Prompt Learning
1.0.0
Beta hard prompt MLM参数更新
Motivation
- Da die Kennzeichnungskosten von Sprach, Domäne und Aufgabe extrem hoch sind, sind beschriftete Muster kostbar, wenn sie Sprachmodelle auf nachgeschaltete Aufgaben anwenden, und die wenigen Shots-Szenarien sind sehr häufig, was beobachtete Lernen einschränkt, was Wissenschaftler und Praktiker dazu angezogen hat, NLP-Aufgaben unter dem wenigen Shot-Umfeld auszuführen.
- Die Einführung von Text Erläuterung/Aufgabe Beschreibung in das vorgezogene Sprachmodell kann einige NLP-Aufgaben (Null-Shot-Szenario) auf eine unbeaufsichtigte Weise effektiv lösen.
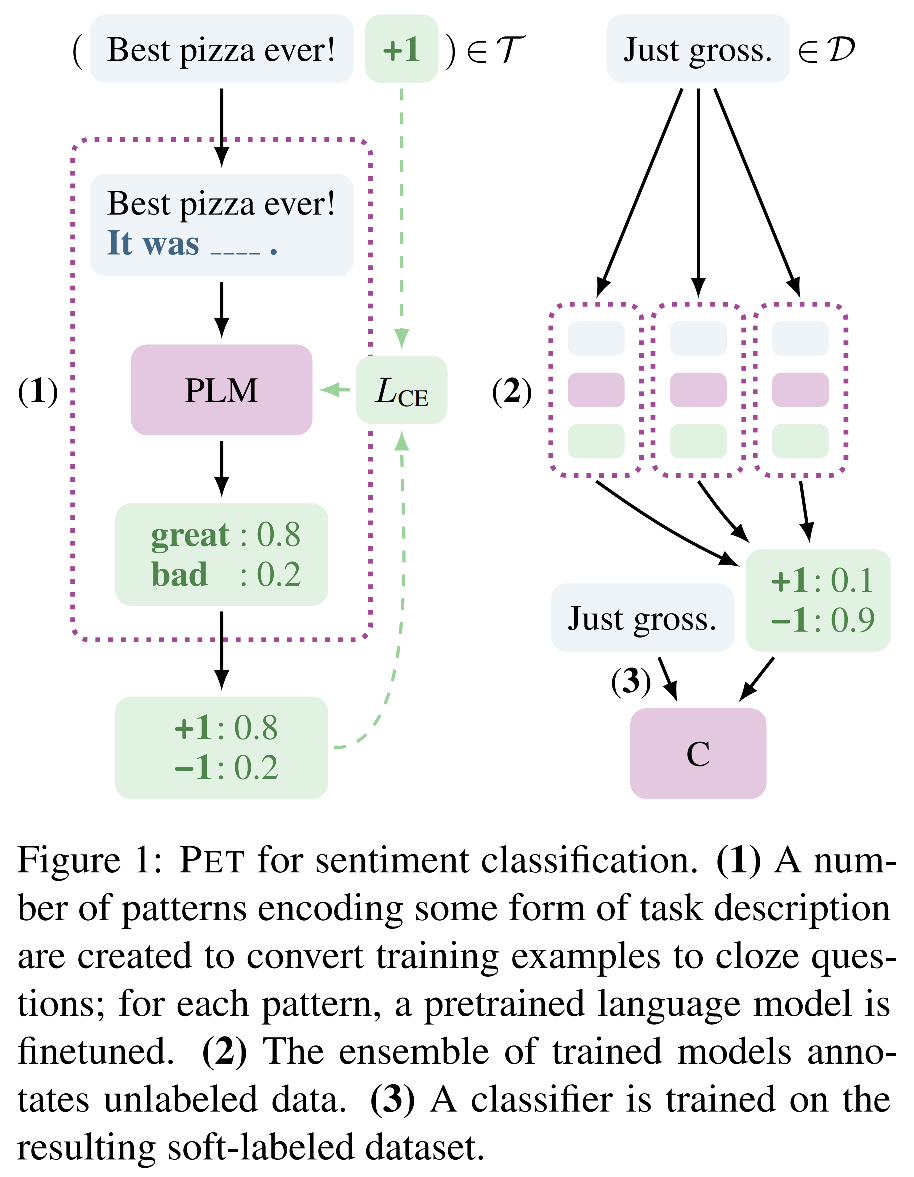
- In diesem Artikel werden alle Überlegungen vorgenommen, und schlägt vor, ein Muster-Exploiting-Training einzuführen, ein halbüberwachendes Trainingsstrategie-PET und seine verbesserte Version von IPET zu entwerfen und die Eingabebestellungen (Text) von NLP in eine Phrase im Thalle zuzuordnen.
