Prompt Learning
1.0.0
Beta MLM参数更新hard prompt MLM
Motivação
- Como o custo de rotulagem do idioma, domínio e tarefa é extremamente alto, as amostras rotuladas são preciosas ao aplicar modelos de linguagem a tarefas a jusante, e os cenários de poucos tiros são muito comuns, o que restringe o aprendizado supervisionado, que atraiu estudiosos e profissionais para executar tarefas de NLP no ambiente de poucas filmagens.
- A introdução de explicação de texto/descrição da tarefa ao modelo de idioma pré-treinamento pode resolver efetivamente algumas tarefas de PNL (cenário zero-tiro) por uma maneira não supervisionada.
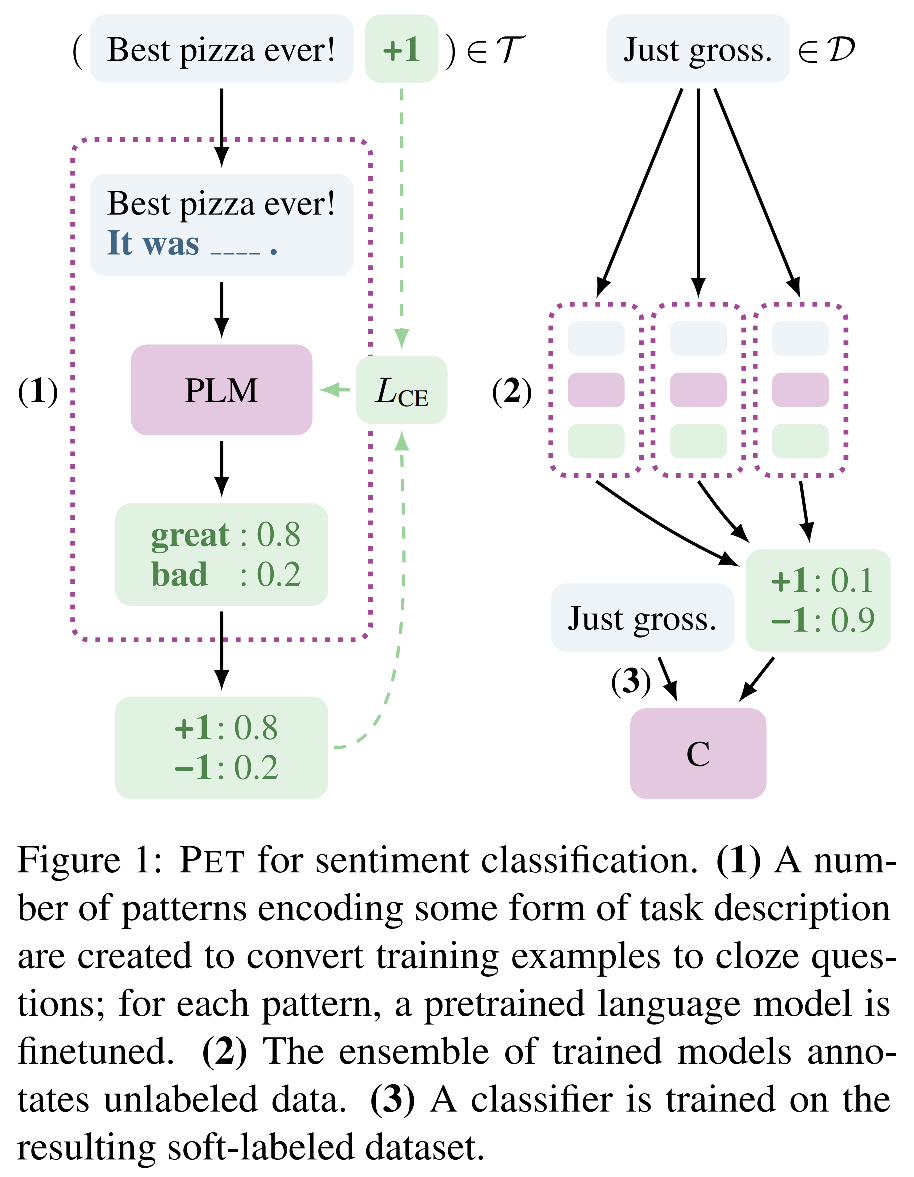
- Tomando todas as considerações, este artigo propõe introduzir treinamento de exploração de padrões, projetar uma estratégia de treinamento semi-supervisionada PET e sua versão aprimorada do IPET e mapear as amostras de entrada (texto) da PNL em uma frase de cloze.
