inference audiocraft musicgen on amazon sagemaker
1.0.0
Implante o Audiocraft MusicGen no Amazon Sagemaker usando o Sagemaker Endpoints para inferência assíncrona.
Blog: Inference Audiocraft MusicGen Models usando a Amazon Sagemaker
Esta solução demonstra a implantação de modelos Audiocraft MusicGen da HuggingFace no Amazon Sagemaker. Os modelos MusicGen tomam o texto da linguagem natural como prompt de entrada e geram música como saída.

O Audiocraft consiste em três modelos: MusicGen, Audiogen e Encodec. Este repositório visa implantar modelos MusicGen no Amazon Sagemaker para a inferência assíncrona.
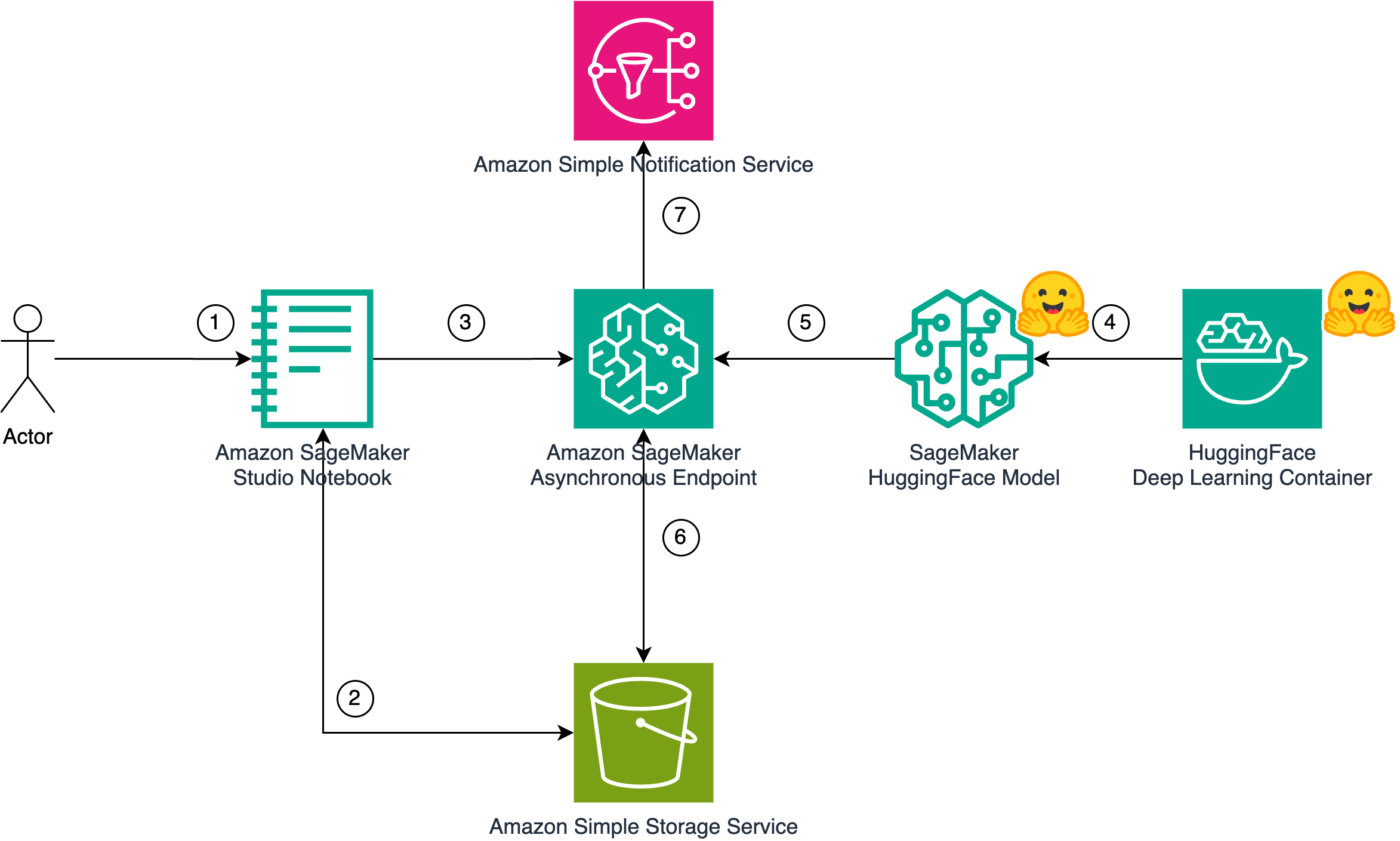
facebook/musicgen-large será implantado em um terminal assíncrono de sagema. Este terminal será usado para inferir para a geração de música.HuggingFaceModel será implantado em um terminal assíncrono de sagema.facebook/musicgen-large no escopo deste blog, será enviado para o S3 durante a implantação. Além disso, durante a inferência, as saídas geradas serão enviadas para S3.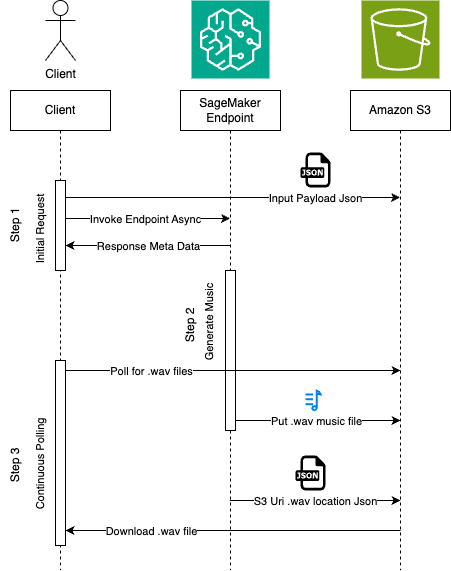
Os notebooks de implantação usados neste repositório usa o HuggingFace como provedor de modelos para os modelos MusicGen. A implantação correspondente e a inferência NoteBoks para os respectivos modelos são tablulados abaixo.
| ID do modelo HuggingACE | Notebook de implantação | Caderno de inferência |
|---|---|---|
| Facebook/MusicGen-Large | Implantar | Inferência |
| Facebook/MusicGen-Medium | Implantar | Inferência |
| Facebook/MusicGen-Small | Implantar | Inferência |
Consulte contribuindo para mais informações.
@inproceedings{copet2023simple,
title={Simple and Controllable Music Generation},
author={Jade Copet and Felix Kreuk and Itai Gat and Tal Remez and David Kant and Gabriel Synnaeve and Yossi Adi and Alexandre Défossez},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
}
Esta biblioteca está licenciada sob a licença MIT-0. Veja o arquivo de licença.


