openai rag chatbot
1.0.0
Demo LLM (RAG Pipeline) aplicativo da web em execução localmente usando o Docker-Compose. Os modelos LLM e incorporação são consumidos como serviços do OpenAI.
O objetivo principal é permitir que os usuários façam perguntas relacionadas à cirurgia LASIK, como "Existe uma contra -indicação para os programadores de computadores conseguirem o LASIK?"
O pipeline de geração aumentada (RAG) recupera as informações mais atualizadas do conjunto de dados para fornecer respostas precisas e relevantes às consultas do usuário.
A arquitetura de aplicativos é apresentada abaixo:
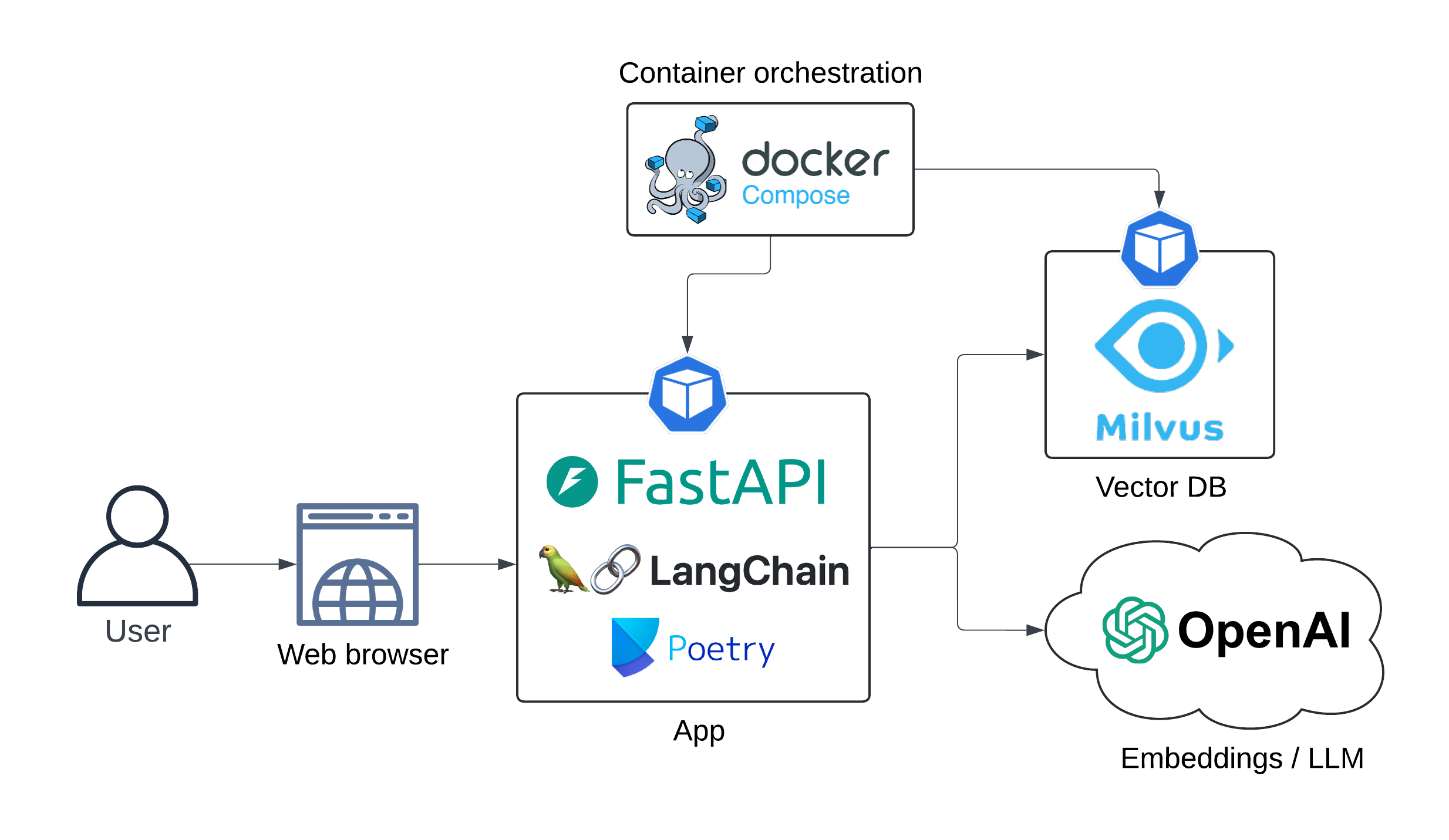
Diagrama de sequência:
Sequenciadoiagram
Usuário->> API LangServe: consulta
Nota Direito do Usuário: Existe uma contra -indicação <br/> para programadores de computador <br/> para obter o LASIK?
