autoregressive_inference
1.0.0
Dieses Paket enthält die Quellcode-Implementierung des Papiers "Entdeckung nicht monotonischer autoregressiver Orderungen mit Variationsinferenz" (Papier).
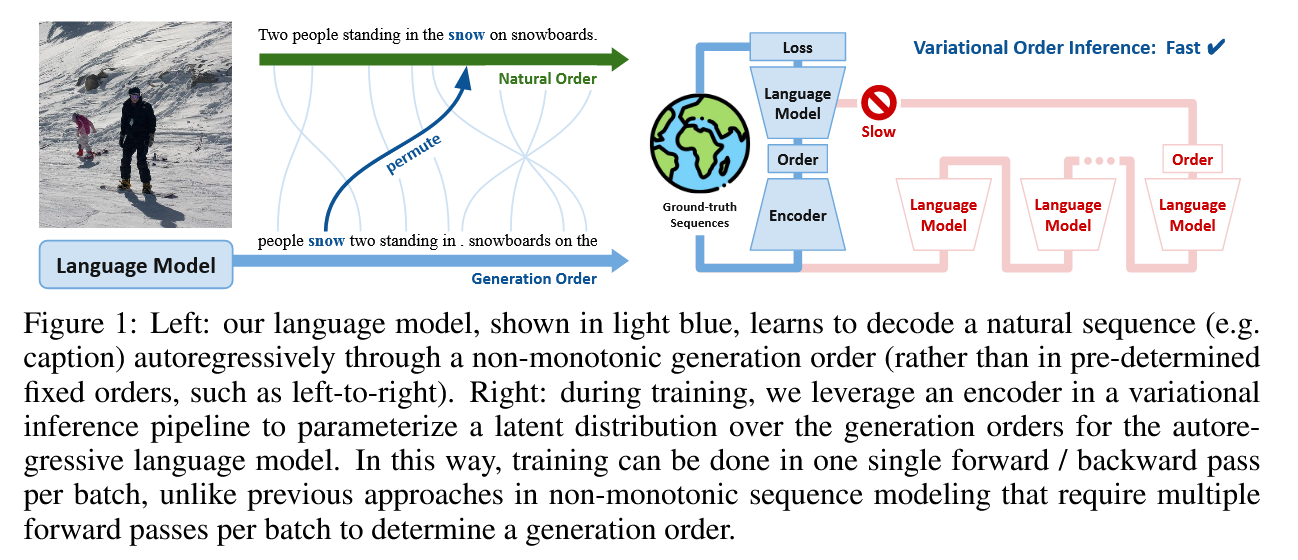
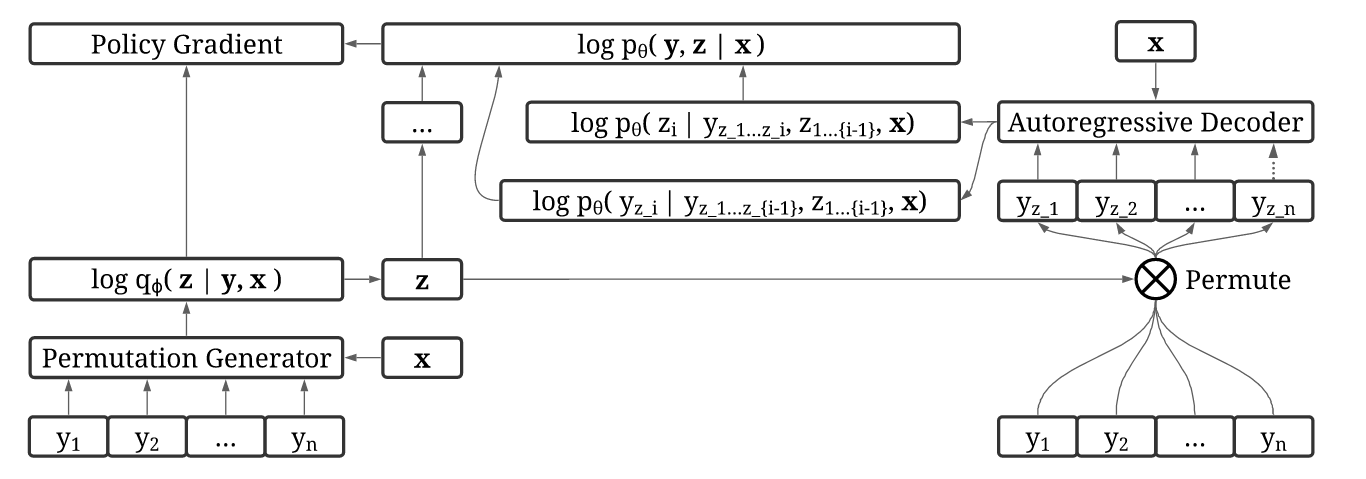
Es ist eine Herausforderung, gute Generationenaufträge in natürlichen Sequenzen zu schließen. In unserem Hauptbeitrag schlagen wir Variationsauftragsinferenz (VOI) vor, die effizient geschult werden können, um autoregressive Reihenfolge der Sequenzgenerierung auf datengetriebene Weise ohne domänenspezifische Vorgänger zu entdecken.
