autoregressive_inference
1.0.0
Este pacote contém a implementação do código-fonte do artigo "Descobrir pedidos autorregressivos não monotônicos com inferência variacional" (papel).
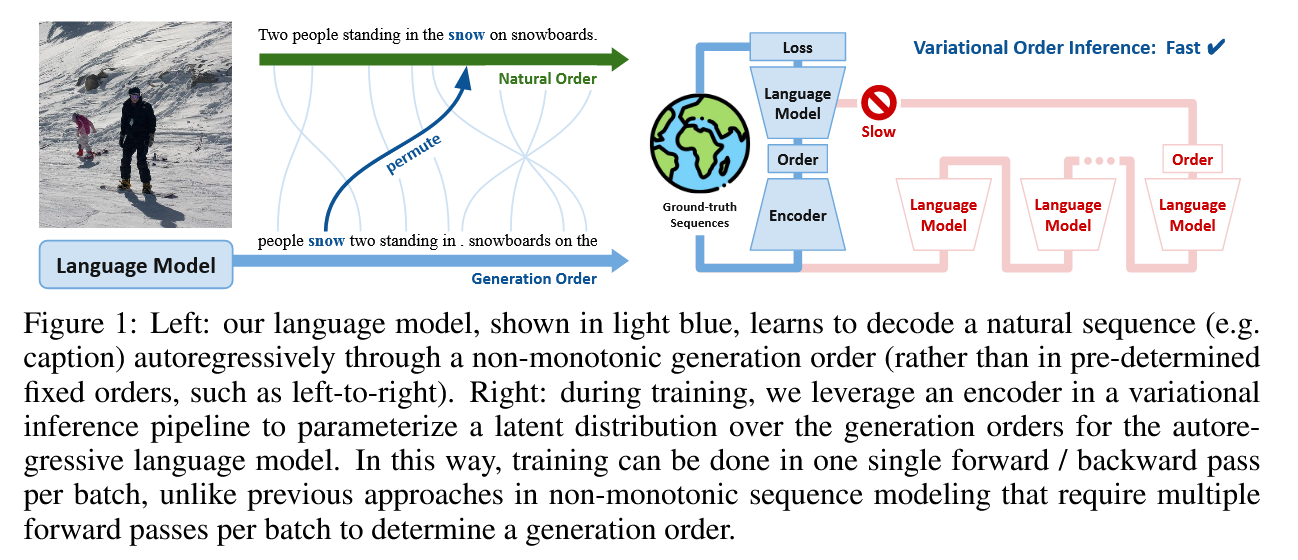
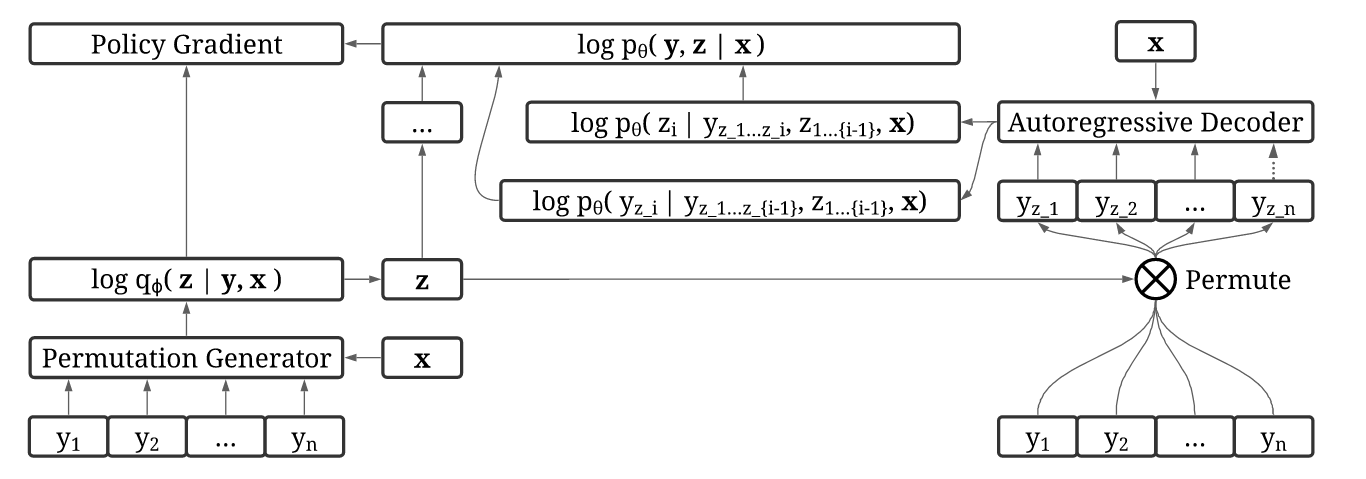
Inferir ordens de boa geração em sequências naturais é um desafio. Em nossa principal contribuição, propomos a inferência de ordem variacional (VOI), que pode ser treinada com eficiência para descobrir ordens de geração de sequência autoregressiva de maneira orientada a dados sem um anterior específico do domínio.
