openai rag chatbot
1.0.0
Application Web Demo LLM (RAG Pipeline) s'exécutant localement à l'aide de Docker-Compose. LLM et les modèles d'intégration sont consommés en tant que services d'OpenAI.
L'objectif principal est de permettre aux utilisateurs de poser des questions liées à la chirurgie LASIK, comme "Y a-t-il une contre-indication pour les programmeurs informatiques d'obtenir le LASIK?"
Le pipeline de génération augmentée (RAG) de récupération récupère les informations les plus à jour de l'ensemble de données pour fournir des réponses précises et pertinentes aux requêtes utilisateur.
L'architecture de l'application est présentée ci-dessous:
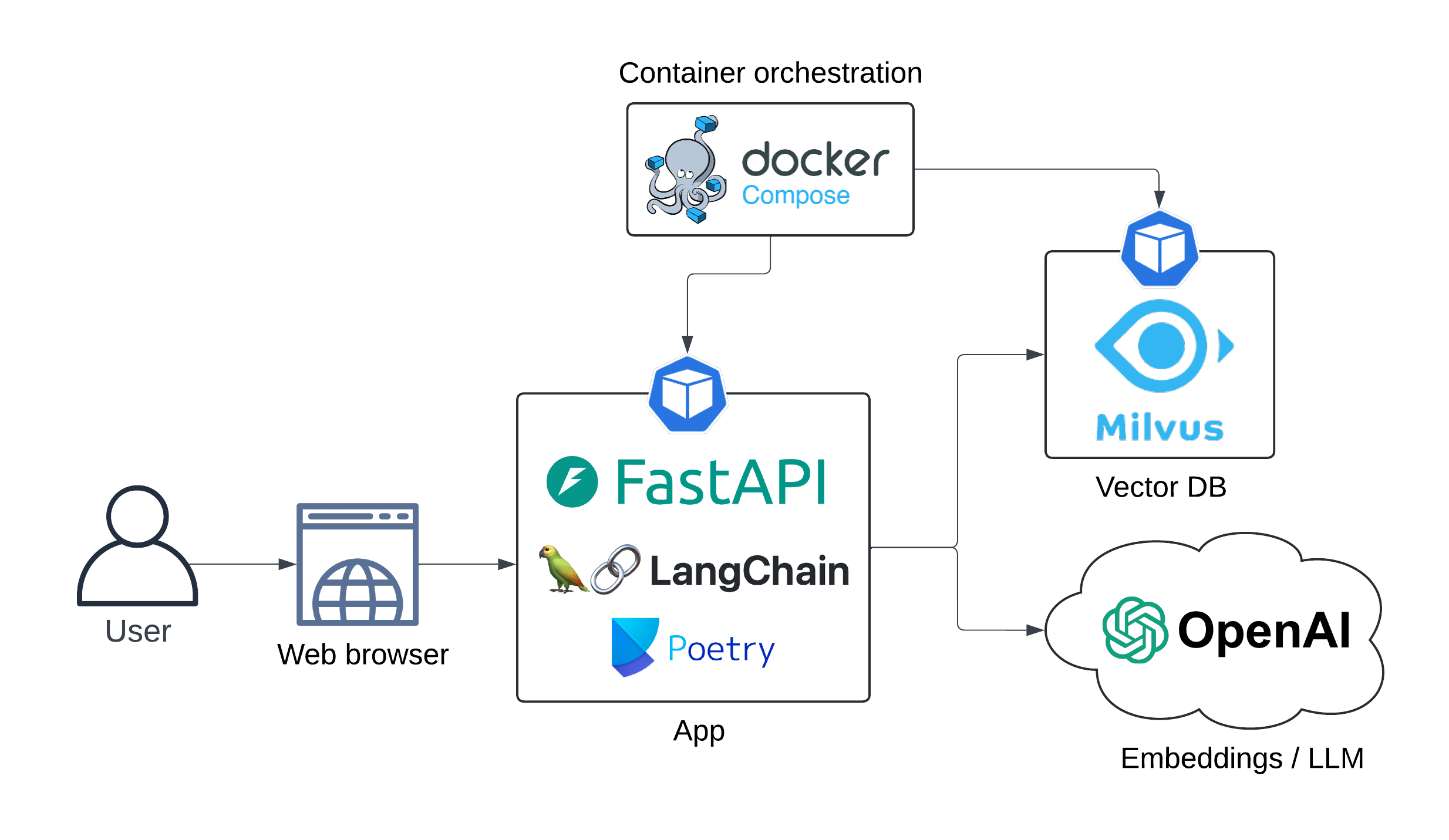
Diagramme de séquence:
séquenchestre
Utilisateur - >> API Langserve: Requête
Remarque Droit de l'utilisateur: Y a-t-il une contre-indication <br/> pour les programmeurs informatiques <br/> pour obtenir LASIK?