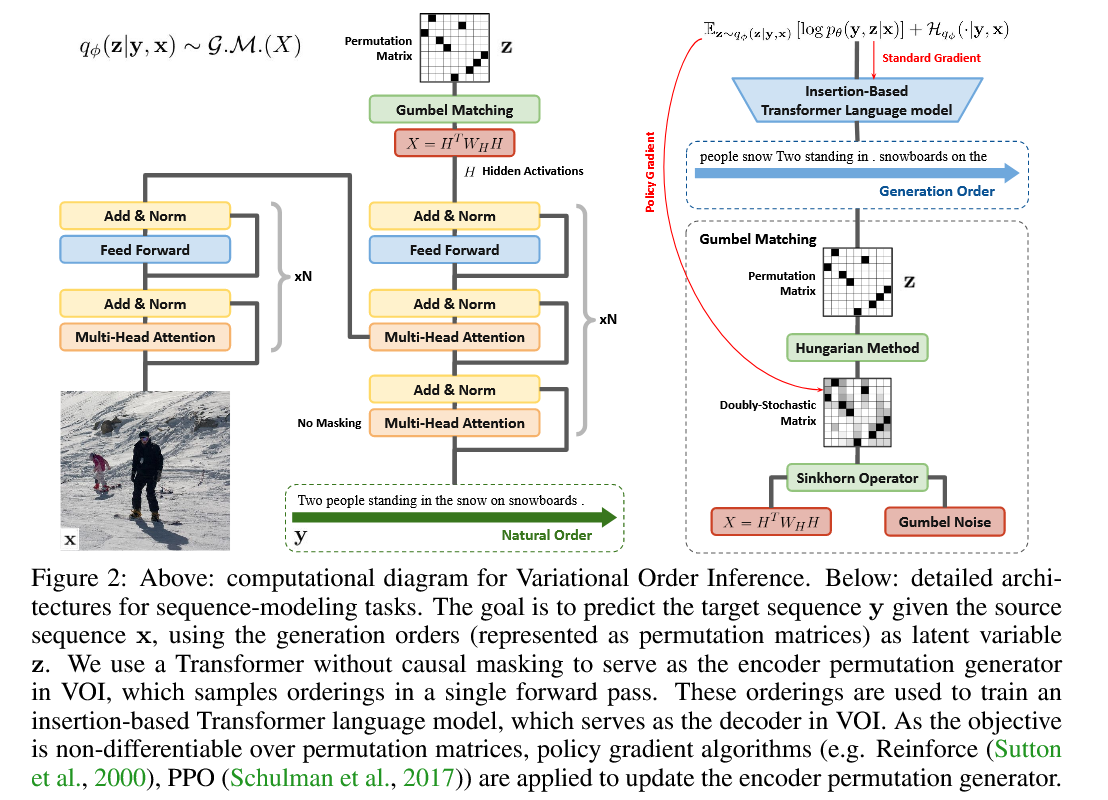
In VOI erzeugt der Encoder-Permutationsgenerator nicht-monotonische autoregressive Aufträge als latente Variable, und das autoregressive Decoder-Modell (Sprach) maximiert die gemeinsame Wahrscheinlichkeit, die Zielsequenz unter diesen nicht-monotonischen Ordnungen zu generieren. Bei Aufgaben der bedingten Textgenerierung wird der Encoder als Transformator mit nicht kausaler Aufmerksamkeit implementiert, und der Decoder wird als Transformator-Indigo (Gu et al., 2019) implementiert, was durch Insertion Zielsequenzen erzeugt.
