inference audiocraft musicgen on amazon sagemaker
1.0.0
Menyebarkan Audiocraft MusicGen di Amazon Sagemaker menggunakan titik akhir Sagemaker untuk inferensi async.
Blog: Model Musicgen Audiocraft Inference Menggunakan Amazon Sagemaker
Solusi ini menunjukkan menggunakan model musik audiocraft dari Huggingface di Amazon Sagemaker. Model MusicGen mengambil teks bahasa alami sebagai prompt input dan menghasilkan musik sebagai output.

Audiocraft terdiri dari tiga model: MusicGen, Audiogen, dan Encodec. Repo ini bertujuan untuk menggunakan model musik di Amazon Sagemaker untuk inferencing asinkron.
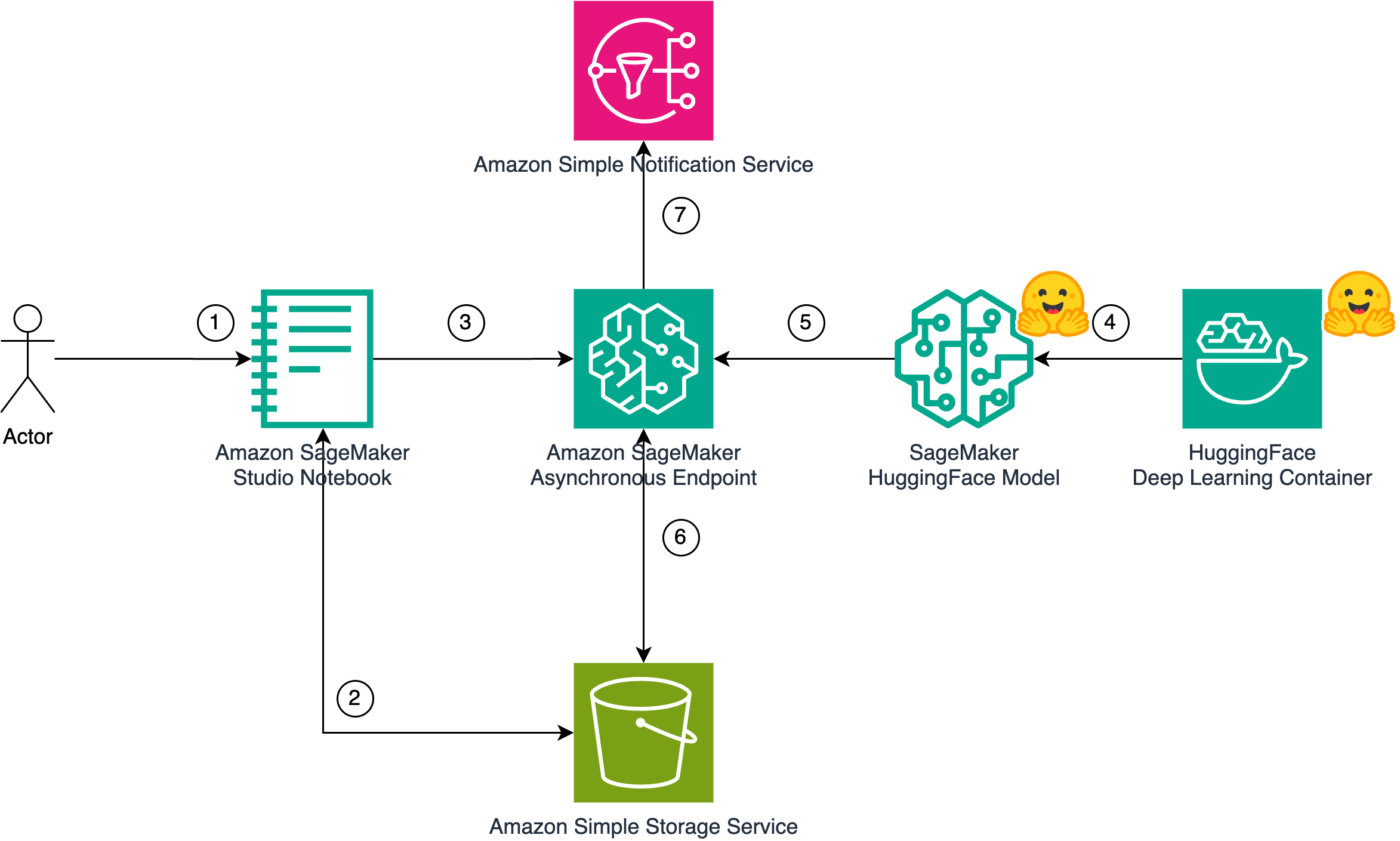
facebook/musicgen-large akan digunakan ke titik akhir asinkron Sagemaker. Titik akhir ini akan digunakan untuk menyimpulkan untuk generasi musik.HuggingFaceModel akan digunakan ke titik akhir asinkron Sagemaker.facebook/musicgen-large dalam ruang lingkup blog ini, akan diunggah ke S3 selama penyebaran. Juga, selama inferensi, output yang dihasilkan akan diunggah ke S3.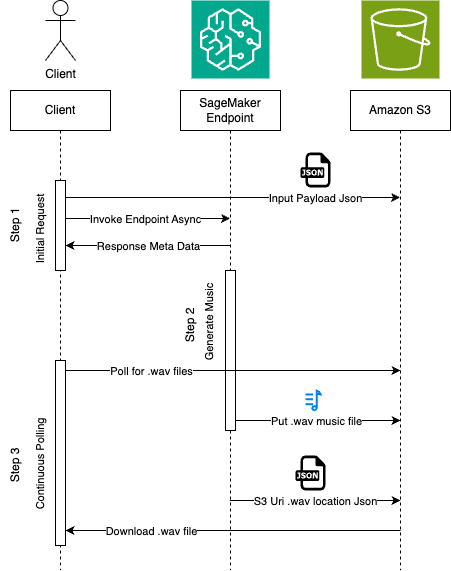
Notebook penyebaran yang digunakan dalam repo ini menggunakan HuggingFace sebagai penyedia model untuk model MusicGen. Penyebaran dan notebok inferensi yang sesuai untuk masing -masing model diubah di bawah ini.
| ID Model Huggingace | Menyebarkan buku catatan | Notebook inferensi |
|---|---|---|
| Facebook/Musicgen-Large | Menyebarkan | Kesimpulan |
| Facebook/Musicgen-Medium | Menyebarkan | Kesimpulan |
| Facebook/Musicgen-Small | Menyebarkan | Kesimpulan |
Lihat berkontribusi untuk informasi lebih lanjut.
@inproceedings{copet2023simple,
title={Simple and Controllable Music Generation},
author={Jade Copet and Felix Kreuk and Itai Gat and Tal Remez and David Kant and Gabriel Synnaeve and Yossi Adi and Alexandre Défossez},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023},
}
Perpustakaan ini dilisensikan di bawah lisensi MIT-0. Lihat file lisensi.