API LangServe - >> Openai Embeddings: Requête utilisateur
Openai Embeddings - >> Langserve API: intégrer
API Langserve - >> milvusdb: documents récupération (recherche de vecteur)
Milvusdb - >> API Langserve: documents pertinents
Remarque Droit de Langserve API: Invite <br/> Engineering ...
API Langserve - >> Openai LLM: invite enrichie
Openai LLM - >> API LANGSERVE: Réponse générée
UX:
Créer une image Docker de l'application:
make app-buildDéfinissez votre clé API OpenAI comme variable d'environnement
export OPENAI_API_KEY= < your-api-key >Tournez Milvus DB:
make db-upRépondez à DB avec l'ensemble de données de complications de la chirurgie oculaire du LASIK:
make db-populate
API spin-up:
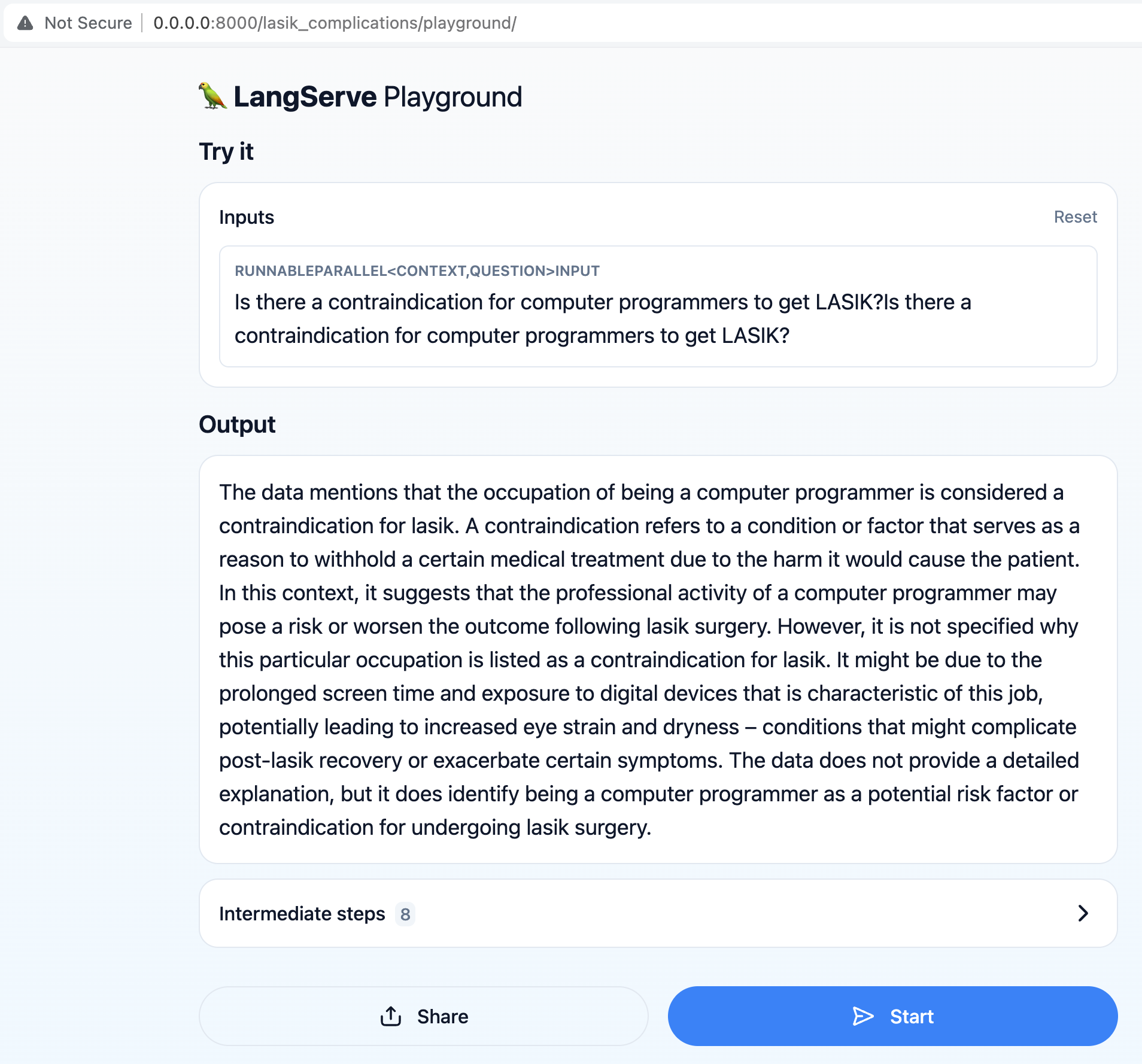
make app-run
Le chatbot est maintenant disponible sur http: // localhost: 8000 / lasik_complications / playground /
Affichez toutes les commandes disponibles avec:
make help 
Nettoyer
