hbox
v1.8.0

Wir haben die Repositiry von Xlearning in Hbox umbenannt.
Wenn Sie einen lokalen Klon des Repositorys haben, aktualisieren Sie bitte Ihre Remote -URL:
git remote set-url origin https://github.com/Qihoo360/hbox.gitHBox ist eine bequeme und effiziente Planungsplattform in Kombination mit den Big Data und künstlichen Intelligenz und Unterstützung für eine Vielzahl von maschinellen Lernen, Deep -Learning -Frameworks. Hbox läuft auf dem Hadoop -Garn und hat Deep -Learning -Frameworks wie Tensornet, Tensorflow, Mxnet, Caffe, Theano, Pytorch, Keras, Xgboost , Horovod, OpenMPI, Tensor2tensor integriert. Unterstützen Sie den GPU -Ressourcenplan, führen Sie in Docker und RESTful API -Verwaltungsschnittstelle aus. Hbox hat die zufriedenstellende Skalierbarkeit und Kompatibilität.
中文文档
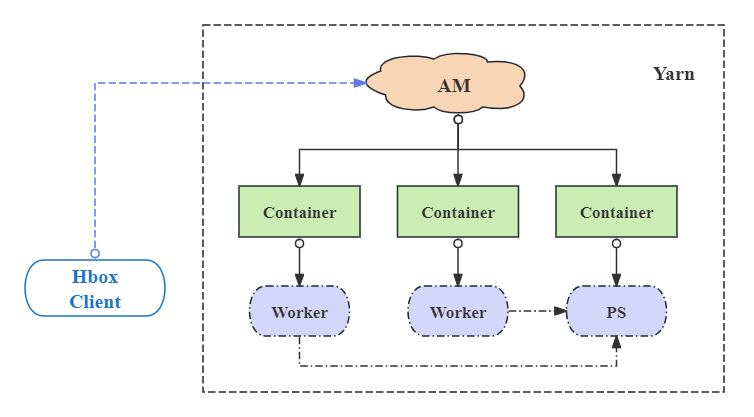
In Hbox gibt es drei wesentliche Komponenten:
Neben dem verteilten Modus des Tensorflow- und MXNET -Frameworks unterstützt Hbox den eigenständigen Modus aller Deep -Lern -Frameworks wie Caffe, Theano, Pytorch. Darüber hinaus ermöglicht HBox die benutzerdefinierten Versionen und die Mehrversion von Frameworks flexibel.
Trainingsdaten und Modellergebnisse auf HDFS (Support S3). HBox ist aktiviert, um die Eingabestrategie für die Eingabedaten --input durch Einstellen des Parameters --input-strategy oder hbox.input.strategy -Konfiguration anzugeben. HBOX unterstützt drei Möglichkeiten, um die HDFS -Eingabedaten zu lesen:
Ähnlich wie bei der Lesestrategie können die Ausgangsstrategie für die Ausgabedaten --output angeben, indem der Parameter- --output-strategy oder hbox.output.strategy -Konfiguration festgelegt wird. Es gibt zwei Arten von Ergebnisausgabemodi:
Weitere Details Siehe Datenverwaltung
Die Anwendungsschnittstelle kann in vier Teile unterteilt werden:
Mit Ausnahme der automatischen Konstruktion des ClusterSpec im TensorFlow -Framework des verteilten Modus kann das Programm im Standalone -Modus TensorFlow und andere Deep -Learning -Frameworks direkt bei Hbox ausgeführt werden.
Führen Sie den folgenden Befehl im Stammverzeichnis des Quellcode aus:
./mvnw package
Nach dem Kompilieren wird ein Distributionspaket namens hbox-1.1-dist.tar.gz im Stammverzeichnis unter core/target generiert. Wenn Sie das Verteilungspaket auspacken, werden die folgenden Unterverzeichnisse im Root -Verzeichnis erstellt:
Um Konfigurationen einzurichten, muss der Benutzer HBOX_CONF_DIR auf einen Ordner einstellen, der eine gültige hbox-site.xml enthält, oder diesen Ordner mit $HBOX_HOME/conf verlinken.
Konfigurieren Sie unter dem Verzeichnis "Conf" des Auspackverteilungspakets "$ hbox_home" die zugehörigen Dateien:
HBOX-ENV.SH: Setzen Sie die Umgebungsvariablen, wie z. B.:
hbox-site.xml: Konfigurieren Sie verwandte Eigenschaften. Beachten Sie, dass die mit dem Verlaufsdienst verbundenen Eigenschaften mit dem konfiguriert sein müssen, was beim Start des Verlaufsdienstes konfiguriert ist. Weitere Informationen finden Sie im Konfigurationsteil 。
log4j.properties: configure die Protokollebene
$HBOX_HOME/sbin/start-history-server.sh aus. Verwenden Sie $HBOX_HOME/bin/hbox-submit , um die Anwendung an Cluster im HBox-Client einzureichen. Hier sind das Beispiel für die TensorFlow -Anwendung.
Laden Sie das Verzeichnis "Daten" unter das Root of Auspackverteilungspaket auf HDFS hoch
cd $HBOX_HOME
hadoop fs -put data /tmp/
cd $HBOX_HOME/examples/tensorflow
$HBOX_HOME/bin/hbox-submit
--app-type "tensorflow"
--app-name "tf-demo"
--input /tmp/data/tensorflow#data
--output /tmp/tensorflow_model#model
--files demo.py,dataDeal.py
--worker-memory 10G
--worker-num 2
--worker-cores 3
--ps-memory 1G
--ps-num 1
--ps-cores 2
--queue default
python demo.py --data_path=./data --save_path=./model --log_dir=./eventLog --training_epochs=10
Die Bedeutung der Parameter ist wie folgt:
| Eigenschaftsname | Bedeutung |
|---|---|
| App-Namen | Anwendungsname als "TF-Demo" |
| App-Typ | Anwendungstyp als "Tensorflow" |
| Eingang | Eingabedatei, HDFS -Pfad ist "/tmp/data/TensorFlow", die auf lokale Dir "./Data" bezogen werden. |
| Ausgabe | Ausgabedatei , HDFS -Pfad "/tmp/TensorFlow_Model" in Bezug auf lokale Dir ./Model "" |
| Dateien | Anwendungsprogramm und erforderliche lokale Dateien, einschließlich Demo.py, datAdeal.py |
| Arbeitergedächtnis | Die für den Arbeitsprozess zu verwendende Speichermenge beträgt 10 GB |
| Arbeiter-Num | Die Anzahl der für die Anwendung zu verwendenden Arbeitercontainer beträgt 2 |
| Arbeiterkorte | Die Anzahl der für den Arbeitsprozess zu verwendenden Kerne beträgt 3 |
| PS-Memory | Die für den PS -Prozesse zu verwendende Speichermenge beträgt 1 GB |
| PS-Num | Die Anzahl der für die Anwendung zu verwendenden PS -Container beträgt 1 |
| PS-Cores | Die Anzahl der für den PS -Prozess zu verwendenden Kerne beträgt 2 |
| Warteschlange | die Warteschlange, an die dieser Antrag eingereicht wird |
Weitere Informationen finden Sie im Parameter Teil。 Senden 。
HBox -FAQ
Hbox wurde vom Team im GitHub entworfen, verfasst, überprüft und getestet:
@Yuance li, @wen ouyang, @runying jia, @yuhan jia, @lei Wang



