GPT2 chitchat
1.0.0
Offizielles Konto [Yeungnlp]
Python3.6, Transformers == 4.2.0, Pytorch == 1.7.0
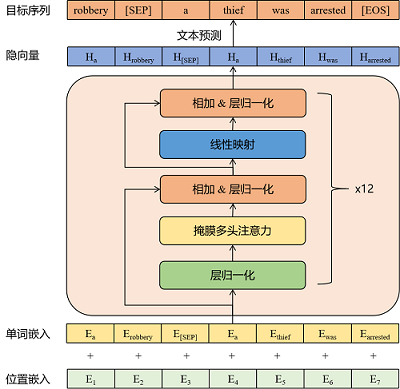
Jedes Trainingsdaten wird gespleißt und dann für das Training in das Modell eingeben.
Für die folgenden mehreren Runden von Chat -Trainingsdaten werden die Trainingsdaten beim Training der Schulungsdaten wie folgt gespleißt: "[CLS] möchten, dass Ihre schönen Fotos [Sep] mich küssen und Ihnen zeigen, dass Sie [Sep] [Sep] küssen Ich hasse Menschen, die kleine Fäuste verwenden, um Ihre Brust [SEP] zu schlagen. Verwenden Sie dann die obigen Spleißergebnisse als Eingabe für das Modell und lassen Sie das Modell ein Autoregressionstraining unterziehen.
想看你的美照
亲我一口就给你看
我亲两口
讨厌人家拿小拳拳捶你胸口
Laden Sie das Modell in der Modellfreigabe herunter, legen Sie das Modell Ordner modell_epoch40_50w in das Modellverzeichnis, führen Sie die folgenden Befehle aus und führen Sie den Dialog durch
python interact.py --no_cuda --model_path model_epoch40_50w (使用cpu生成,速度相对较慢)
或
python interact.py --model_path model_epoch40_50w --device 0 (指定0号GPU进行生成,速度相对较快)
Erstellen Sie einen Datenordner im Projekt Root Directory, nennen Sie den ursprünglichen Trainingscorpus Train.txt und speichern Sie ihn in diesem Verzeichnis. Das Format von Train.txt lautet wie folgt mit einer Zeile zwischen jedem Chat, und das Format lautet wie folgt:
真想找你一起去看电影
突然很想你
我也很想你
想看你的美照
亲我一口就给你看
我亲两口
讨厌人家拿小拳拳捶你胸口
美女约嘛
开好房等你了
我来啦
Führen Sie Preprocess.py aus, tokenisieren Sie die Data/Train.txt -Korpus und serialisieren und speichern Sie sie in Data/Train.pkl. Der Typ des serialisierten Objekts in Train.pkl ist die Liste [Liste], die die in jeder Konversation in der Dialogliste enthaltenen Token aufzeichnet.
python preprocess.py --train_path data/train.txt --save_path data/train.pkl
Rennen Sie Train.py, verwenden Sie die vorverarbeiteten Daten, um ein Autoregressionstraining am Modell durchzuführen, und speichern Sie das Modell im Modellordner im Stammverzeichnis.
Während des Trainings können Sie einen frühen Stopp beginnen, indem Sie den Geduldparameter angeben. Wenn Geduld = n, wenn n aufeinanderfolgende Epochen, nimmt der Verlust des Modells auf dem Verifizierungssatz nicht ab, das frühe Stopp und das Training werden gestoppt. Wenn Geduld = 0 ist, wird kein früher Stopp durchgeführt.
Der frühe Stopp wird standardmäßig im Code ausgeschaltet, da in der Praxis der Erzeugungseffekt des durch frühen Stopp erhaltenen Modells möglicherweise nicht besser ist.
python train.py --epochs 40 --batch_size 8 --device 0,1 --train_path data/train.pkl
Weitere Einführung in die Trainingsparameter können Sie die Parameterbeschreibung in der Funktion set_args () in Train.py direkt ansehen.
Run interact.py, verwenden Sie das geschulte Modell, führen Sie die Interaktion zwischen Mensch und Komputer aus und geben Sie Strg+Z ein, um die Konversation zu beenden. Der Chat-Datensatz wird in der Datei sample.txt im Beispielverzeichnis gespeichert.
python interact.py --no_cuda --model_path path_to_your_model --max_history_len 3(由于闲聊对话生成的内容长度不是很长,因此生成部分在CPU上跑速度也挺快的)
Wenn Sie Interact.py ausführen, können Sie versuchen, den generierten Effekt anzupassen, indem Sie die Parameter wie TOPK, TOPP, Repetition_Penalty, max_history_len usw. anpassen. Für weitere Parameter können Sie die Parameterbeschreibung in der SET_ARGS () -Funktion von Interact.py direkt untersuchen. Wenn Sie die GPU für die Generation verwenden möchten, rufen Sie den Parameter -no_cuda nicht auf und verwenden Sie -Device GPU_ID, um anzugeben, welche GPU verwendet werden soll.
