tensorwatch
1.0.0
O TensorWatch é uma ferramenta de depuração e visualização projetada para ciência de dados, aprendizado profundo e aprendizado de reforço com a Microsoft Research. Ele funciona no Jupyter Notebook para mostrar visualizações em tempo real do seu treinamento de aprendizado de máquina e executar várias outras tarefas importantes de análise para seus modelos e dados.
O TensorWatch foi projetado para ser flexível e extensível, para que você também possa criar suas próprias visualizações, UIs e painéis personalizados. Além da abordagem tradicional de "o que você é, é o que você está lá", também tem uma capacidade única de executar consultas arbitrárias contra o seu processo de treinamento ao vivo de ML, retornar um fluxo como resultado da consulta e visualizar esse fluxo usando sua escolha de um visualizador (chamamos esse modo de log preguiçoso).
O TensorWatch está sob desenvolvimento pesado, com o objetivo de fornecer uma plataforma para depurar o aprendizado de máquina em um pacote fácil de usar, extensível e hackeable.
pip install tensorwatch
O TensorWatch suporta Python 3.x e é testado com Pytorch 0.4-1.x. A maioria dos recursos também deve funcionar com tensores ansiosos do TensorFlow. O TensorWatch usa o GraphViz para criar diagramas de rede e, dependendo da sua plataforma, em algum momento, você pode precisar instalá -lo manualmente.
Aqui está um código simples que registra um número inteiro e seu quadrado como uma tupla a cada segundo para o Tensorwatch:
import tensorwatch as tw
import time
# streams will be stored in test.log file
w = tw.Watcher(filename='test.log')
# create a stream for logging
s = w.create_stream(name='metric1')
# generate Jupyter Notebook to view real-time streams
w.make_notebook()
for i in range(1000):
# write x,y pair we want to log
s.write((i, i*i))
time.sleep(1)
Quando você executa esse código, você notará que um notebook Jupyter test.ipynb é criado em sua pasta de script. De um jupyter notebook Tipo de prompt de comando e selecione test.ipynb . Escolha célula> Execute tudo no menu para ver o gráfico de linha em tempo real, pois os valores são gravados em seu script.
Aqui está a saída que você verá no Jupyter Notebook:
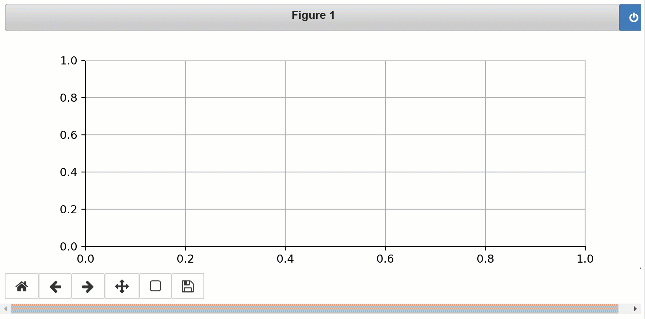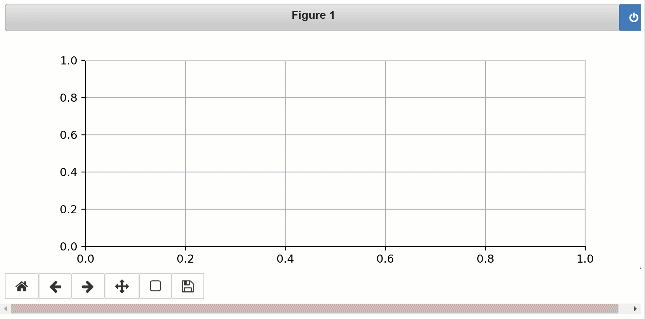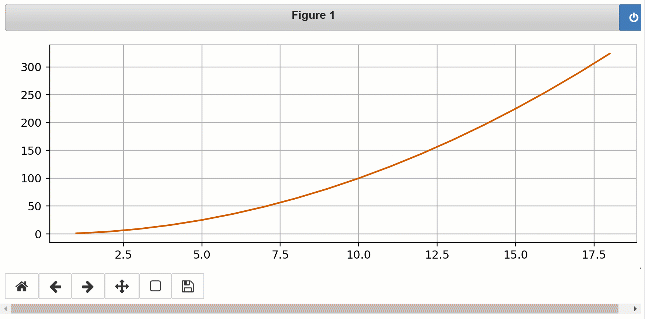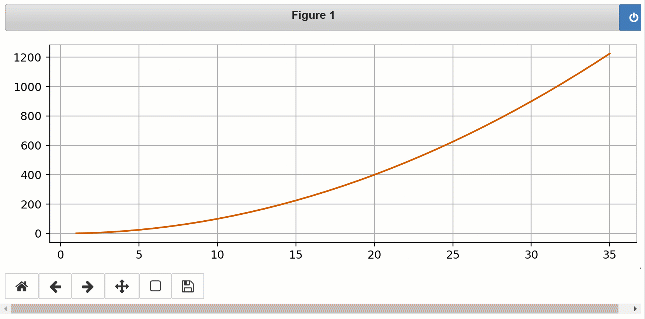
Para se aprofundar nos vários outros recursos, consulte Tutoriais e notebooks.