API de Langserve->> OpenAI INCEDDINGS: consulta de usuário
Openai INCEDDINGS->> API LANGSERVE: Incorporação
Langserve API->> MILVUSDB: Recuperação de documentos (pesquisa vetorial)
MILVUSDB->> API LANGSERVE: documentos relevantes
Nota Direito da API de Langserve: Prompt <br/> Engenharia ...
API de Langserve->> Openi LLM: prompt enriquecido
Openai LLM->> API LangServe: Resposta gerada
UX:
Construa a imagem do Docker do App:
make app-buildDefina sua chave da API OpenAI como variável de ambiente
export OPENAI_API_KEY= < your-api-key >Spin Up Milvus dB:
make db-upPreencher o banco de dados com o conjunto de dados de complicações de cirurgia ocular do LASIK:
make db-populate
API de spin-up:
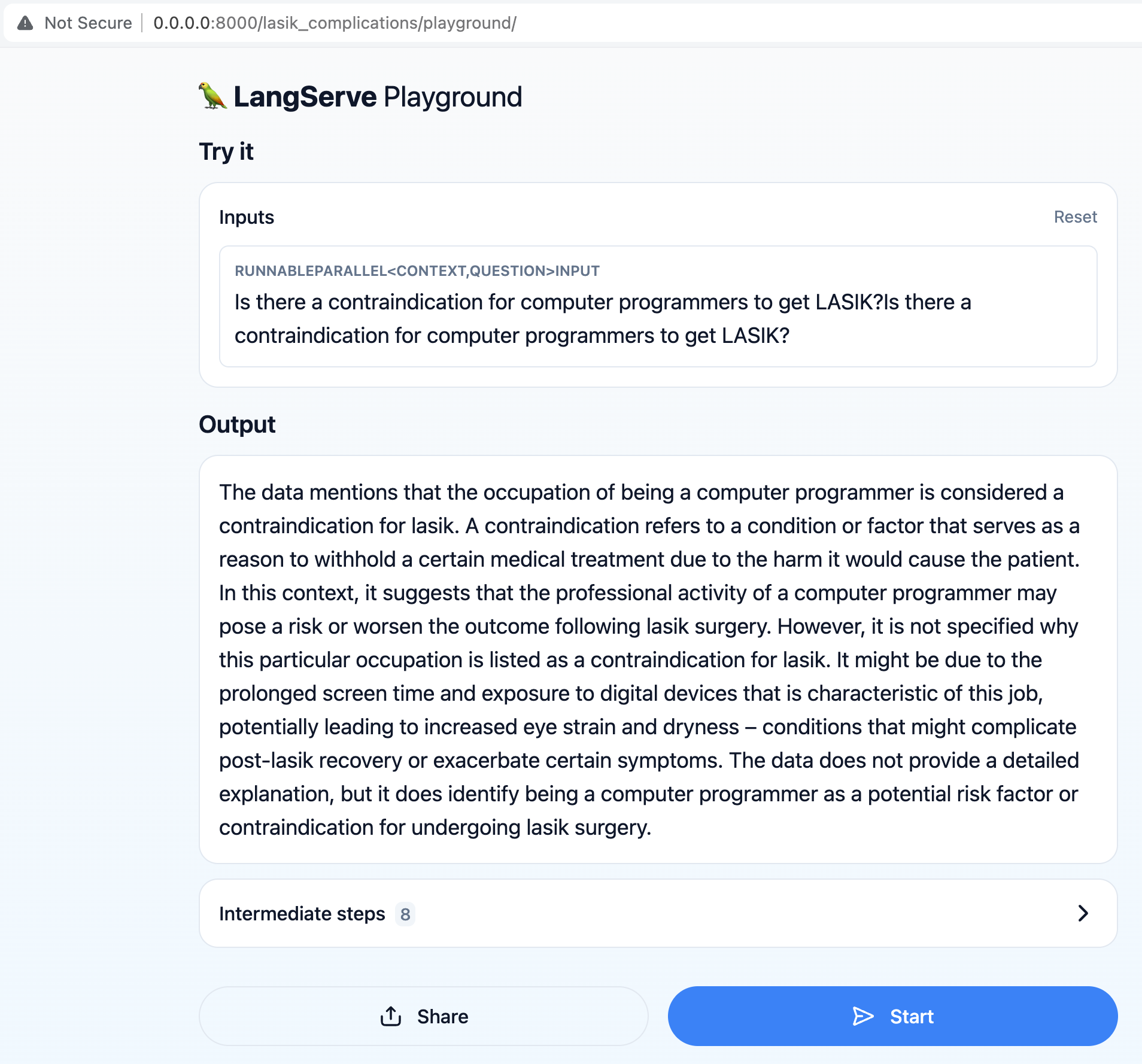
make app-run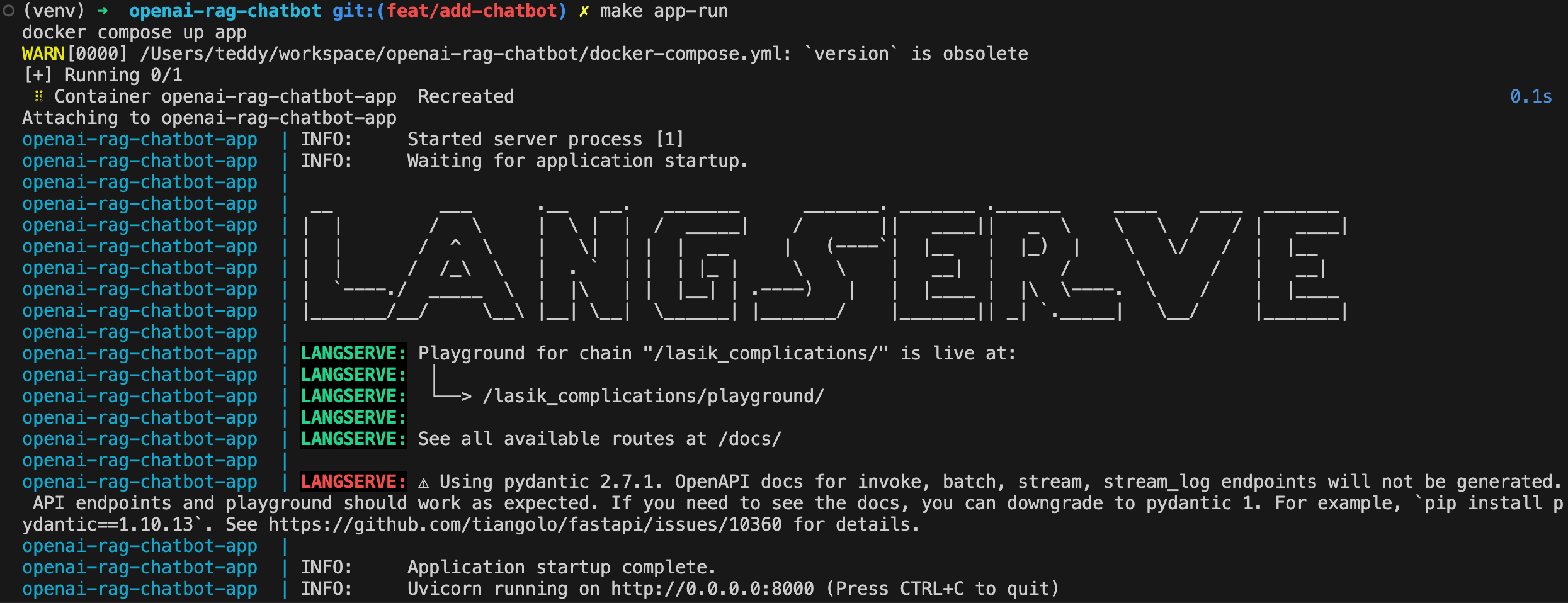
O chatbot já está disponível em http: // localhost: 8000/lasik_complications/playground/
Exibir todos os comandos disponíveis com:
make help 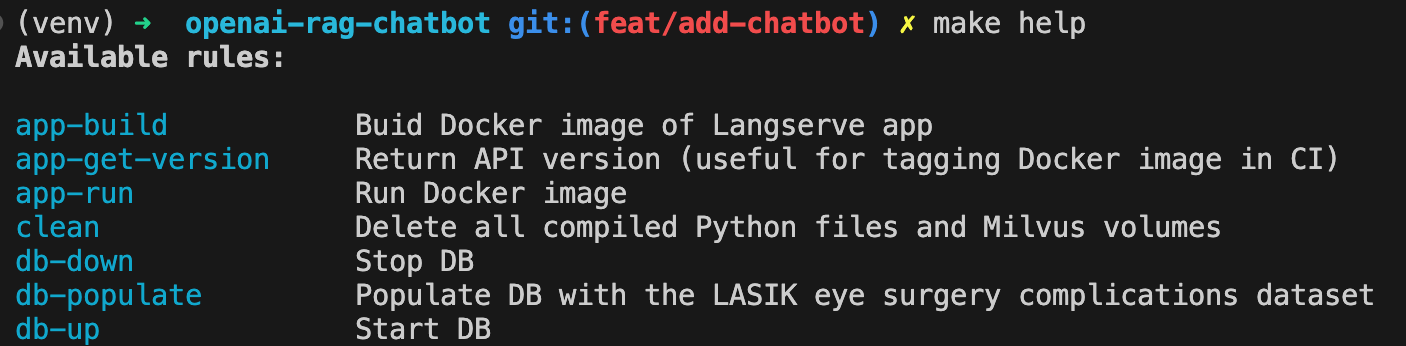
