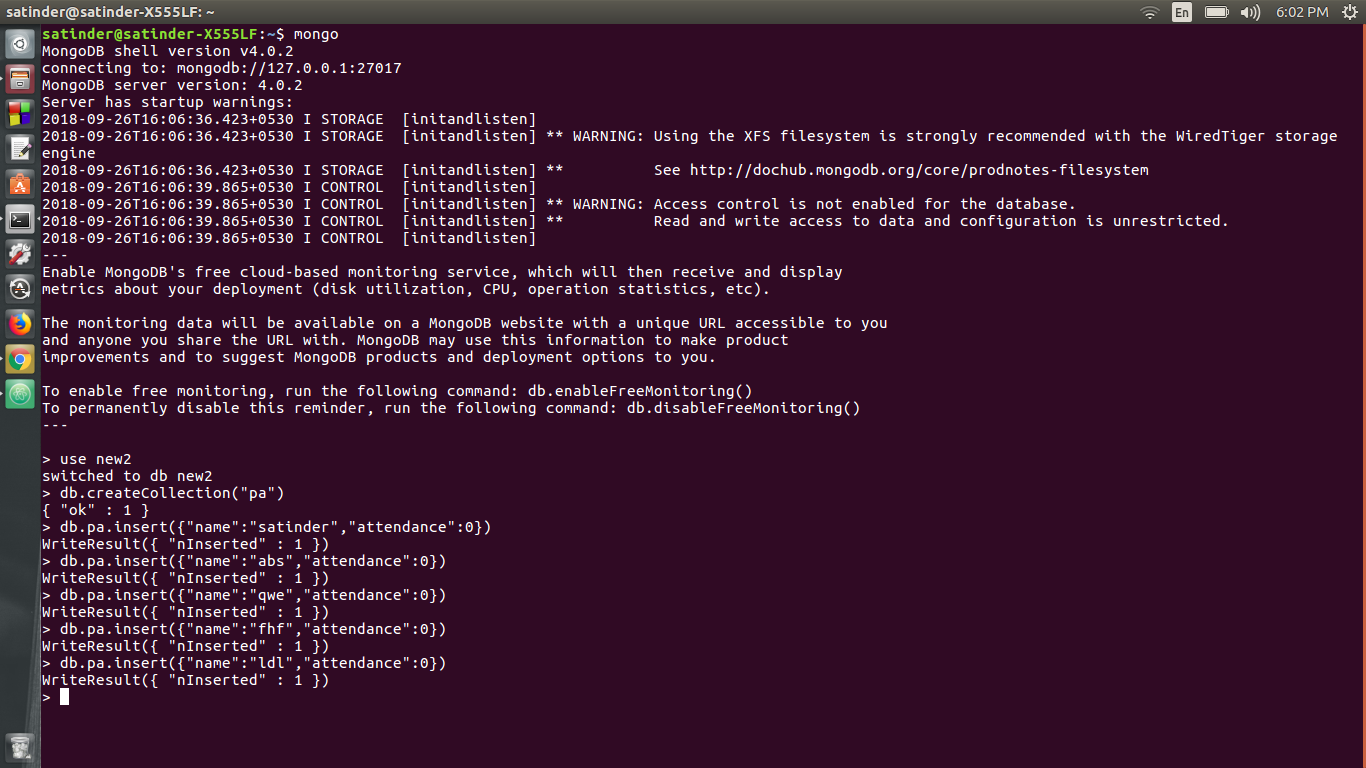
6) الآن إنشاء قاعدة بيانات باستخدام MongoDB. أدخل جميع الأسماء مع حضورهم. هذا يمكن أن يتحقق من قبل
أ) إنشاء قاعدة بيانات تدعى "جديد"
ب) إنشاء مجموعة تسمى "PA"
ج) إضافة المعوية. لـ eg db.pa.insert ({"name": "Satinder" ، "الحضور": 0})
7) افتح الآن التعرف على explizer.py وقم بتغيير القاموس "A" والأشخاص وفقًا لبياناتك. مفتاح الصفيف "A" هو فهرس الأشخاص والبيانات هو متغير يشير إلى أنه يستخدم للإشارة إلى أنه في جلسة معينة ، إذا تم أخذ حضور الشخص.
8) القاموس "الناس" هو توضيحي الذات.
9) تشغيل التعرف على mostizer.py للتعرف على الناس. سيتم تسجيل حضورهم في قاعدة بيانات MongoDB.
إذا أعجبك ذلك ، فسوف تحب بالتأكيد إعادة الشراء الأخرى. يمكنك أيضًا إلقاء نظرة على قناة YouTube الخاصة بي "Reactor Science". إذا كان لديك أي شكوك ، فيمكنك الاتصال بي على صفحتي على Facebook "Science Reactor"
1) التعلم العميق مع بيثون من فرانسوا تشوليت
2) Keras.io
3) Deeplearning.ai من قبل Coursera (البروفيسور أندرو نغ)
4) CS231N بواسطة ستانفورد
5) Pyimagesearch.com (أدريان روزنبرغ)
6) براندون عاموس (Github: https: //github.com/bamos)


