GPT2 chitchat
1.0.0
Conta oficial [yeungnlp]
Python3.6, Transformers == 4.2.0, Pytorch == 1.7.0
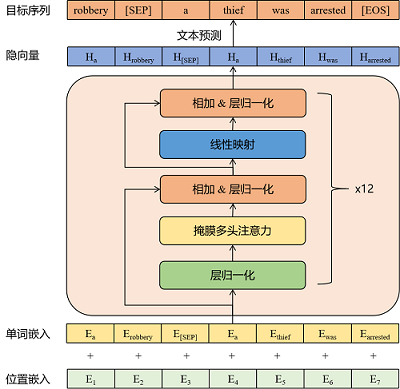
Cada dados de treinamento é emendado e, em seguida, inseri -los no modelo para treinamento.
Para as seguintes várias rodadas de dados de treinamento de bate -papo, ao treinar o modelo, os dados de treinamento são emendados da seguinte forma: "[CLS] querem ver suas lindas fotos [set] me beijarem e mostrar a você [sep] Eu beijo você [sep] Eu odeio pessoas que usam punhos pequenos para dar um soco no seu peito". Em seguida, use os resultados de splicing acima como entrada para o modelo e deixe o modelo passar por treinamento de auto -regressão.
想看你的美照
亲我一口就给你看
我亲两口
讨厌人家拿小拳拳捶你胸口
Faça o download do modelo no compartilhamento de modelos, coloque a pasta Model Model_epoch40_50w no diretório do modelo, execute os seguintes comandos e conduza diálogo
python interact.py --no_cuda --model_path model_epoch40_50w (使用cpu生成,速度相对较慢)
或
python interact.py --model_path model_epoch40_50w --device 0 (指定0号GPU进行生成,速度相对较快)
Crie uma pasta de dados no diretório raiz do projeto, nomeie o corpus de treinamento original. O formato do trem.txt é o seguinte, com uma linha entre cada bate -papo, e o formato é o seguinte:
真想找你一起去看电影
突然很想你
我也很想你
想看你的美照
亲我一口就给你看
我亲两口
讨厌人家拿小拳拳捶你胸口
美女约嘛
开好房等你了
我来啦
Execute preprocess.py, tokenize o Data/Train.txt corpus e serialize e salve -o em dados/treinamento.pkl. O tipo do objeto serializado no trem.pkl é a lista [Lista], que registra os tokens contidos em cada conversa na lista de diálogo.
python preprocess.py --train_path data/train.txt --save_path data/train.pkl
Run Train.Py, use os dados pré -processados para executar o treinamento de auto -regressão no modelo e salve o modelo na pasta do modelo no diretório raiz.
Durante o treinamento, você pode começar cedo, especificando o parâmetro de paciência. Quando paciência = n, se n épocas consecutivas, a perda do modelo no conjunto de verificação não diminuir, então a parada antecipada e o treinamento será interrompido. Quando paciência = 0, nenhuma parada precoce é realizada.
A parada antecipada é desligada por padrão no código, porque na prática, o efeito de geração do modelo obtido pela parada precoce pode não ser melhor.
python train.py --epochs 40 --batch_size 8 --device 0,1 --train_path data/train.pkl
Para obter mais introdução aos parâmetros de treinamento, você pode observar diretamente a descrição do parâmetro na função set_args () em Train.py
Run Interact.py, use o modelo treinado, execute a interação humano-computador e digite Ctrl+Z para encerrar a conversa, o registro de bate-papo será salvo no arquivo de amostra.txt no diretório de amostra.
python interact.py --no_cuda --model_path path_to_your_model --max_history_len 3(由于闲聊对话生成的内容长度不是很长,因此生成部分在CPU上跑速度也挺快的)
Ao executar o interact.py, você pode tentar ajustar o efeito gerado ajustando os parâmetros como Topk, Topp, Repetition_peNalty, max_history_len, etc. Para mais parâmetros, você pode observar diretamente a descrição do parâmetro na função Set_args () da interação. Se você deseja usar a GPU para geração, não ligue para o parâmetro - -no_cuda e use -Device GPU_ID para especificar qual GPU usar.