Um dieses Paket zu installieren, laden Sie zuerst das Paket von GitHub herunter und installieren Sie es dann mit PIP. Für CUDA 10.1 (wie in setup.py konfiguriert) sind die Paketversionen TensorFlow 2.3 und Pytorch 1.5 mit ihren entsprechenden tensorflow_probability und torchvision -Versionen. Für CUDA 11.0 müssen Sie torch==1.6 tensorflow==2.4 Paketversionen tensorflow_probability==0.12.1 setup.py torchvision==0.7.0 .
git clone https://github.com/xuanlinli17/autoregressive_inference
cd autoregressive_inference
pip install -e .Installieren Sie Helferpakete für Word -Tokenisierung und einen Teil des Sprach -Tagging. Geben Sie die folgenden Aussagen in den Python -Interpreter ein, in dem Sie unser Paket installiert haben.
import nltk
nltk . download ( 'punkt' )
nltk . download ( 'brown' )
nltk . download ( 'universal_tagset' ) Installieren Sie nlg-eval , das mehrere hilfreiche Metriken zur Bewertung von Bildunterschriften enthält. Andere Aufgaben als die Bildunterschrift werden über das vizseq -Paket bewertet, das wir bereits über setup.py installiert haben.
pip install git+https://github.com/Maluuba/nlg-eval.git@master
nlg-eval --setup Klon wmt16-scripts zur Vorverarbeitung maschineller Übersetzung.
git clone https://github.com/rsennrich/wmt16-scripts
Während des Trainings besteht ein Prozess der Auftragsaussetzung darin, Permutationsmatrizen aus doppelt stochastischen Matrizen zu erhalten. Dies wird durch den ungarischen Algorithmus erreicht. Da tf.py_function nur eine GPU jederzeit ausführen kann, ist das Multi-GPU tf.py_function Training sehr langsam, wenn wir scipy.optimize.linear_sum_assignment verwenden Daher verwenden wir ein vorgeschriebenes ungarisches Skript und kompilieren es durch G ++ in dynamische Bibliothek. Während der Laufzeit können wir die dynamische Bibliothek mithilfe der TensorFlow -API importieren. Dies führt zu viel schneller verteilter Schulung.
git clone https://github.com/brandontrabucco/tensorflow-hungarian
cd tensorflow-hungarian
make hungarian_op Wenn Sie auf fatal error: third_party/gpus/cuda/include/cuda_fp16.h: No such file or directory , kann dies über Link aufgelöst werden. Das erzeugte OP war in tensorflow-hungarian/tensorflow_hungarian/python/ops/_hungarian_ops.so zu finden
Alternativ könnten wir auch das OP aus dem Repo munkres-tensorflow erzeugen.
git clone https://github.com/mbaradad/munkres-tensorflow
TF_CFLAGS=( $( python -c ' import tensorflow as tf; print(" ".join(tf.sysconfig.get_compile_flags())) ' ) )
TF_LFLAGS=( $( python -c ' import tensorflow as tf; print(" ".join(tf.sysconfig.get_link_flags())) ' ) )
g++ -std=c++11 -shared munkres-tensorflow/hungarian.cc -o hungarian.so -fPIC ${TF_CFLAGS[@]} ${TF_LFLAGS[@]} -O2 Diese Funktion erfordert jedoch, dass alle Einträge in einer Matrix unterschiedlich sind (ansonsten treten einige seltsame Verhaltensweisen auf), daher müssen wir auch die Zeilenmodelle sample_permu = sample_permu * 1000 + tf.random.normal(tf.shape(sample_permu)) * 1e-7 in voi/nn/layers/permutation_sinkhorn.py auftreten.