MLM参数更新hard prompt MLM
Motivação
- As estruturas PET e IPET podem lidar apenas com a claze de uma única [máscara], enquanto as tarefas reais podem encontrar várias [máscaras].
- Este artigo é equivalente a uma versão aprimorada do PET e IPET, expandindo os tokens [máscara] para os tokens k [máscara].
Parâmetros de MLM soft prompt MLM参数固定?
Motivação
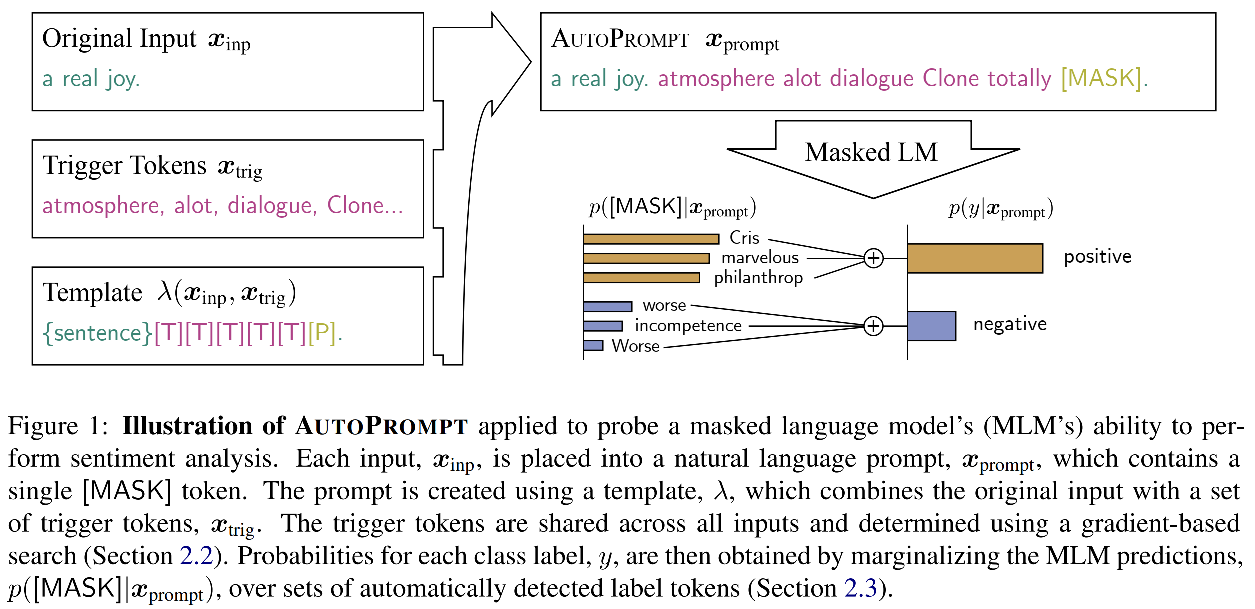
- Ao usar modelos de idiomas pré-treinamento, as tarefas a jusante são definidas como perguntas preenchidas em branco (Modelo de Idioma de Tarefa, se encaixa perfeitamente no modelo de idioma). Use o Propt para comunicar o modelo de pré-treinamento e as tarefas a jusante, o que ajuda a avaliar o conhecimento aprendido no estágio de pré-treinamento sem introduzir um grande número de novos parâmetros.
- No passado, o prompt (prompt) projetado por especialistas é caro e não é intuitivo para muitas tarefas. Além disso, o modelo é altamente sensível às informações de contexto contidas no prompt; portanto, o prompt de design artificial é fácil de introduzir viés.