Quando você escreve em um fluxo de tensorwatch, os valores são serializados e enviados para um soquete TCP/IP, bem como o arquivo que você especificou. No notebook Jupyter, carregamos os valores registrados anteriormente do arquivo e, em seguida, ouvimos esse soquete TCP/IP para obter valores futuros. O visualizador ouve o fluxo e renderiza os valores à medida que chegam.
OK, então essa é uma descrição muito simplificada. A arquitetura TensorWatch é realmente muito mais poderosa. Quase tudo no TensorWatch é um fluxo . Arquivos, soquetes, consoles e até visualizadores são fluxos. Uma coisa interessante sobre os fluxos TensorWatch é que eles podem ouvir outros fluxos. Isso permite que o TensorWatch crie um gráfico de fluxo de dados . Isso significa que um visualizador pode ouvir muitos fluxos simultaneamente, cada um dos quais pode ser um arquivo, um soquete ou algum outro fluxo. Você pode estendê -lo recursivamente para criar gráficos de fluxo de dados arbitrários. O TensorWatch Decouples Streams de como eles são armazenados e como são visualizados.
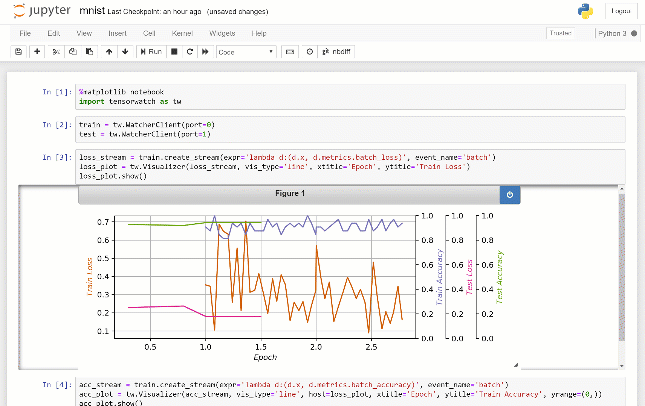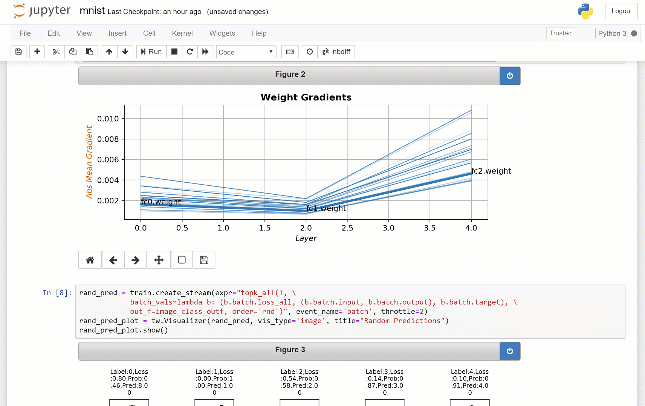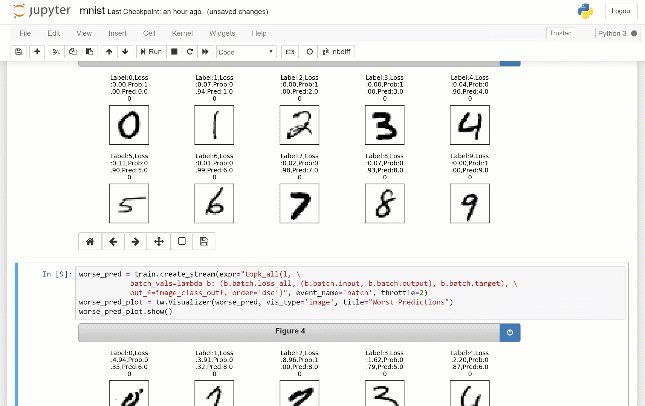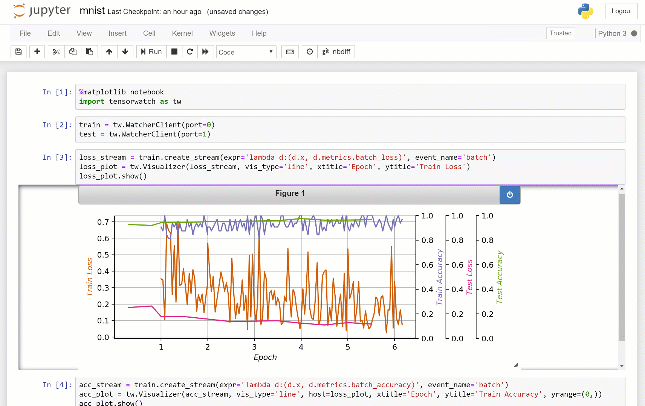
No exemplo acima, o gráfico de linha é usado como visualização padrão. No entanto, o TensorWatch suporta muitos outros tipos de diagrama, incluindo histogramas, gráficos de pizza, gráficos de dispersão, gráficos de barras e versões 3D de muitas dessas gráficos. Você pode registrar seus dados, especificar o tipo de gráfico desejado e deixar o TensorWatch cuidar do resto.