| Chinesische Chat -Materialien | Datensatzadresse | Korpusbeschreibung |
|---|---|---|
| Gemeinsame chinesische Chats | CHITEL_CHATBOT_CORPUS | Einschließlich Xiaohuang Chicken Corpus, Doumban Corpus, TV -Serie Dialoges Corpus, Tieba Forum Reply Corpus, Weibo Corpus, PTT Gossip Corpus, Qingyun Corpus usw. |
| 50W chinesische Chat -Materialien | Baidu NetDisk [Extraktionscode: 4G5E] oder Google Drive | Enthält ursprüngliche Korpus- und vorverarbeitete Daten mit einem 50-W-Mehrrunden-Dialog |
| 100W chinesische Chat -Materialien | Baidu NetDisk [Extraktionscode: S908] oder Google Drive | Enthält ursprüngliche Korpus- und Vorverarbeitungsdaten mit einem 100-W-Mehrrunden-Dialog |
Der Inhalt des chinesischen Chat -Corpus lautet wie folgt:
谢谢你所做的一切
你开心就好
开心
嗯因为你的心里只有学习
某某某,还有你
这个某某某用的好
你们宿舍都是这么厉害的人吗
眼睛特别搞笑这土也不好捏但就是觉得挺可爱
特别可爱啊
今天好点了吗?
一天比一天严重
吃药不管用,去打一针。别拖着
| Modell | Gemeinsame Adresse | Modellbeschreibung |
|---|---|---|
| model_epoch40_50w | Baidu NetDisk [Extraktionscode: Ju6m] oder Google Drive | 40 Epochen wurden mit einem 50-W-Multi-Runden-Dialog-Corpus trainiert, und der Verlust wurde auf rund 2,0 reduziert. |

user :你好啊
chatbot:你好,请问您是?
user :我是你的主人啊
chatbot:你是狗吗?
user :你才是狗
chatbot:你不是狗我是你的小主人
user :你这个大笨蛋
chatbot:你大笨蛋,你是想挨打了
user :你全家都是大笨蛋
chatbot:我是你爸爸
user :算了,不跟你吵了,你在干嘛呢
chatbot:我在上班啊,你还没下班呢啊你
user :我周末要做作业啊
chatbot:不是才交了吗,早晚做完啊
user :好多作业啊,还没做完呢
chatbot:我在抄,我妈让我周五交,还有事
user :你就不怕被你妈妈骂吗
chatbot:不怕
user :你周末有去哪里玩吗
chatbot:没时间啊,忙得很啊
user :忙着干嘛呢
chatbot:不知道啊,我周末没有作业,我想睡觉,然后还得找人
user :你好啊
chatbot:你好我好大家好
user :你在干嘛呢
chatbot:你不上课啊
user :今天是周末啊,笨蛋
chatbot:我在学校呢
user :我也是,周末还要做作业
chatbot:我还没写呢我们都还没写
user :周末你有去哪里玩吗
chatbot:没有去南京
user :南京有什么好玩的啊
chatbot:我们没去南京
user :你刚刚又说你去了南京,你是不是耍我啊
chatbot:我刚刚才到南京
user :你好笨啊
chatbot:我没有
user :你是大笨蛋
chatbot:你才是大笨蛋
user :你全家都是大笨蛋
chatbot:你个傻冒
user :你个智障
chatbot:哈哈哈
user :在干嘛
chatbot:睡觉
user :这么早就睡觉啦
chatbot:嗯啊你也早点睡啊
user :我再玩一会儿手机
chatbot:早点休息晚安
user :拜拜啦
chatbot:晚安晚安
user :多喝热水
chatbot:哈哈哈
user :多喝热水
chatbot:好的咯
user :在吗
chatbot:在
user :我不开心
chatbot:怎么啦
user :最近好累啊
chatbot:是挺累的
user :作业好多啊
chatbot:还好还好
user :我觉得我快要挂科了
chatbot:我也是啊,但是我觉得我快熬出头了
user :不说了,我还有好多作业没写
chatbot:我也是啊好多啊
user :那先这样,下次再聊,再见了
chatbot:好哒
user :你去过广州吗
chatbot:去过呀,但是没有找到工作呢
user :那你去过北京吗
chatbot:没有啊
user :北京有什么好玩的
chatbot:没有你想象的那么好
user :是吗,我还没过北京
chatbot:那里我也不怎么熟,我去过北京
user :北京天安门呢
chatbot:没去过,不过可以去玩玩
user :你好
chatbot:你好
user :在干嘛呢
chatbot:在想你呢
user :好害羞啊
chatbot:害羞什么啊
user :你这样夸我,我觉得不好意思呀
chatbot:我夸你你还不好意思呢
user :是啊,哈哈哈
chatbot:你是不是在考验我
user :你怎么会这样想呢
chatbot:我说我在夸你,这么客气,
user :你有睡午觉吗
chatbot:有啊
user :我现在有点困呢
chatbot:我也是
user :等下还要去上课,好烦啊
chatbot:我们不用上课的呀