- Para esse fim, este artigo propõe uma maneira de aprender automaticamente o Propt e o Rótulo.
soft prefix prompt tokens hard input sample prompt tokens MLM参数固定
Motivação
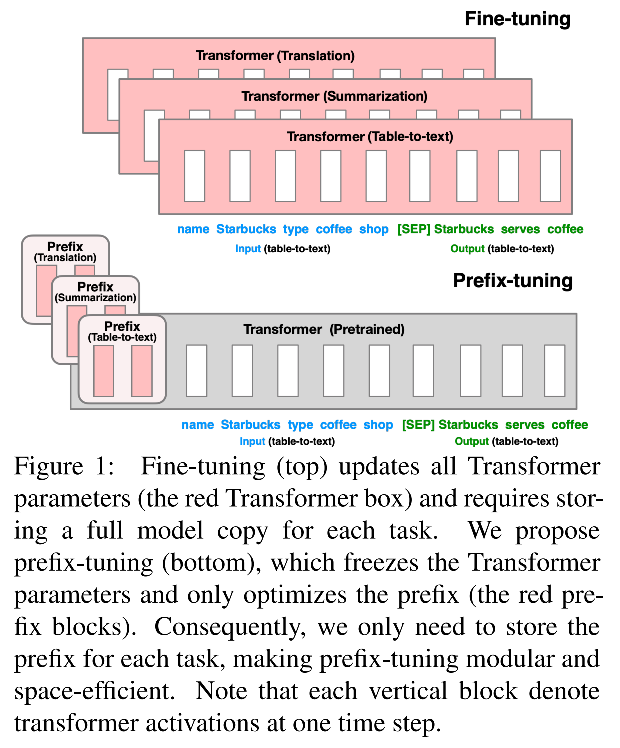
- Ao aplicar um modelo de idioma pré-treinado a tarefas a jusante usando o paradigma pré-trein-tune, geralmente é necessário atualizar os parâmetros do modelo de idioma pré-treinado. Para tarefas diferentes, é necessário ajustar o modelo uma vez e armazenar seus parâmetros, e a sobrecarga de treinamento e armazenamento é cara.