make clean ├── .github
│ ├── workflow
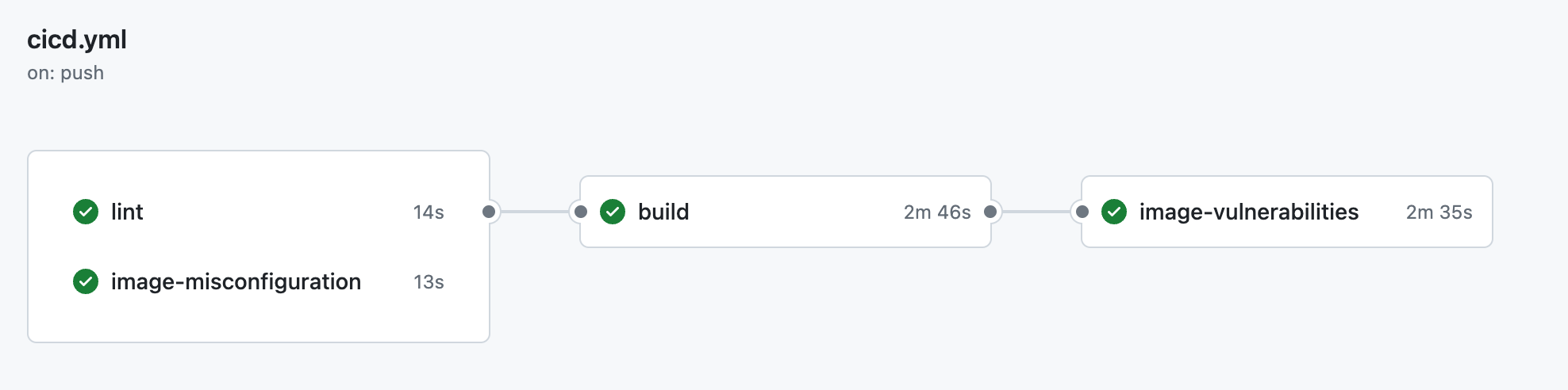
│ │ └── cicd.yml <- CI pipeline definition
├── data
│ └── laser_eye_surgery_complications.csv <- Kaggle dataset
|
├── docs
│ ├── diagrams <- Folder containing diagram definitions
│ └── img <- Folder containing screenshots
│
├── src
│ ├── config.py <- Config file with service host/ports or models to be used
│ ├── populate_vector_db.py <- Scripts that converts texts to embeddings and populates Milvus DB
│ └── server.py <- FastAPI/Langserve/Langchain
│
├── .gitignore
├── .pre-commit-config.yaml <- ruff linter pre-commit hook
├── docker-compose.yml <- container orchestration
├── Dockerfile <- App image definition
├── Makefile <- Makefile with commands like `make app-build`
├── poetry.lock <- Pinned dependencies
├── pyproject.toml <- Dependencies requirements
├── README.md <- The top-level README for developers using this project.