Um dos pontos fortes significativos do TensorWatch é a capacidade de combinar, compor e criar visualizações personalizadas sem esforço. Por exemplo, você pode optar por visualizar um número arbitrário de fluxos no mesmo gráfico. Ou você pode visualizar o mesmo fluxo em muitas parcelas diferentes simultaneamente . Ou você pode colocar um conjunto arbitrário de visualizações lado a lado. Você pode até criar seu próprio widget de visualização personalizada simplesmente criando uma nova classe Python, implementando alguns métodos.
Cada fluxo do TensorWatch pode conter uma métrica de sua escolha. Por padrão, o TensorWatch salva todos os fluxos em um único arquivo, mas você também pode optar por salvar cada fluxo em arquivos separados ou para não salvá -los (por exemplo, enviando fluxos sobre soquetes ou para o console diretamente, zero acerto no disco! ). Mais tarde, você pode abrir esses fluxos e direcioná -los para uma ou mais visualizações. Esse design permite comparar rapidamente os resultados de seus diferentes experimentos em sua escolha de visualizações facilmente.
Muitas vezes, você pode preferir fazer análise de dados, treinamento de ML e testes - tudo no Notebook Jupyter, em vez de de um script separado. O TensorWatch pode ajudá-lo a fazer visualizações sofisticadas e em tempo real sem esforço a partir do código que é executado em um notebook Jupyter de ponta a ponta.
Um recurso exclusivo no TensorWatch é a capacidade de consultar o processo de execução ao vivo, recuperar o resultado dessa consulta como um fluxo e direcionar esse fluxo para suas visualizações preferidas. Você não precisa registrar nenhum dado de antemão. Chamamos essa nova maneira de depurar e visualizar um modo de log preguiçoso .
Por exemplo, como visto abaixo, visualizamos pares de imagem de entrada e saída, amostrados aleatoriamente durante o treinamento de um autoencoder em um conjunto de dados de frutas. Essas imagens não foram registradas antecipadamente no script. Em vez disso, o usuário envia consulta como uma expressão de Python Lambda, que resulta em um fluxo de imagens que são exibidas no notebook Jupyter:

Veja o tutorial preguiçoso de registro.
O TensorWatch aproveita várias excelentes bibliotecas, incluindo Hiddenlayer, Torchstat, Attribuição Visual para permitir a execução das atividades usuais de depuração e análise em um pacote e interface consistentes.