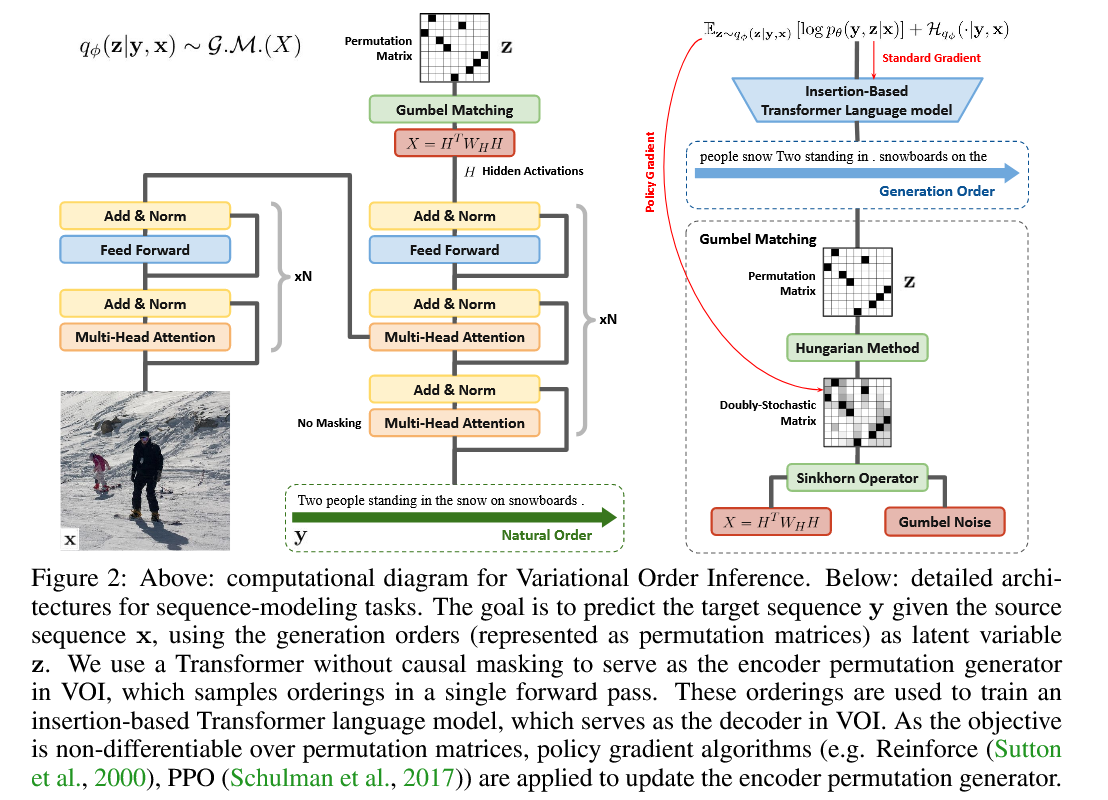
No VOI, o gerador de permutação do codificador gera ordens autoregressivas não monotônicas como a variável latente, e o modelo decodificador autorregressivo (idioma) maximiza a probabilidade articular de gerar a sequência alvo sob essas ordens não monotônicas. Nas tarefas de geração de texto condicional, o codificador é implementado como transformador com atenção não causal e o decodificador é implementado como transformador-indigo (Gu et al., 2019), que gera sequências de destino através da inserção.