Limpar
make clean ├── .github
│ ├── workflow
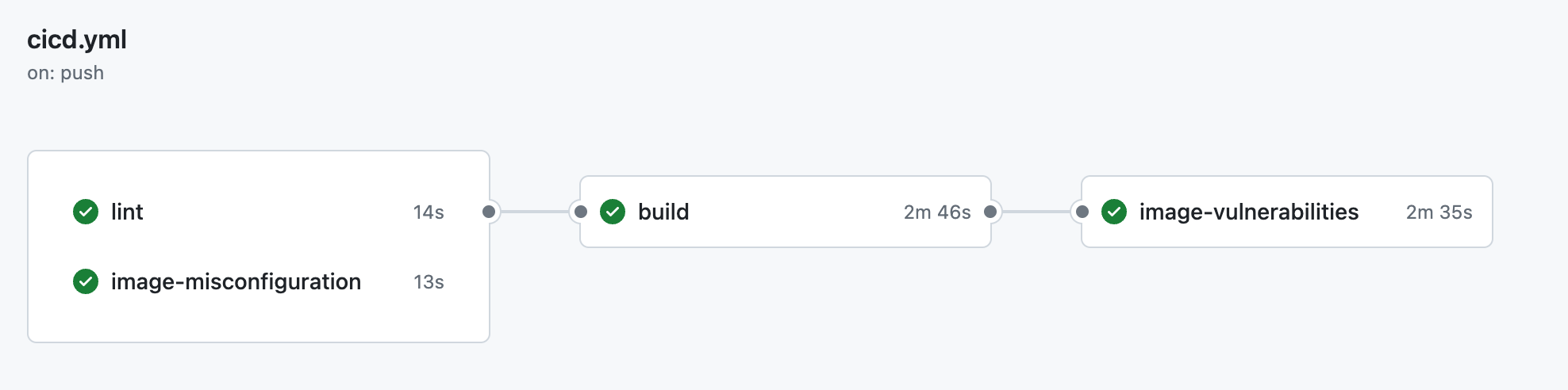
│ │ └── cicd.yml <- CI pipeline definition
├── data
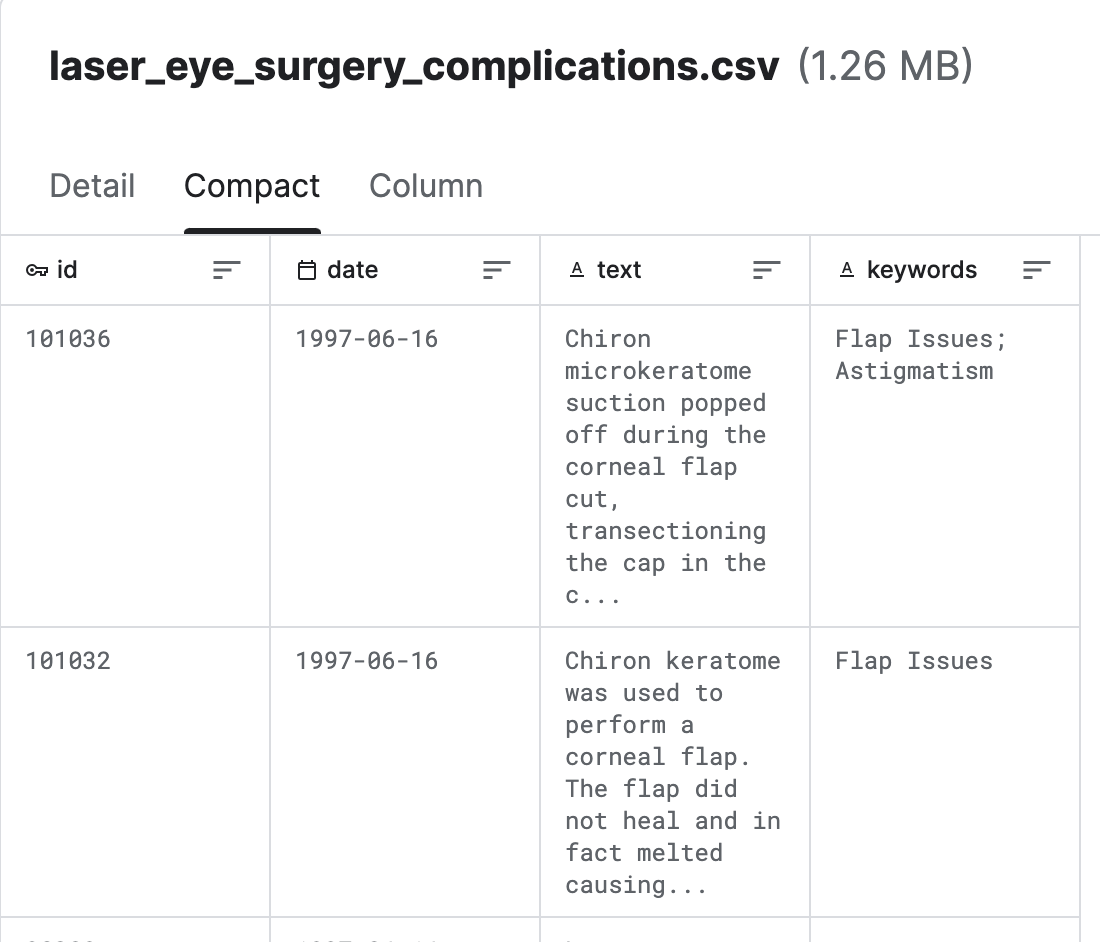
│ └── laser_eye_surgery_complications.csv <- Kaggle dataset
|
├── docs
│ ├── diagrams <- Folder containing diagram definitions
│ └── img <- Folder containing screenshots
│
├── src
│ ├── config.py <- Config file with service host/ports or models to be used
│ ├── populate_vector_db.py <- Scripts that converts texts to embeddings and populates Milvus DB
│ └── server.py <- FastAPI/Langserve/Langchain
│
├── .gitignore
├── .pre-commit-config.yaml <- ruff linter pre-commit hook
├── docker-compose.yml <- container orchestration
├── Dockerfile <- App image definition
├── Makefile <- Makefile with commands like `make app-build`
├── poetry.lock <- Pinned dependencies
├── pyproject.toml <- Dependencies requirements
├── README.md <- The top-level README for developers using this project.