In diesem Abschnitt führen wir Sie durch das Erstellen eines Trainingsdatensatzes mit Coco 2017 als Beispiel. Laden Sie im ersten Schritt Coco 2017 hier herunter. Platzieren Sie die extrahierten .json -Anmerkungen in ~/annotations und die Bilder unter ~/train2017 und ~/val2017 für den Trainings- bzw. Validierungssatz.
Erstellen Sie zuerst einen Teil des Sprach -Taggers. Diese Informationen werden verwendet, um die Erzeugungsaufträge von Bildunterschriften zu visualisieren, die unser Modell erlernt haben, und werden während des Trainings nicht verwendet.
cd {this_repo}
python scripts/data/create_tagger.py --out_tagger_file tagger.pkl Extrahieren Sie Coco 2017 in ein Format, das mit unserem Paket kompatibel ist. Es gibt mehrere Argumente, die Sie angeben können, um zu steuern, wie der Datensatz verarbeitet wird. Sie können alle Argumente als standardmäßig außer out_caption_folder und annotations_file hinterlassen.
python scripts/data/extract_coco.py --out_caption_folder ~ /captions_train2017 --annotations_file ~ /annotations/captions_train2017.json
python scripts/data/extract_coco.py --out_caption_folder ~ /captions_val2017 --annotations_file ~ /annotations/captions_val2017.json Verarbeiten Sie die COCO 2017 -Bildunterschriften und extrahieren Sie ganzzahlige Merkmale, um ein nicht sequentielles Modell zu trainieren. Es gibt wieder mehrere Argumente, die Sie angeben können, um zu steuern, wie die Bildunterschriften verarbeitet werden. Sie können alle Argumente als standardmäßig außer out_feature_folder und in_folder hinterlassen, die davon abhängen, wo Sie den Coco -Datensatz im vorherigen Schritt extrahiert haben. Beachten Sie, dass vocab_file vorher nicht vorhanden ist, es automatisch generiert wird. Da wir den train2017_vocab.txt bereitgestellt haben, um unser Modell zu trainieren, wird diese Vokabatei direkt geladen, um ganzzahlige Darstellungen von Token zu erstellen.
python scripts/data/process_captions.py --out_feature_folder ~ /captions_train2017_features --in_folder ~ /captions_train2017
--tagger_file tagger.pkl --vocab_file train2017_vocab.txt --min_word_frequency 5 --max_length 100
python scripts/data/process_captions.py --out_feature_folder ~ /captions_val2017_features --in_folder ~ /captions_val2017
--tagger_file tagger.pkl --vocab_file train2017_vocab.txt --max_length 100 Verarbeiten Sie Bilder aus dem CoCO 2017 -Datensatz und extrahieren Sie Funktionen mit einem schnelleren RCNN -FPN -Rückgrat aus dem Pytorch -Checkpoint. Beachten Sie, dass dieses Skript die Schlussfolgerung über alle sichtbaren GPUs in Ihrem System verteilt. out_feature_folder in_folder mehrere Argumente, die Sie angeben können.
python scripts/data/process_images.py --out_feature_folder ~ /train2017_features --in_folder ~ /train2017 --batch_size 4
python scripts/data/process_images.py --out_feature_folder ~ /val2017_features --in_folder ~ /val2017 --batch_size 4 Konvertieren Sie schließlich die verarbeiteten Merkmale in ein TFFRECORD -Format für ein effizientes Training. Notieren Sie, wo Sie den CoCo -Datensatz in den vorherigen Schritten extrahiert haben, und geben Sie mindestens out_tfrecord_folder , caption_folder und image_folder an.