Para instalar este pacote, primeiro faça o download do pacote do Github e instale -o usando o PIP. Para o CUDA 10.1 (conforme configurado em setup.py ), as versões do pacote são Tensorflow 2.3 e Pytorch 1.5, com suas versões correspondentes tensorflow_probability e torchvision . Para CUDA 11.0, pode ser necessário alterar as versões do pacote em setup.py para ser tensorflow==2.4 , torch==1.6 , tensorflow_probability==0.12.1 e torchvision==0.7.0 .
git clone https://github.com/xuanlinli17/autoregressive_inference
cd autoregressive_inference
pip install -e .Instale os pacotes auxiliares para tokenização de palavras e parte da marcação de fala. Digite as seguintes instruções no intérprete Python, onde você instalou nosso pacote.
import nltk
nltk . download ( 'punkt' )
nltk . download ( 'brown' )
nltk . download ( 'universal_tagset' ) Instale nlg-eval que contém várias métricas úteis para avaliar a legenda da imagem. As tarefas que não sejam legendas são avaliadas através do pacote vizseq que já instalamos no setup.py .
pip install git+https://github.com/Maluuba/nlg-eval.git@master
nlg-eval --setup CLONE wmt16-scripts para o pré-processamento de tradução da máquina.
git clone https://github.com/rsennrich/wmt16-scripts
Durante o treinamento, um processo de inferência de ordem é obter matrizes de permutação de matrizes duplamente estocásticas. Isso é realizado através do algoritmo húngaro. Como tf.py_function permite apenas uma GPU executar a função a qualquer momento, o treinamento multi-GPU é muito lento se usarmos scipy.optimize.linear_sum_assignment (que requer envolvê-lo com tf.py_function para chamar). Portanto, usamos um script húngaro pré-escrito e o compilamos através do G ++ na biblioteca dinâmica. Durante o tempo de execução, podemos importar a biblioteca dinâmica usando a API do TensorFlow. Isso leva a um treinamento distribuído muito mais rápido.
git clone https://github.com/brandontrabucco/tensorflow-hungarian
cd tensorflow-hungarian
make hungarian_op Se você encontrar fatal error: third_party/gpus/cuda/include/cuda_fp16.h: No such file or directory , isso pode ser resolvido via link. O OP gerado pode ser encontrado em tensorflow-hungarian/tensorflow_hungarian/python/ops/_hungarian_ops.so
Como alternativa, também poderíamos gerar o OP a partir do repo munkres-tensorflow .
git clone https://github.com/mbaradad/munkres-tensorflow
TF_CFLAGS=( $( python -c ' import tensorflow as tf; print(" ".join(tf.sysconfig.get_compile_flags())) ' ) )
TF_LFLAGS=( $( python -c ' import tensorflow as tf; print(" ".join(tf.sysconfig.get_link_flags())) ' ) )
g++ -std=c++11 -shared munkres-tensorflow/hungarian.cc -o hungarian.so -fPIC ${TF_CFLAGS[@]} ${TF_LFLAGS[@]} -O2 No entanto, essa função requer que todas as entradas em uma matriz sejam diferentes (caso contrário, alguns comportamentos estranhos ocorrerão), por isso também precisamos descomentar a linha sample_permu = sample_permu * 1000 + tf.random.normal(tf.shape(sample_permu)) * 1e-7 em voi/nn/layers/permutation_sinkhorn.py
Nesta seção, levaremos você a criar um conjunto de dados de treinamento, usando o Coco 2017 como exemplo. Na primeira etapa, faça o download do Coco 2017 aqui. Coloque as anotações .json extraídas em ~/annotations e as imagens em ~/train2017 e ~/val2017 para o conjunto de treinamento e validação, respectivamente.
Crie uma parte do tagger de fala primeiro. Essas informações são usadas para visualizar as ordens de geração das legendas aprendidas pelo nosso modelo e não são usadas durante o treinamento.
cd {this_repo}
python scripts/data/create_tagger.py --out_tagger_file tagger.pkl Extraia o Coco 2017 em um formato compatível com o nosso pacote. Existem vários argumentos que você pode especificar para controlar como o conjunto de dados é processado. Você pode deixar todos os argumentos como padrão, exceto out_caption_folder e annotations_file .