hard prompt MLM参数更新
Motivation
- PET- und IPET -Frameworks können nur den Neigungen einer einzelnen [Maske] verarbeiten, während tatsächliche Aufgaben möglicherweise auf mehrere [Masken] stoßen.
- Dieser Artikel entspricht einer verbesserten Version von PET und IPET und erweitert Single [Mask] -Token auf K [Mask] -Token.
MLM -Parameter soft prompt MLM参数固定?
Motivation
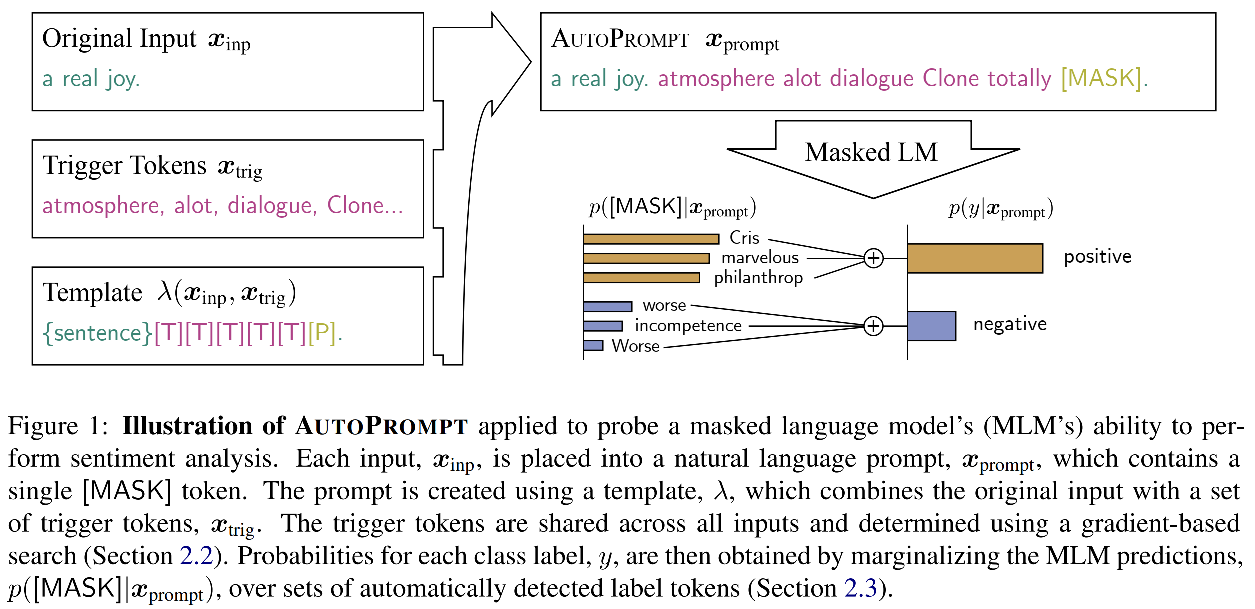
- Bei Verwendung von Sprachmodellen vor dem Training werden die nachgeschalteten Aufgaben als Füllungsfragen definiert (Task-> Sprachmodell, perfekt zum Sprachmodell). Verwenden Sie ProPT, um das Modell vor dem Training und die nachgeschalteten Aufgaben zu kommunizieren. Dies hilft, das in der Vorinstallationsphase gelernte Wissen zu bewerten, ohne eine große Anzahl neuer Parameter einzuführen.
- In der Vergangenheit ist die von Experten entworfene schnelle (harte Eingabeaufforderung) kostspielig und für viele Aufgaben nicht intuitiv. Darüber hinaus ist das Modell sehr empfindlich gegenüber den in der Eingabeaufforderung enthaltenen Kontextinformationen. Daher ist die künstlich gestaltete Eingabeaufforderung einfach zu einer Vorspannung.