python scripts/data/create_tfrecords_captioning.py --out_tfrecord_folder ~ /train2017_tfrecords
--caption_folder ~ /captions_train2017_features --image_folder ~ /train2017_features --samples_per_shard 4096
python scripts/data/create_tfrecords_captioning.py --out_tfrecord_folder ~ /val2017_tfrecords
--caption_folder ~ /captions_val2017_features --image_folder ~ /val2017_features --samples_per_shard 4096 Zur Bequemlichkeit haben wir das Skript von NL2Code aus geführt, um den gereinigten Datensatz aus dem Laufwerk zu extrahieren und sie in django_data zu platzieren. Die Vocab -Datei djangovocab.txt befindet sich ebenfalls in diesem Verzeichnis. Alternativ können Sie Rohdaten von ASE15-Django herunterladen und python scripts/data/extract_django.py --data_dir {path to all.anno and all.code) ausführen.
Verarbeiten Sie den Django -Datensatz als nächstes in das TFRECORD -Format für ein effizientes Training.
cd {this_repo}
CUDA_VISIBLE_DEVICES=0 python scripts/data/process_django.py --data_folder ./django_data
--vocab_file ./django_data/djangovocab.txt --dataset_type train/dev/test
--out_feature_folder ./django_data
CUDA_VISIBLE_DEVICES=0 python scripts/data/create_tfrecords_django.py --out_tfrecord_folder ./django_data
--dataset_type train/dev/test --feature_folder ./django_dataExtrahieren Sie zunächst den Datensatz und lernen Sie Byte-Pair-Codierung.
cd {this_repo}
CUDA_VISIBLE_DEVICES=0 python scripts/data/extract_gigaword.py --data_dir {dataroot}
cd {dataroot}/gigaword
subword-nmt learn-joint-bpe-and-vocab --input src_raw_train.txt tgt_raw_train.txt -s 32000 -o joint_bpe.code --write-vocabulary src_vocab.txt tgt_vocab.txt
subword-nmt apply-bpe -c joint_bpe.code --vocabulary src_vocab.txt --vocabulary-threshold 50 < src_raw_train.txt > src_train.BPE.txt
subword-nmt apply-bpe -c joint_bpe.code --vocabulary src_vocab.txt --vocabulary-threshold 50 < src_raw_validation.txt > src_validation.BPE.txt
subword-nmt apply-bpe -c joint_bpe.code --vocabulary src_vocab.txt --vocabulary-threshold 50 < src_raw_test.txt > src_test.BPE.txt
subword-nmt apply-bpe -c joint_bpe.code --vocabulary tgt_vocab.txt --vocabulary-threshold 50 < tgt_raw_train.txt > tgt_train.BPE.txt
subword-nmt apply-bpe -c joint_bpe.code --vocabulary tgt_vocab.txt --vocabulary-threshold 50 < tgt_raw_validation.txt > tgt_validation.BPE.txt
subword-nmt apply-bpe -c joint_bpe.code --vocabulary tgt_vocab.txt --vocabulary-threshold 50 < tgt_raw_test.txt > tgt_test.BPE.txt Generieren Sie dann die Vocab -Datei und verwenden Sie diese Vocab -Datei, um Token in Ganzzahlen umzuwandeln und in einer Funktionsdatei zu speichern. Alternativ können Sie den in unserem Repo bereitgestellten gigaword_vocab.txt verwenden, mit dem wir unser Modell trainiert haben. Setzen Sie dazu das folgende Argument --vocab_file , um {this_repo}/gigaword_vocab.txt zu sein.
cd {this_repo}
CUDA_VISIBLE_DEVICES=0 python scripts/data/process_gigaword.py --out_feature_folder {dataroot}/gigaword
--data_folder {dataroot}/gigaword --vocab_file {dataroot}/gigaword/gigaword_vocab.txt (or {this_repo}/gigaword_vocab.txt)
--dataset_type train/validation/testGenerieren Sie schließlich die TRECORDS -Dateien für Zug-/Validierung/Test.