python scripts/data/extract_coco.py --out_caption_folder ~ /captions_train2017 --annotations_file ~ /annotations/captions_train2017.json
python scripts/data/extract_coco.py --out_caption_folder ~ /captions_val2017 --annotations_file ~ /annotations/captions_val2017.json Processe as legendas do Coco 2017 e extraem recursos inteiros sobre os quais treinar um modelo não seqüencial. Existem novamente vários argumentos que você pode especificar para controlar como as legendas são processadas. Você pode deixar todos os argumentos como padrão, exceto out_feature_folder e in_folder , que dependem de onde você extraiu o conjunto de dados Coco na etapa anterior. Observe que se vocab_file não existir antes, ele será gerado automaticamente. Como fornecemos o train2017_vocab.txt que usamos para treinar nosso modelo, esse arquivo de vocabulário será carregado diretamente para criar representações inteiras de tokens.
python scripts/data/process_captions.py --out_feature_folder ~ /captions_train2017_features --in_folder ~ /captions_train2017
--tagger_file tagger.pkl --vocab_file train2017_vocab.txt --min_word_frequency 5 --max_length 100
python scripts/data/process_captions.py --out_feature_folder ~ /captions_val2017_features --in_folder ~ /captions_val2017
--tagger_file tagger.pkl --vocab_file train2017_vocab.txt --max_length 100 Processar imagens do conjunto de dados Coco 2017 e extrair recursos usando um backbone de FPN RCNN mais rápido do Pytorch. Observe que este script distribuirá a inferência em todas as GPUs visíveis no seu sistema. Existem vários argumentos que você pode especificar, que você pode deixar como padrão, exceto out_feature_folder e in_folder , que dependem de onde você extraiu o conjunto de dados Coco.
python scripts/data/process_images.py --out_feature_folder ~ /train2017_features --in_folder ~ /train2017 --batch_size 4
python scripts/data/process_images.py --out_feature_folder ~ /val2017_features --in_folder ~ /val2017 --batch_size 4 Finalmente, converta os recursos processados em um formato TFRecord para treinamento eficiente. Registre onde você extraiu o conjunto de dados Coco nas etapas anteriores e especifique out_tfrecord_folder , caption_folder e image_folder no mínimo.
python scripts/data/create_tfrecords_captioning.py --out_tfrecord_folder ~ /train2017_tfrecords
--caption_folder ~ /captions_train2017_features --image_folder ~ /train2017_features --samples_per_shard 4096
python scripts/data/create_tfrecords_captioning.py --out_tfrecord_folder ~ /val2017_tfrecords
--caption_folder ~ /captions_val2017_features --image_folder ~ /val2017_features --samples_per_shard 4096 Por conveniência, executamos o script do NL2Code para extrair o conjunto de dados limpos da unidade e colocá -los em django_data . O arquivo de vocabulário djangovocab.txt também está nesse diretório. Como alternativa, você pode baixar dados brutos do ASE15-django e executar python scripts/data/extract_django.py --data_dir {path to all.anno and all.code)
Em seguida, processe o conjunto de dados do Django no formato Tfrecord para treinamento eficiente.
cd {this_repo}
CUDA_VISIBLE_DEVICES=0 python scripts/data/process_django.py --data_folder ./django_data
--vocab_file ./django_data/djangovocab.txt --dataset_type train/dev/test
--out_feature_folder ./django_data
CUDA_VISIBLE_DEVICES=0 python scripts/data/create_tfrecords_django.py --out_tfrecord_folder ./django_data
--dataset_type train/dev/test --feature_folder ./django_dataPrimeiro, extraia o conjunto de dados e aprenda a codificação de pares de bytes.
cd {this_repo}
CUDA_VISIBLE_DEVICES=0 python scripts/data/extract_gigaword.py --data_dir {dataroot}
cd {dataroot}/gigaword
subword-nmt learn-joint-bpe-and-vocab --input src_raw_train.txt tgt_raw_train.txt -s 32000 -o joint_bpe.code --write-vocabulary src_vocab.txt tgt_vocab.txt
subword-nmt apply-bpe -c joint_bpe.code --vocabulary src_vocab.txt --vocabulary-threshold 50 < src_raw_train.txt > src_train.BPE.txt
subword-nmt apply-bpe -c joint_bpe.code --vocabulary src_vocab.txt --vocabulary-threshold 50 < src_raw_validation.txt > src_validation.BPE.txt
subword-nmt apply-bpe -c joint_bpe.code --vocabulary src_vocab.txt --vocabulary-threshold 50 < src_raw_test.txt > src_test.BPE.txt
subword-nmt apply-bpe -c joint_bpe.code --vocabulary tgt_vocab.txt --vocabulary-threshold 50 < tgt_raw_train.txt > tgt_train.BPE.txt
subword-nmt apply-bpe -c joint_bpe.code --vocabulary tgt_vocab.txt --vocabulary-threshold 50 < tgt_raw_validation.txt > tgt_validation.BPE.txt
subword-nmt apply-bpe -c joint_bpe.code --vocabulary tgt_vocab.txt --vocabulary-threshold 50 < tgt_raw_test.txt > tgt_test.BPE.txt Em seguida, gere o arquivo de vocabulário e use este arquivo de vocabulário para converter tokens em números inteiros e armazenar em um arquivo de recurso. Como alternativa, você pode usar o gigaword_vocab.txt fornecido em nosso repositório, que usamos para treinar nosso modelo. Para fazer isso, defina o seguinte argumento --vocab_file como {this_repo}/gigaword_vocab.txt .