- Este artigo propõe treinar tokens de prompt de prefixo contínuo (prefixo de amostras de entrada) para cada tarefa, e o modelo de linguagem de tendência executa tarefas diferentes.
MLM soft prompt
Motivação
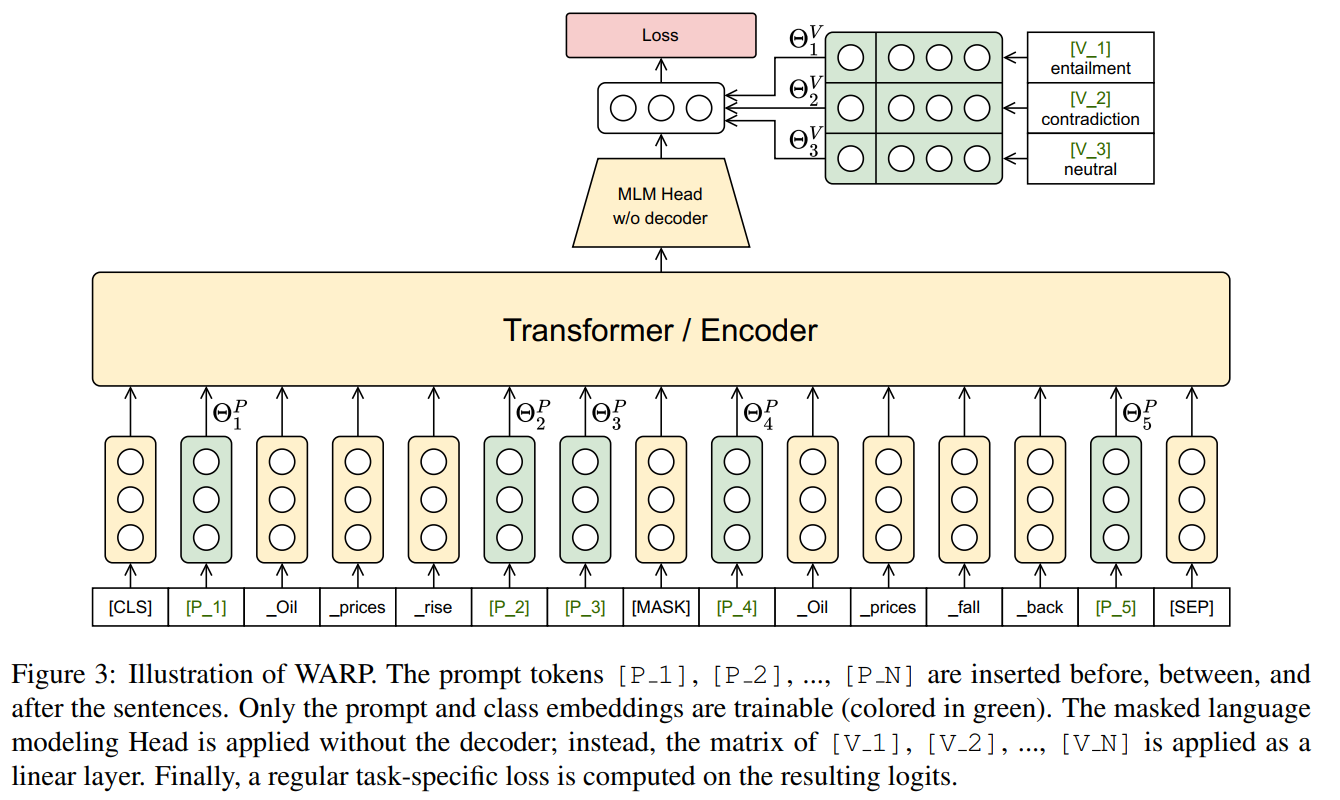
Os parâmetros de MLM soft prompt MLM参数固定,只更新插入的prompt和label
Motivação
Motivação
Motivação
Prompt de prompt hard prompt soft prompt prompt hybrid prompt
Motivação
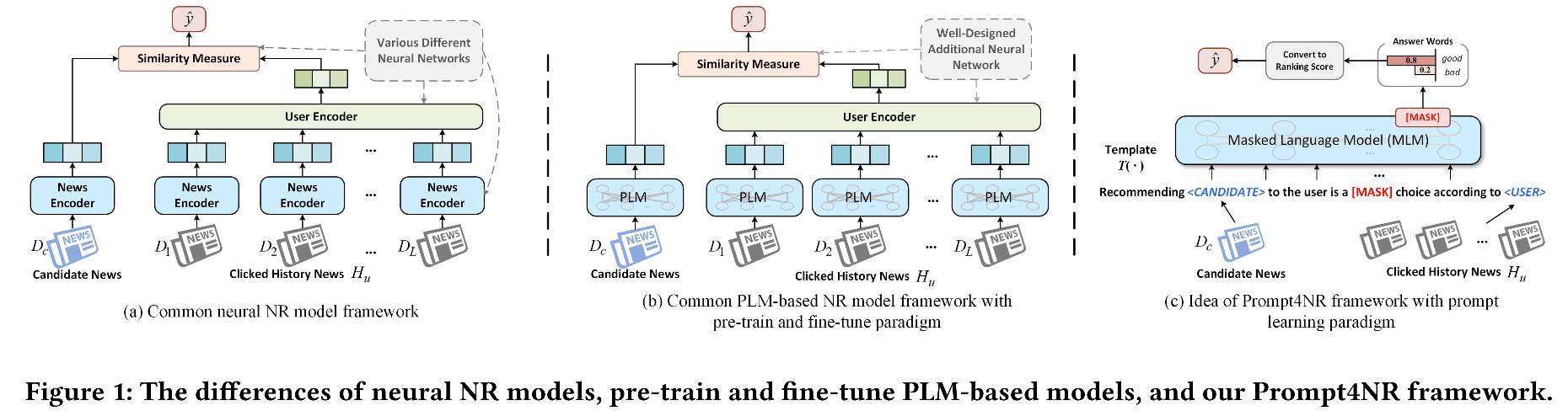
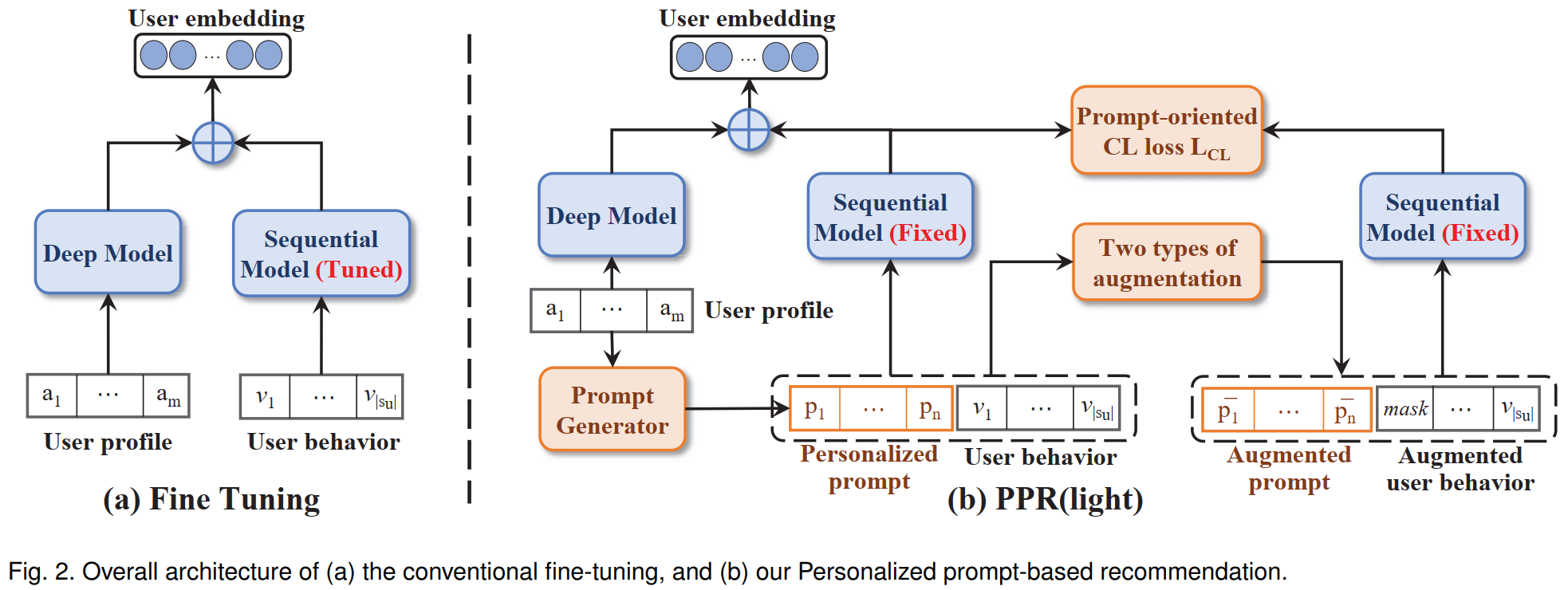
- Modelos de recomendação de notícias tradicionais: codificador de notícias, codificador de usuários, medida de similaridade recentemente, o trabalho introduziu modelos de idiomas pré-treinados para codificar o conteúdo de notícias no paradigma pré-trian-> tune tune para fazer recomendações de notícias. Insuficiente: como existem lacunas nas tarefas de recomendação de notícias e tarefas de modelo de idioma pré-treinado, o método atual não pode utilizar completamente o conhecimento de grandes modelos de idiomas.
- O aprendizado imediato alinha as tarefas a jusante com o pré -treino -> prompt -> prevê o paradigma e tem um desempenho excelentemente em muitas tarefas de PNL. Inspirado por isso, este artigo apresenta o modo de aprendizado imediato para recomendações de notícias.