CUDA_VISIBLE_DEVICES=0 python scripts/data/create_tfrecords_gigaword.py --out_tfrecord_folder {dataroot}/gigaword
--feature_folder {dataroot}/gigaword --samples_per_shard 4096 --dataset_type train/validation/testHier verwenden wir als Beispiel WMT16 RO-EN.
Extrahieren Sie zuerst den Datensatz und lernen Sie Byte-Pair-Codierung.
cd {this_repo}
CUDA_VISIBLE_DEVICES=0 python scripts/data/extract_wmt.py --language_pair 16 ro en --data_dir {dataroot}
cd {dataroot}/wmt16_translate/ro-en
subword-nmt learn-joint-bpe-and-vocab --input src_raw_train.txt tgt_raw_train.txt -s 32000 -o joint_bpe.code --write-vocabulary src_vocab.txt tgt_vocab.txt
subword-nmt apply-bpe -c joint_bpe.code --vocabulary src_vocab.txt --vocabulary-threshold 50 < src_raw_train.txt > src_train.BPE.txt
subword-nmt apply-bpe -c joint_bpe.code --vocabulary src_vocab.txt --vocabulary-threshold 50 < src_raw_validation.txt > src_validation.BPE.txt
subword-nmt apply-bpe -c joint_bpe.code --vocabulary src_vocab.txt --vocabulary-threshold 50 < src_raw_test.txt > src_test.BPE.txt
subword-nmt apply-bpe -c joint_bpe.code --vocabulary tgt_vocab.txt --vocabulary-threshold 50 < tgt_raw_train.txt > tgt_train.BPE.txt
subword-nmt apply-bpe -c joint_bpe.code --vocabulary tgt_vocab.txt --vocabulary-threshold 50 < tgt_raw_validation.txt > tgt_validation.BPE.txt
subword-nmt apply-bpe -c joint_bpe.code --vocabulary tgt_vocab.txt --vocabulary-threshold 50 < tgt_raw_test.txt > tgt_test.BPE.txtCorpus mit Truecase extrahieren, um den Truecaser zu trainieren, der zur Bewertung verwendet wird.
git clone https://github.com/moses-smt/mosesdecoder
cd {this_repo}
CUDA_VISIBLE_DEVICES=0 python scripts/data/extract_wmt.py --language_pair 16 ro en --data_dir {dataroot} --truecase
{path_to_mosesdecoder}/scripts/recaser/train-truecaser.perl -corpus {dataroot}/wmt16_translate/ro-en/src_truecase_train.txt -model {dataroot}/wmt16_translate/ro-en/truecase-model.ro
{path_to_mosesdecoder}/scripts/recaser/train-truecaser.perl -corpus {dataroot}/wmt16_translate/ro-en/tgt_truecase_train.txt -model {dataroot}/wmt16_translate/ro-en/truecase-model.enEntfernen Sie die Diälen von Rumänisch:
git clone https://github.com/rsennrich/wmt16-scripts
cd {dataroot}/wmt16_translate/ro-en/
python {path_to_wmt16-scripts}/preprocess/remove-diacritics.py < src_train.BPE.txt > src_train.BPE.txt
python {path_to_wmt16-scripts}/preprocess/remove-diacritics.py < src_validation.BPE.txt > src_validation.BPE.txt
python {path_to_wmt16-scripts}/preprocess/remove-diacritics.py < src_test.BPE.txt > src_test.BPE.txt------------Notiz-------------
In der Praxis führt das Training mit dem mit dem L2R-Modell erzeugten Destillation-Datensatz (Link) mit Strahlgröße 5 zu einer Verbesserung von 2 Bleu auf WMT16 RO-EN intuitiv, da die Zielsequenzen in diesem neuen Datensatz konsistenter sind. Wir veröffentlichen hier den destillierten Datensatz. Um diesen Datensatz zu verwenden, setzen Sie src_distillation.BPE.txt und tgt_distillation.BPE.txt in {dataroot}/wmt16_translate/ro-en/ . Das Training in diesem destillierten Datensatz erhält sehr ähnliche Auftragsbeobachtungen (dh das Modell generiert alle beschreibenden Token, bevor er die Auxillar -Token generiert) im Vergleich zum Training auf dem ursprünglichen Datensatz.