cd {this_repo}
CUDA_VISIBLE_DEVICES=0 python scripts/data/process_gigaword.py --out_feature_folder {dataroot}/gigaword
--data_folder {dataroot}/gigaword --vocab_file {dataroot}/gigaword/gigaword_vocab.txt (or {this_repo}/gigaword_vocab.txt)
--dataset_type train/validation/testPor fim, gerar os arquivos TFRCORDS TRIN/VALIDAÇÃO/TESTE.
CUDA_VISIBLE_DEVICES=0 python scripts/data/create_tfrecords_gigaword.py --out_tfrecord_folder {dataroot}/gigaword
--feature_folder {dataroot}/gigaword --samples_per_shard 4096 --dataset_type train/validation/testAqui, usamos o WMT16 RO-EN como exemplo.
Primeiro extraia o conjunto de dados e aprenda a codificação de byte par.
cd {this_repo}
CUDA_VISIBLE_DEVICES=0 python scripts/data/extract_wmt.py --language_pair 16 ro en --data_dir {dataroot}
cd {dataroot}/wmt16_translate/ro-en
subword-nmt learn-joint-bpe-and-vocab --input src_raw_train.txt tgt_raw_train.txt -s 32000 -o joint_bpe.code --write-vocabulary src_vocab.txt tgt_vocab.txt
subword-nmt apply-bpe -c joint_bpe.code --vocabulary src_vocab.txt --vocabulary-threshold 50 < src_raw_train.txt > src_train.BPE.txt
subword-nmt apply-bpe -c joint_bpe.code --vocabulary src_vocab.txt --vocabulary-threshold 50 < src_raw_validation.txt > src_validation.BPE.txt
subword-nmt apply-bpe -c joint_bpe.code --vocabulary src_vocab.txt --vocabulary-threshold 50 < src_raw_test.txt > src_test.BPE.txt
subword-nmt apply-bpe -c joint_bpe.code --vocabulary tgt_vocab.txt --vocabulary-threshold 50 < tgt_raw_train.txt > tgt_train.BPE.txt
subword-nmt apply-bpe -c joint_bpe.code --vocabulary tgt_vocab.txt --vocabulary-threshold 50 < tgt_raw_validation.txt > tgt_validation.BPE.txt
subword-nmt apply-bpe -c joint_bpe.code --vocabulary tgt_vocab.txt --vocabulary-threshold 50 < tgt_raw_test.txt > tgt_test.BPE.txtExtraia o corpus com truecase para treinar o Truecaser, que é usado para avaliação.