- Zu diesem Zweck schlägt dieses Papier eine Möglichkeit vor, Propt und Etikett automatisch zu lernen.
soft prefix prompt tokens hard input sample prompt tokens MLM参数固定
Motivation
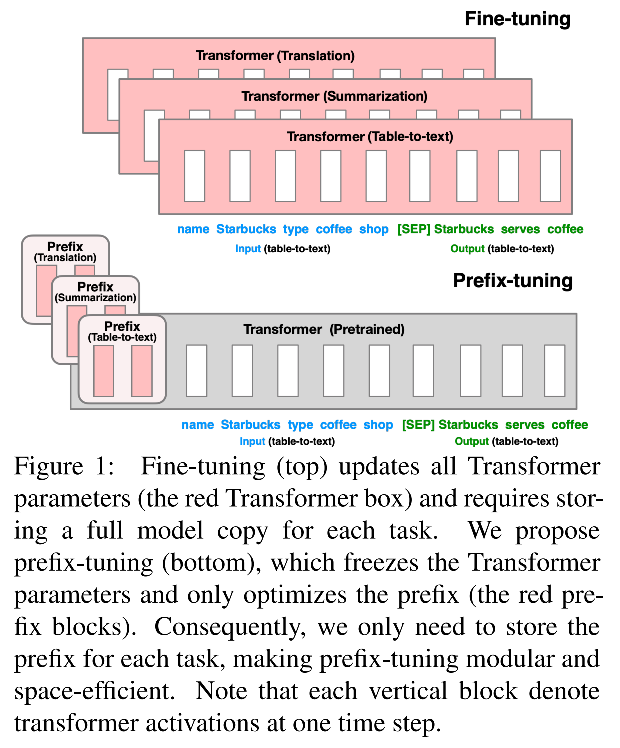
- Bei der Anwendung eines vorgeborenen Sprachmodells auf nachgeschaltete Aufgaben unter Verwendung des Vor-Train-Paradigmas ist es normalerweise erforderlich, die Parameter des vorgeborenen Sprachmodells zu aktualisieren. Bei verschiedenen Aufgaben ist es notwendig, das Modell einmal zu optimieren und seine Parameter zu speichern, und der Schulungs- und Speicheraufwand ist teuer.
- In diesem Artikel wird vorschlägt, das kontinuierliche Präfix -Eingabeaufforderung -Token (Präfix der Eingabebereich) für jede Aufgabe zu trainieren, und das Trendsprachmodell führt unterschiedliche Aufgaben aus.
