hbox
v1.8.0

Renomeamos a repositir de Xlearning para Hbox.
Se você tiver um clone local do repositório, atualize seu URL remoto:
git remote set-url origin https://github.com/Qihoo360/hbox.gitO Hbox é uma plataforma de agendamento conveniente e eficiente, combinada com o big data e a inteligência artificial, suporte para uma variedade de aprendizado de máquina, estruturas de aprendizado profundo. O Hbox está em execução no Yarn Hadoop e integrou estruturas de aprendizado profundo, como Tensornet, Tensorflow, MxNet, Caffe, Theano, Pytorch, Keras, Xgboost, Horovod, OpenMPI, Tensor2tensor. Apoie o cronograma de recursos da GPU, executado na interface Docker e RESTful API Management. O HBOX possui a escalabilidade e compatibilidade satisfatórias.
中文文档
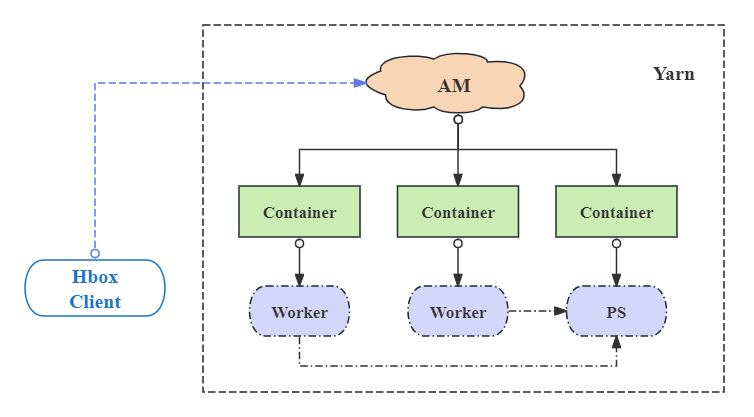
Existem três componentes essenciais no Hbox:
Além do modo distribuído das estruturas TensorFlow e MXNET, o HBOX suporta o modo independente de todas as estruturas de aprendizado profundo, como Caffe, Theano, Pytorch. Além disso, o HBOX permite as versões personalizadas e a versão múltipla das estruturas de maneira flexível.
Dados de treinamento e resultado do modelo Salvar no HDFS (Suporte S3). O Hbox pode especificar a estratégia de entrada para os dados de entrada --input Input, configurando o parâmetro --input-strategy ou hbox.input.strategy Configuration. Hbox suporta três maneiras de ler os dados de entrada HDFS:
Semelhante com a estratégia de leitura, o HBOX permite especificar a estratégia de saída para os dados de saída --output saída, configurando o parâmetro --output-strategy ou hbox.output.strategy Configuration. Existem dois tipos de modos de saída de resultado:
Mais detalhes, consulte o gerenciamento de dados
A interface do aplicativo pode ser dividida em quatro partes:
Exceto a construção automática do clusterspec na estrutura de tensorflow do modo distribuído, o programa no modo independente do modo tensorflow e outras estruturas de aprendizado profundo podem ser executadas diretamente no HBOX.
Execute o seguinte comando no diretório raiz do código -fonte:
./mvnw package
Após a compilação, um pacote de distribuição chamado hbox-1.1-dist.tar.gz será gerado em core/target no diretório raiz. Deseppalhando o pacote de distribuição, os seguintes subdiretórios serão gerados no diretório raiz:
Para configurar as configurações, o usuário precisa definir HBOX_CONF_DIR como uma pasta contendo um hbox-site.xml válido ou vincular esta pasta a $HBOX_HOME/conf .
No diretório "conf" do pacote de distribuição de desempacotar "$ hbox_home", configure os arquivos relacionados:
hbox-env.sh: defina as variáveis de ambiente, como:
hbox-site.xml: configure propriedades relacionadas. Observe que as propriedades associadas ao serviço de história precisam ser consistentes com o que foi configurado quando o serviço de história começou. Para mais detalhes, consulte a parte da configuração 。
log4j.properties: Configure o nível de log
$HBOX_HOME/sbin/start-history-server.sh . Use $HBOX_HOME/bin/hbox-submit para enviar o aplicativo para cluster no cliente hbox. Aqui estão o exemplo de envio para o aplicativo TensorFlow.
Carregue o diretório "dados" sob a raiz do pacote de distribuição de descompacagem para HDFS
cd $HBOX_HOME
hadoop fs -put data /tmp/
cd $HBOX_HOME/examples/tensorflow
$HBOX_HOME/bin/hbox-submit
--app-type "tensorflow"
--app-name "tf-demo"
--input /tmp/data/tensorflow#data
--output /tmp/tensorflow_model#model
--files demo.py,dataDeal.py
--worker-memory 10G
--worker-num 2
--worker-cores 3
--ps-memory 1G
--ps-num 1
--ps-cores 2
--queue default
python demo.py --data_path=./data --save_path=./model --log_dir=./eventLog --training_epochs=10
O significado dos parâmetros é o seguinte:
| Nome da propriedade | Significado |
|---|---|
| nome de aplicativo | Nome do aplicativo como "TF-Demo" |
| Tipo de aplicativo | Tipo de aplicativo como "tensorflow" |
| entrada | Arquivo de entrada, o caminho HDFS é "/tmp/dados/tensorflow" relacionado ao dir local "./data" |
| saída | Arquivo de saída , O caminho HDFS é "/tmp/tensorflow_model" relacionado ao dir local "./model" |
| arquivos | Programa de aplicativos e arquivos locais necessários, incluindo Demo.py, Datadeal.py |
| Memória do trabalhador | A quantidade de memória a ser usada para o processo do trabalhador é de 10 GB |
| trabalhador-num | O número de contêineres de trabalhador a ser usado para o aplicativo é 2 |
| trabalhadores-núcleos | O número de núcleos a serem usados para o processo do trabalhador é 3 |
| PS-Memória | A quantidade de memória a ser usada para o processo PS é de 1 GB |
| PS-Num | O número de contêineres PS a serem usados para o aplicativo é 1 |
| PS-CORES | O número de núcleos a serem usados para o processo PS é 2 |
| fila | a fila que o pedido enviou para |
Para mais detalhes, defina a parte do parâmetro de envio 。
Hbox FAQ
Hbox foi projetado, autor, revisado e testado pela equipe no Github:
@Yuance li, @wen Ouyang, @runying jia, @yuhan jia, @lei wang