Motivação
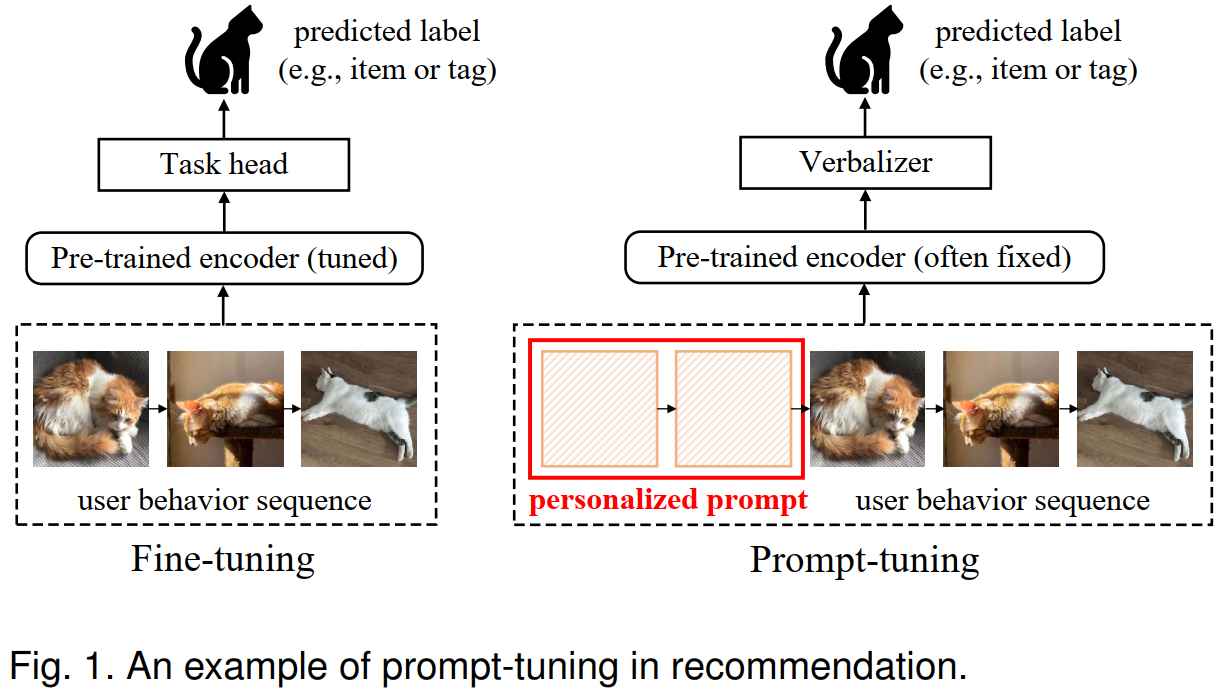
- Com a popularidade dos modelos de linguagem pré-treinados, dadas suas fortes reservas de conhecimento, entendimento semântico e recursos de processamento de idiomas, trabalhos recentes começaram a introduzir modelos de idiomas pré-treinados em recomendações de sequência. A pesquisa relacionada considera o comportamento histórico do usuário como tokens e serve como entrada para modelos de idiomas pré-treinados para aliviar o problema de lavar dados de comportamento do usuário em cenários reais.
- Este artigo apresenta modelos de linguagem pré-treinados para sequenciar tarefas de recomendação para lidar com problemas de poucos e tiro zero. Ele adota o paradigma imediato de aprendizado para alinhar as tarefas recomendadas com os modelos de idiomas pré-treinados para extrair conhecimento dos modelos de linguagem pré-treinados com mais eficiência.
Desafio
- Como introduzir o paradigma de ajuste do Propt no campo PNL na tarefa recomendada?
- Como projetar instruções personalizadas (orientadas ao usuário) para sistemas de recomendação.
Motivação
Motivação
Testing LLM for Rec
Motivação
Motivação