| Materiais de bate -papo chinês | Endereço do conjunto de dados | Descrição do corpus |
|---|---|---|
| Bate -papos chineses comuns | Chinês_chatbot_corpus | Incluindo Xiaohuang Chicken Corpus, Douban Corpus, Diálogo da série de TV Corpus, Tieba Forum Responder Corpus, Weibo Corpus, Ptt Gossip Corpus, Qingyun Corpus, etc. |
| Materiais de bate -papo chinês 50W | Baidu NetDisk [Código de extração: 4G5E] ou Google Drive | Contém o corpus original e dados pré-processados com diálogo de 50W em várias rodadas |
| Materiais de bate -papo chinês 100W | Baidu NetDisk [Código de Extração: S908] ou Google Drive | Contém o corpus original e dados pré-processados com diálogo de 100W em várias rodadas |
O conteúdo do corpus de bate -papo chinês é o seguinte:
谢谢你所做的一切
你开心就好
开心
嗯因为你的心里只有学习
某某某,还有你
这个某某某用的好
你们宿舍都是这么厉害的人吗
眼睛特别搞笑这土也不好捏但就是觉得挺可爱
特别可爱啊
今天好点了吗?
一天比一天严重
吃药不管用,去打一针。别拖着
| Modelo | Endereço compartilhado | Descrição do modelo |
|---|---|---|
| Model_epoch40_50w | Baidu NetDisk [Código de Extração: Ju6M] ou Google Drive | 40 épocas foram treinadas usando corpus de diálogo de 50W de várias rodadas, e a perda foi reduzida para cerca de 2,0. |

user :你好啊
chatbot:你好,请问您是?
user :我是你的主人啊
chatbot:你是狗吗?
user :你才是狗
chatbot:你不是狗我是你的小主人
user :你这个大笨蛋
chatbot:你大笨蛋,你是想挨打了
user :你全家都是大笨蛋
chatbot:我是你爸爸
user :算了,不跟你吵了,你在干嘛呢
chatbot:我在上班啊,你还没下班呢啊你
user :我周末要做作业啊
chatbot:不是才交了吗,早晚做完啊
user :好多作业啊,还没做完呢
chatbot:我在抄,我妈让我周五交,还有事
user :你就不怕被你妈妈骂吗
chatbot:不怕
user :你周末有去哪里玩吗
chatbot:没时间啊,忙得很啊
user :忙着干嘛呢
chatbot:不知道啊,我周末没有作业,我想睡觉,然后还得找人
user :你好啊
chatbot:你好我好大家好
user :你在干嘛呢
chatbot:你不上课啊
user :今天是周末啊,笨蛋
chatbot:我在学校呢
user :我也是,周末还要做作业
chatbot:我还没写呢我们都还没写
user :周末你有去哪里玩吗
chatbot:没有去南京
user :南京有什么好玩的啊
chatbot:我们没去南京
user :你刚刚又说你去了南京,你是不是耍我啊
chatbot:我刚刚才到南京
user :你好笨啊
chatbot:我没有
user :你是大笨蛋
chatbot:你才是大笨蛋
user :你全家都是大笨蛋
chatbot:你个傻冒
user :你个智障
chatbot:哈哈哈
user :在干嘛
chatbot:睡觉
user :这么早就睡觉啦
chatbot:嗯啊你也早点睡啊
user :我再玩一会儿手机
chatbot:早点休息晚安
user :拜拜啦
chatbot:晚安晚安
user :多喝热水
chatbot:哈哈哈
user :多喝热水
chatbot:好的咯
user :在吗
chatbot:在
user :我不开心
chatbot:怎么啦
user :最近好累啊
chatbot:是挺累的
user :作业好多啊
chatbot:还好还好
user :我觉得我快要挂科了
chatbot:我也是啊,但是我觉得我快熬出头了
user :不说了,我还有好多作业没写
chatbot:我也是啊好多啊
user :那先这样,下次再聊,再见了
chatbot:好哒
user :你去过广州吗
chatbot:去过呀,但是没有找到工作呢
user :那你去过北京吗
chatbot:没有啊
user :北京有什么好玩的
chatbot:没有你想象的那么好
user :是吗,我还没过北京
chatbot:那里我也不怎么熟,我去过北京
user :北京天安门呢
chatbot:没去过,不过可以去玩玩
user :你好
chatbot:你好
user :在干嘛呢
chatbot:在想你呢
user :好害羞啊
chatbot:害羞什么啊
user :你这样夸我,我觉得不好意思呀
chatbot:我夸你你还不好意思呢
user :是啊,哈哈哈
chatbot:你是不是在考验我
user :你怎么会这样想呢
chatbot:我说我在夸你,这么客气,
user :你有睡午觉吗
chatbot:有啊
user :我现在有点困呢
chatbot:我也是
user :等下还要去上课,好烦啊
chatbot:我们不用上课的呀