soft prompt MLM
Motivation
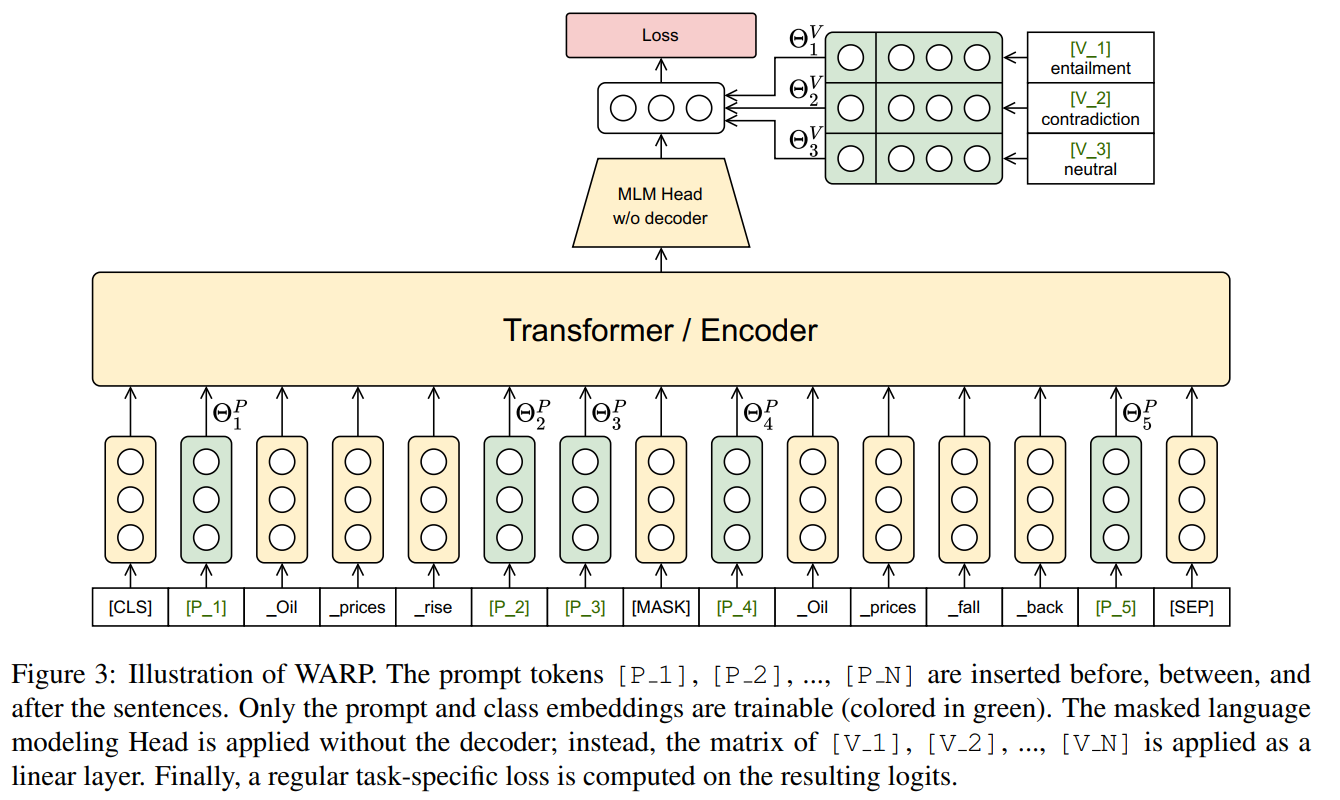
MLM -Parameter der soft prompt MLM参数固定,只更新插入的prompt和label
Motivation
Motivation
Motivation
soft prompt hard prompt hybrid prompt
Motivation
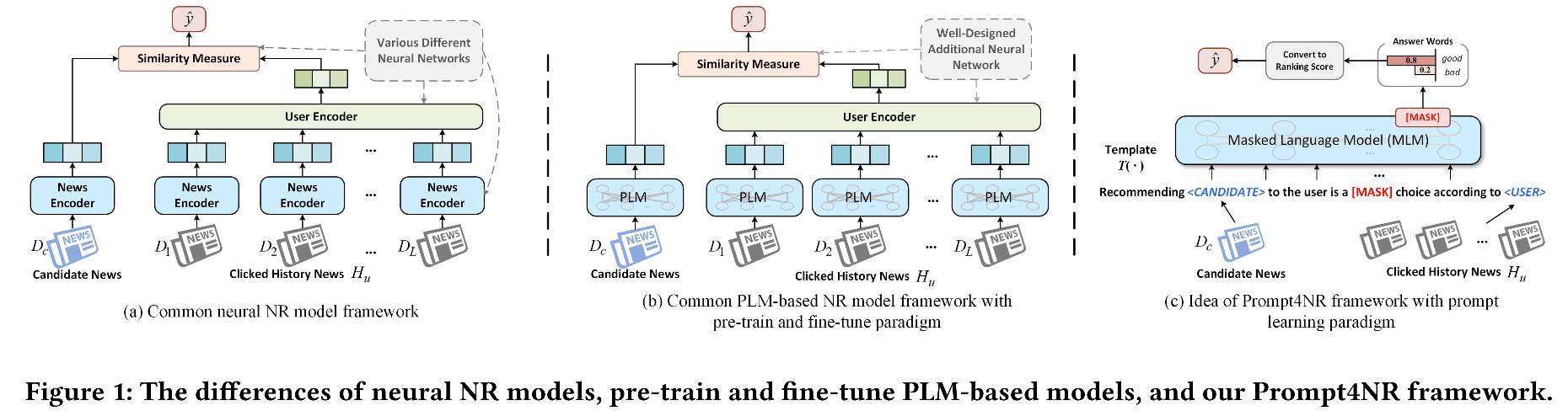
- Traditionelle Nachrichtenempfehlungsmodelle: News-Encoder, Benutzercodierer, Ähnlichkeitsmaß, die kürzlich vorhandene Sprachmodelle eingeführt haben, um Nachrichteninhalte im Pre-Trian-Paradigma zu codieren, um Nachrichtenempfehlungen abzugeben. Unzureichend: Da die Aufgaben der Nachrichtenempfehlung und die Aufgaben vor ausgebildetem Sprachmodell Lücken gibt, kann die aktuelle Methode das Wissen über Großsprachmodelle nicht vollständig nutzen.