Por exemplo, você pode visualizar o gráfico do modelo com formas tensoras com uma liner:
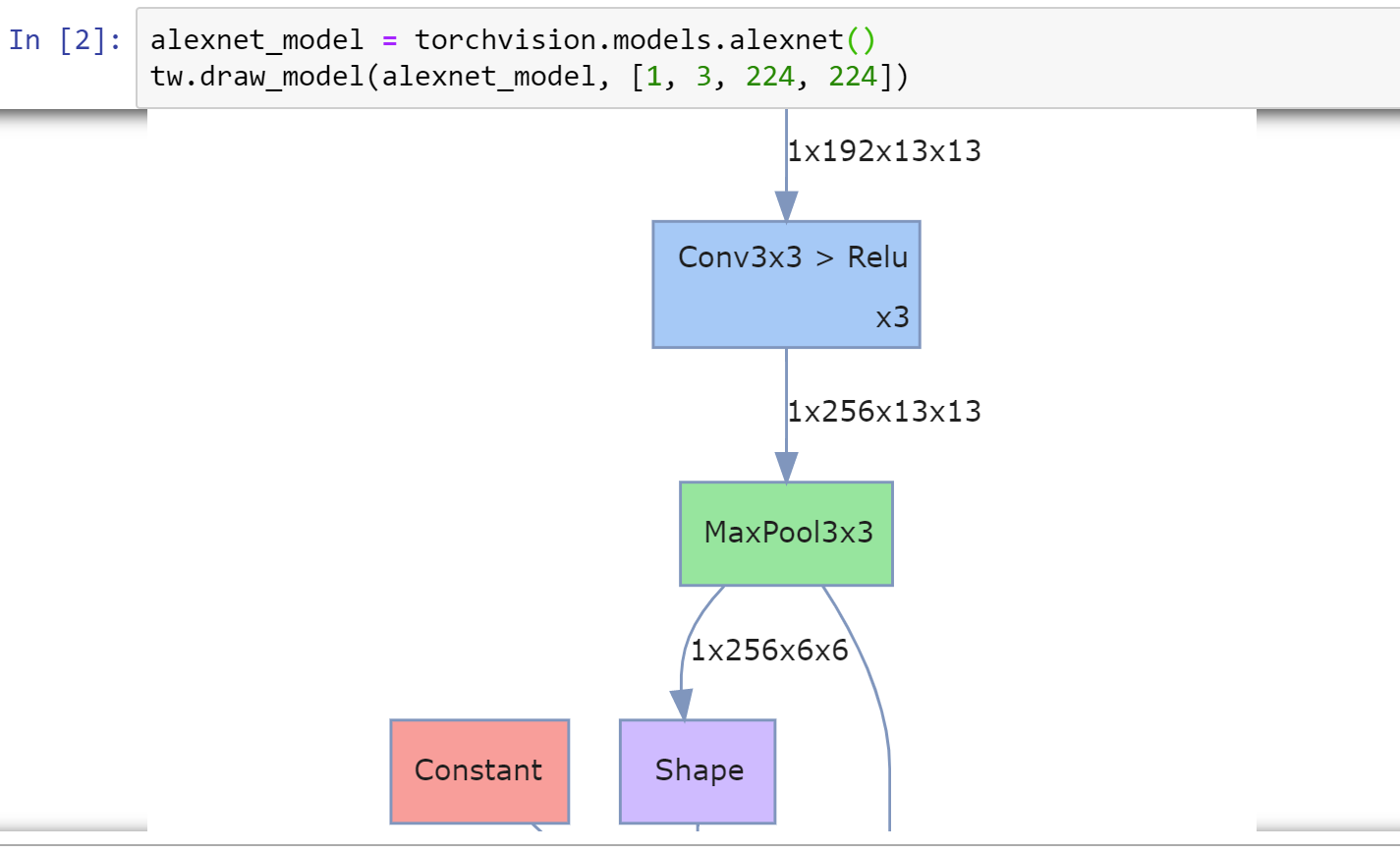
Você pode visualizar estatísticas para diferentes camadas, como falhas, número de parâmetros, etc:
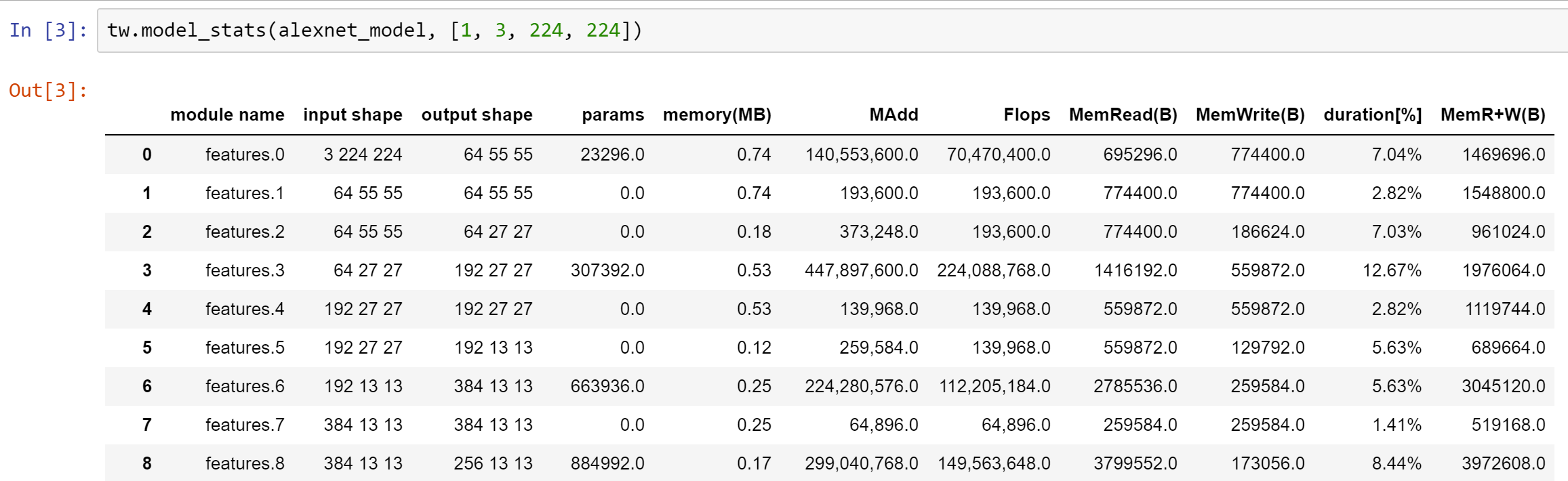
Veja notebook.