git clone https://github.com/moses-smt/mosesdecoder
cd {this_repo}
CUDA_VISIBLE_DEVICES=0 python scripts/data/extract_wmt.py --language_pair 16 ro en --data_dir {dataroot} --truecase
{path_to_mosesdecoder}/scripts/recaser/train-truecaser.perl -corpus {dataroot}/wmt16_translate/ro-en/src_truecase_train.txt -model {dataroot}/wmt16_translate/ro-en/truecase-model.ro
{path_to_mosesdecoder}/scripts/recaser/train-truecaser.perl -corpus {dataroot}/wmt16_translate/ro-en/tgt_truecase_train.txt -model {dataroot}/wmt16_translate/ro-en/truecase-model.enRemova os diacríticos do romeno:
git clone https://github.com/rsennrich/wmt16-scripts
cd {dataroot}/wmt16_translate/ro-en/
python {path_to_wmt16-scripts}/preprocess/remove-diacritics.py < src_train.BPE.txt > src_train.BPE.txt
python {path_to_wmt16-scripts}/preprocess/remove-diacritics.py < src_validation.BPE.txt > src_validation.BPE.txt
python {path_to_wmt16-scripts}/preprocess/remove-diacritics.py < src_test.BPE.txt > src_test.BPE.txt------------Observação-------------
Na prática, o treinamento com o conjunto de dados de destilação no nível da sequência (link) gerado usando o modelo L2R com tamanho 5 leva a cerca de 2 melhorias bleu no WMT16 RO-en, intuitivamente porque as seqüências de destino nesse novo conjunto de dados são mais consistentes. Lançamos o conjunto de dados deste destilado aqui. Para usar esse conjunto de dados, coloque src_distillation.BPE.txt e tgt_distillation.BPE.txt em {dataroot}/wmt16_translate/ro-en/ . O treinamento neste conjunto de dados destilado obtém observações de pedidos muito semelhantes (ou seja, o modelo gera todos os tokens descritivos antes de gerar os tokens auxiliares) em comparação com o treinamento no conjunto de dados original.
-------------------------------
Gere o arquivo de vocable (vocabulário conjunto para os idiomas de origem e de destino) e use esse arquivo de vocabulário para converter tokens em números inteiros e armazenar em um arquivo de recurso. Como esquecemos de remover os diacríticos durante nossos experimentos iniciais e anexamos todos os vocables ausentes no corpus remunerado por diacríticos depois, o arquivo de vocabulário que usamos para treinar nosso modelo é ligeiramente diferente do que é gerado através dos scripts abaixo, por isso carregamos o arquivo de vocable que usamos para treinar nosso modelo como ro_en_vocab.txt . Para usar este arquivo de vocabulário, defina o seguinte argumento --vocab_file como {this_repo}/ro_en_vocab.txt
cd {this_repo}
CUDA_VISIBLE_DEVICES=0 python scripts/data/process_wmt.py --out_feature_folder {dataroot}/wmt16_translate/ro-en
--data_folder {dataroot}/wmt16_translate/ro-en --vocab_file {dataroot}/wmt16_translate/ro_en_vocab.txt (or {this_repo}/ro_en_vocab.txt)
--dataset_type distillation/train/validation/test
Finalmente, gerar os arquivos TfRecords de destilação/trem/validação/teste.
CUDA_VISIBLE_DEVICES=0 python scripts/data/create_tfrecords_wmt.py --out_tfrecord_folder {dataroot}/wmt16_translate/ro-en
--feature_folder {dataroot}/wmt16_translate/ro-en --samples_per_shard 4096 --dataset_type distillation/train/validation/test
Consulte Training_scripts.md para obter detalhes sobre o treinamento de um modelo.
Consulte Evaluation_Visualization_scripts.MD para obter detalhes sobre a validação / teste de um modelo, além de visualizar as ordens de generalização de um modelo.
Fornecemos modelos pré -ridicularizados para cada tarefa aqui. Você pode fazer um diretório ckpt_pretrain sob este repositório e baixá -lo sob este diretório.
Para avaliar os modelos pré -criados e visualizar suas ordens de generalização, consulte Eval_Visualize_Pretraned_models.md para obter detalhes.
@inproceedings{li2021autoregressiveinference,
title={Discovering Non-monotonic Autoregressive Orderings with Variational Inference},
author={Li, Xuanlin and Trabucco, Brandon and Park, Dong Huk and Luo, Michael and Shen, Sheng and Darrell, Trevor and Gao, Yang},
booktitle={International Conference on Learning Representations},
year={2021},
url={https://openreview.net/forum?id=jP1vTH3inC}
}
Dblp:
@inproceedings{DBLP:conf/iclr/LiTPLSD021,
author = {Xuanlin Li and
Brandon Trabucco and
Dong Huk Park and
Michael Luo and
Sheng Shen and
Trevor Darrell and
Yang Gao},
title = {Discovering Non-monotonic Autoregressive Orderings with Variational
Inference},
booktitle = {9th International Conference on Learning Representations, {ICLR} 2021,
Virtual Event, Austria, May 3-7, 2021},
publisher = {OpenReview.net},
year = {2021},
url = {https://openreview.net/forum?id=jP1vTH3inC},
biburl = {https://dblp.org/rec/conf/iclr/LiTPLSD021.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}