- Das sofortige Lernen richtet nachgeschaltete Aufgaben mit Vor -Training -> Eingabeaufforderung -> Paradigma vorherzusagen und führt bei vielen NLP -Aufgaben hervorragend aus. Inspiriert von diesem Artikel führt dieser Artikel in den sofortigen Lernmodus in Nachrichtenempfehlungen ein.
Motivation
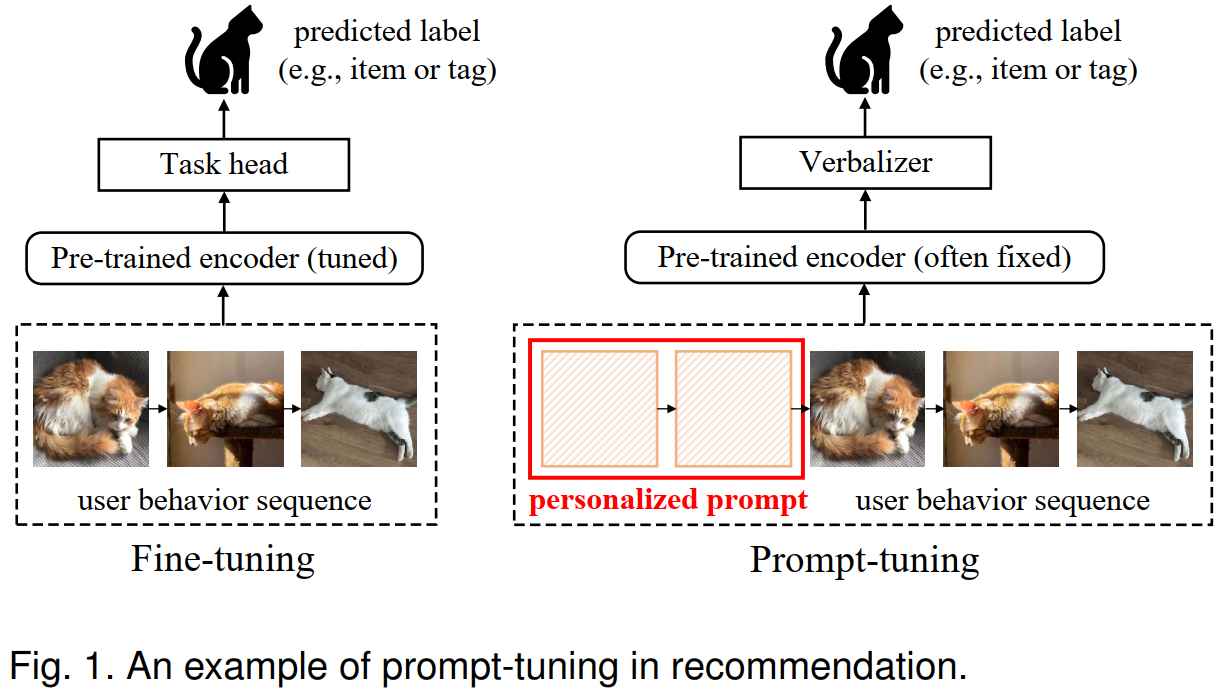
- Angesichts der Popularität von vorgeborenen Sprachmodellen, angesichts der starken Wissensreserven, des semantischen Verständnisses und der Funktionen der Sprachverarbeitung haben die jüngsten Arbeiten begonnen, vorgebrachte Sprachmodelle in Sequenzempfehlungen einzuführen. Verwandte Forschungsarbeiten betrachten das historische Verhalten des Benutzer als Token und dienen als Eingabe für vorgebreitete Sprachmodelle, um das Problem des Waschens von Benutzerverhaltensdaten in realen Szenarien zu lindern.