└── ruff.toml <- Linter config
Complicações de Lasik (Laser Eye Surgery) (Kaggle)
O Milvus é um mecanismo de banco de dados de vetor de código aberto desenvolvido pela Zilliz, projetado para armazenar e gerenciar dados vetoriais em larga escala, como incorporação, recursos e dados de alta dimensão. Ele fornece recursos eficientes de armazenamento, indexação e recuperação para tarefas de pesquisa de similaridade vetorial .
O Langchain é uma ferramenta de orquestração LLM, é muito útil quando você precisa criar aplicativos LLM com reconhecimento de contexto.
Para fornecer o contexto ao LLM, temos que envolver a pergunta original em um modelo imediato

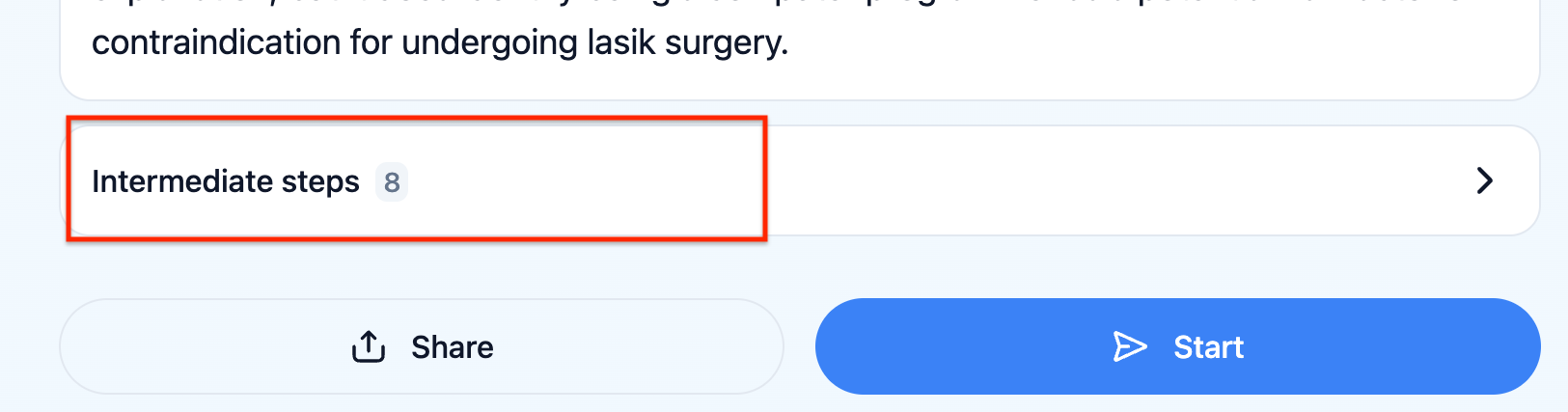
Você pode verificar o que o prompt do LLM realmente recebeu clicando em "Etapas intermediárias" no UX
O LangServe ajuda os desenvolvedores a implantar o Langchain Runnables e as correntes como uma API REST. Esta biblioteca é integrada ao FASTAPI.
O chatbot não pode responder a perguntas relacionadas às estatísticas, por exemplo , "existem tendências recentes nas complicações da cirurgia de LASIK?" , deve haver outro modelo que infecte a janela de tempo relevante a considerar para recuperar os documentos e, em seguida, enriquecer o prompt final com esta janela do tempo.
Feedback algorítmico com Langsmith. Isso permitiria testar a robustez da cadeia LLM de maneira automatizada.