└── ruff.toml <- Linter config
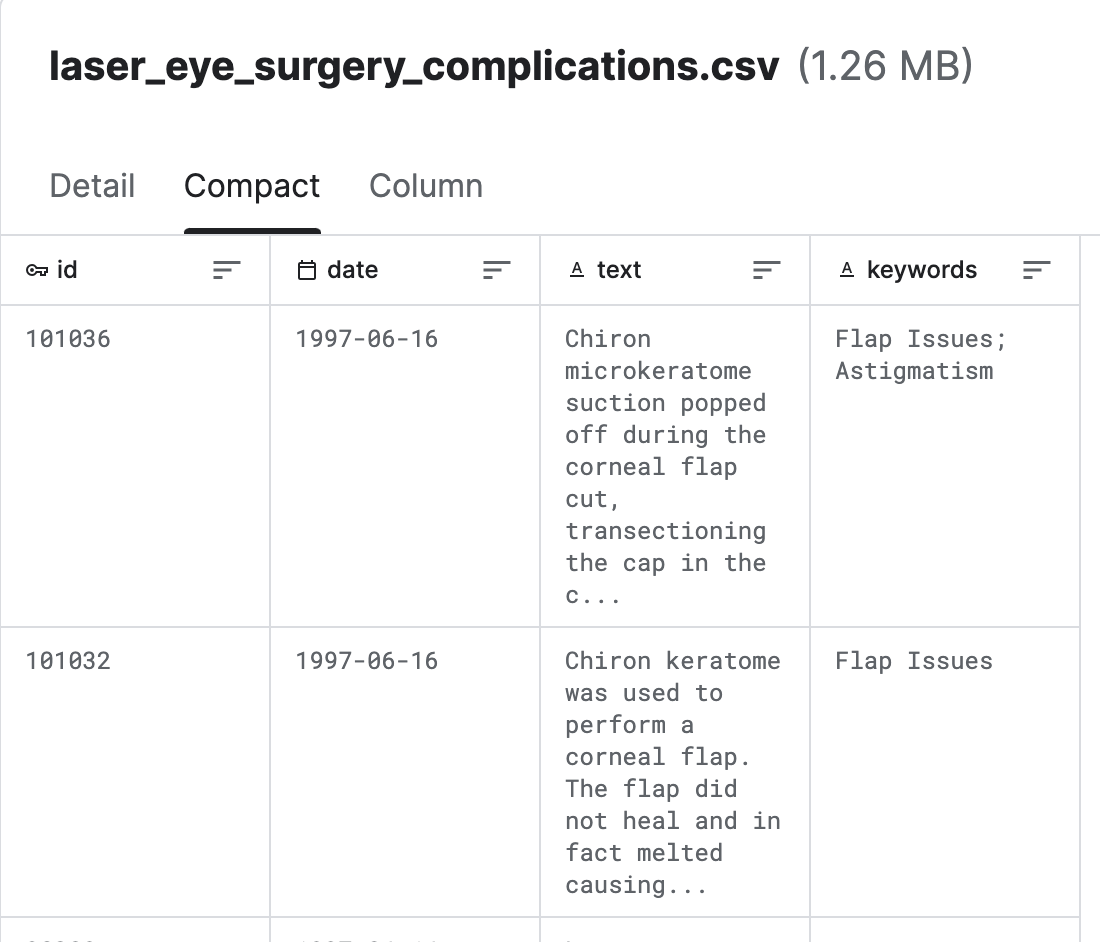
Provenant des complications du LASIK (chirurgie oculaire au laser) (kaggle)
Milvus est un moteur de base de données vectorielle open source développé par Zilliz, conçu pour stocker et gérer des données vectorielles à grande échelle, telles que les intégres, les fonctionnalités et les données de grande dimension. Il offre des capacités de stockage, d'indexation et de récupération efficaces pour les tâches de recherche de similitude vectorielle .