- In diesem Artikel werden vorgeborene Sprachmodelle in die Sequenzempfehlungsaufgaben eingeführt, um Probleme mit wenigen Schäden und Null-Shot-Problemen zu bewältigen. Es wird das schnelle Lernparadigma übernommen, um die empfohlenen Aufgaben mit den vorgeschriebenen Sprachmodellen auszurichten, um Wissen aus den vorgebliebenen Sprachmodellen effizienter zu extrahieren.
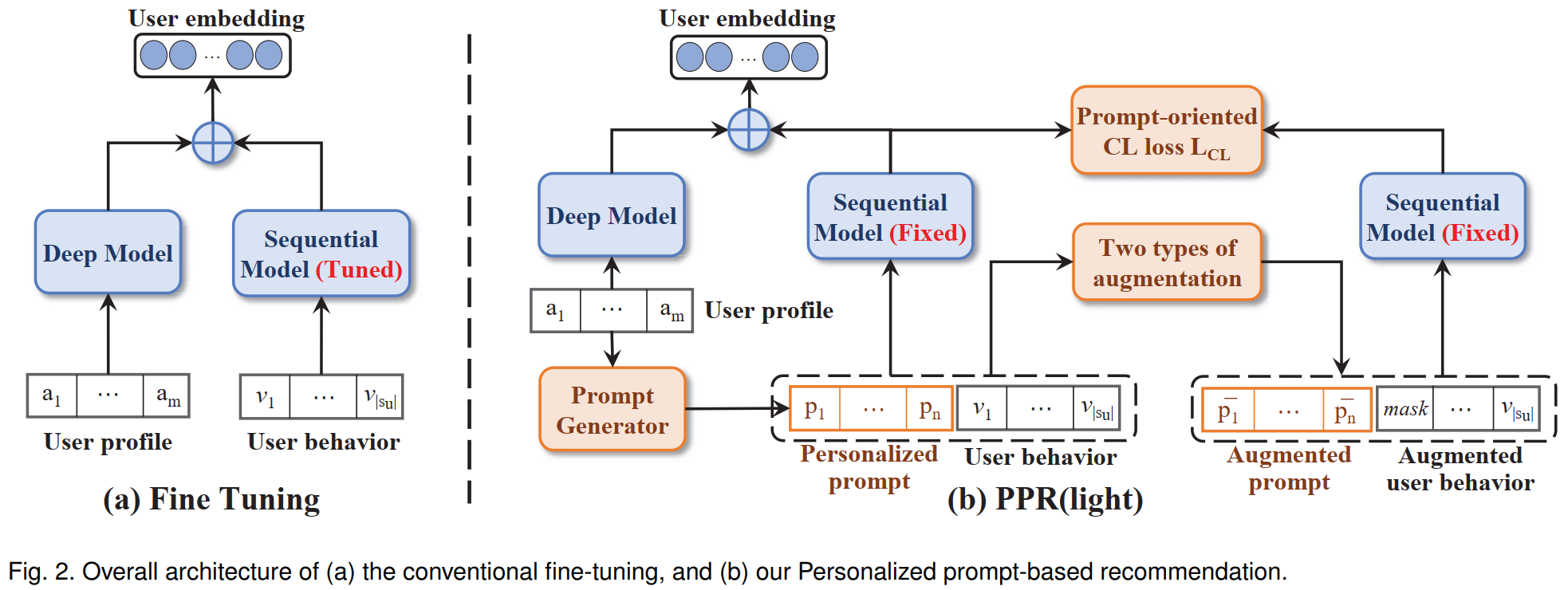
Herausforderung
- Wie stelle ich das ProPT -Tuning -Paradigma im NLP -Feld in die empfohlene Aufgabe ein?
- So entwerfen Sie personalisierte Eingabeaufforderungen (benutzerorientiert) für Empfehlungssysteme.
Motivation
Motivation
Testing LLM for Rec
Motivation
Motivation