-----------------------------
Generieren Sie die Vocab -Datei (Joint Vocab für die Quell- und Zielsprachen) und verwenden Sie diese Vocab -Datei, um Token in Ganzzahlen umzuwandeln und in einer Funktionsdatei zu speichern. Da wir vergessen haben, die Diakritik während unserer ersten Experimente zu entfernen und alle fehlenden Vokabellen im diakritisch gerächlichen Korpus anschließend angehängt, unterscheidet sich die Vocabendatei, mit der wir unser Modell trainiert haben, etwas anders als das, das unten über die ro_en_vocab.txt Skripte erstellt wurde. Um diese Vocab -Datei zu verwenden, legen Sie das folgende Argument --vocab_file so ein, dass {this_repo}/ro_en_vocab.txt ist
cd {this_repo}
CUDA_VISIBLE_DEVICES=0 python scripts/data/process_wmt.py --out_feature_folder {dataroot}/wmt16_translate/ro-en
--data_folder {dataroot}/wmt16_translate/ro-en --vocab_file {dataroot}/wmt16_translate/ro_en_vocab.txt (or {this_repo}/ro_en_vocab.txt)
--dataset_type distillation/train/validation/test
Generieren Sie schließlich die TFFRECORDS -Dateien Destillation/Zug/Validierung/Test.
CUDA_VISIBLE_DEVICES=0 python scripts/data/create_tfrecords_wmt.py --out_tfrecord_folder {dataroot}/wmt16_translate/ro-en
--feature_folder {dataroot}/wmt16_translate/ro-en --samples_per_shard 4096 --dataset_type distillation/train/validation/test
Weitere Informationen zum Training eines Modells finden Sie unter Training_scripts.md.
Weitere Informationen zum Validieren / Testen eines Modells finden Sie unter evaluation_visualization_scripts.md.
Wir haben hier für jede Aufgabe vorbereitete Modelle zur Verfügung gestellt. Sie können ein Verzeichnis ckpt_pretrain unter diesem Repo erstellen und sie unter diesem Verzeichnis herunterladen.
Um die vorbereiteten Modelle zu bewerten und ihre Verallgemeinerungsaufträge zu visualisieren, finden Sie Einzelheiten mit Eval_visualize_Petrier_Models.md.
@inproceedings{li2021autoregressiveinference,
title={Discovering Non-monotonic Autoregressive Orderings with Variational Inference},
author={Li, Xuanlin and Trabucco, Brandon and Park, Dong Huk and Luo, Michael and Shen, Sheng and Darrell, Trevor and Gao, Yang},
booktitle={International Conference on Learning Representations},
year={2021},
url={https://openreview.net/forum?id=jP1vTH3inC}
}
DBLP:
@inproceedings{DBLP:conf/iclr/LiTPLSD021,
author = {Xuanlin Li and
Brandon Trabucco and
Dong Huk Park and
Michael Luo and
Sheng Shen and
Trevor Darrell and
Yang Gao},
title = {Discovering Non-monotonic Autoregressive Orderings with Variational
Inference},
booktitle = {9th International Conference on Learning Representations, {ICLR} 2021,
Virtual Event, Austria, May 3-7, 2021},
publisher = {OpenReview.net},
year = {2021},
url = {https://openreview.net/forum?id=jP1vTH3inC},
biburl = {https://dblp.org/rec/conf/iclr/LiTPLSD021.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}