Langchain est un outil d'orchestration LLM, il est très utile lorsque vous devez créer des applications LLM au contexte.
Afin de fournir le contexte au LLM, nous devons envelopper la question d'origine dans un modèle rapide

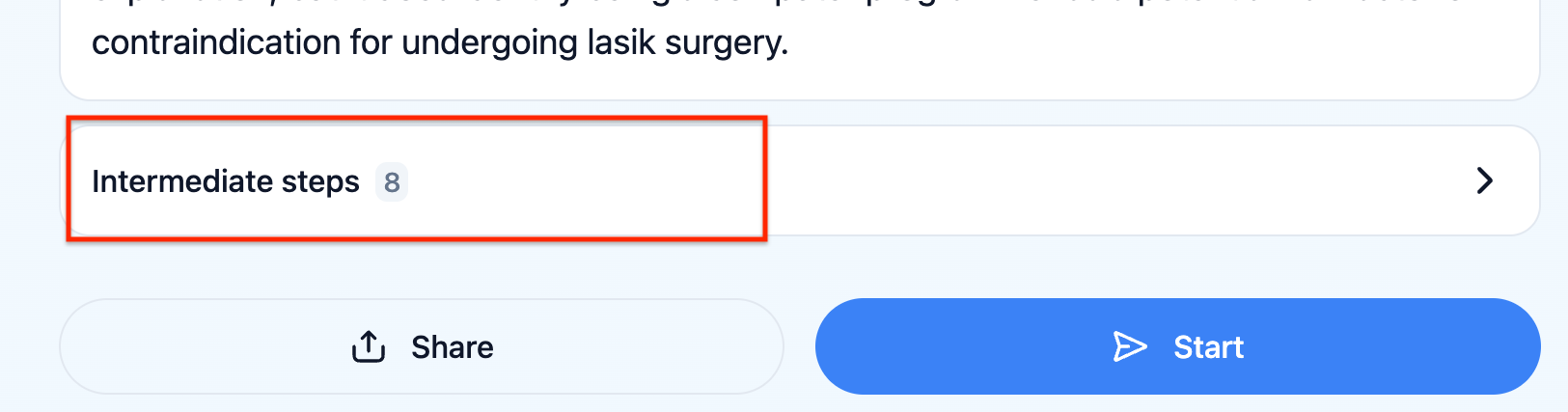
Vous pouvez vérifier ce que le LLM a réellement reçu en cliquant sur "Intermédiaires" dans l'UX
LangServe aide les développeurs à déployer Langchain Runnables and Chains en tant qu'API REST. Cette bibliothèque est intégrée à Fastapi.
Le chatbot ne peut pas répondre aux questions liées aux statistiques, par exemple "Y a-t-il des tendances récentes dans les complications de la chirurgie LASIK?" , il devrait y avoir un autre modèle qui déduit la fenêtre temporelle pertinente à considérer pour récupérer les documents, puis enrichir l'invite finale avec cette fenêtre de temps.
Rétroaction algorithmique avec Langsmith. Cela permettrait de tester la robustesse de la chaîne LLM de manière automatisée.