Você pode visualizar o conjunto de dados em um espaço dimensional inferior usando técnicas como T-SNE:
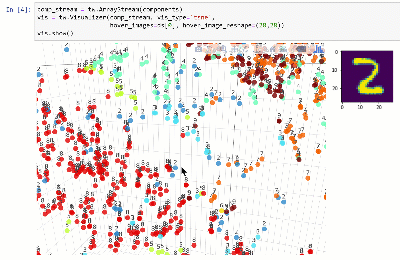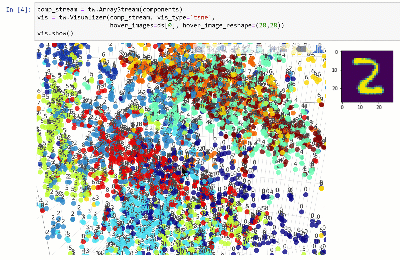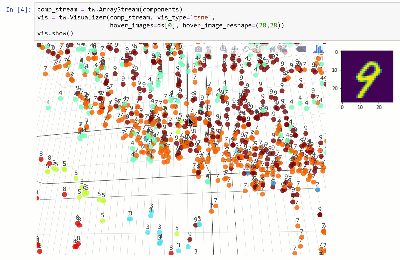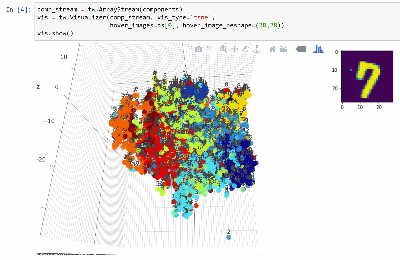
Veja notebook.
Desejamos fornecer várias ferramentas para explicar previsões para ajudar a depurar os modelos. Atualmente, oferecemos vários explicadores para redes convolucionais, incluindo cal. Por exemplo, os seguintes destaques as áreas que fazem com que o modelo RESNET50 faça uma previsão para a classe 240 para o conjunto de dados ImageNet:

Veja notebook.
Tutorial simples de registro
Tutorial de log preguiçoso
Usando o TensorWatch para treinamento de aprendizado profundo (MNIST)
Usando o TensorWatch para treinamento de aprendizado profundo (Food360)
Explorando dados usando t-sne
Expliques de predicação para redes neurais convolucionais
Visualizando o gráfico do modelo e as estatísticas
Mais detalhes técnicos estão disponíveis no TensorWatch Paper (conferência EICS 2019). Por favor, cite isso como:
@inproceedings{tensorwatch2019eics,
author = {Shital Shah and Roland Fernandez and Steven M. Drucker},
title = {A system for real-time interactive analysis of deep learning training},
booktitle = {Proceedings of the {ACM} {SIGCHI} Symposium on Engineering Interactive
Computing Systems, {EICS} 2019, Valencia, Spain, June 18-21, 2019},
pages = {16:1--16:6},
year = {2019},
crossref = {DBLP:conf/eics/2019},
url = {https://arxiv.org/abs/2001.01215},
doi = {10.1145/3319499.3328231},
timestamp = {Fri, 31 May 2019 08:40:31 +0200},
biburl = {https://dblp.org/rec/bib/conf/eics/ShahFD19},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
Adoraríamos suas contribuições, feedback, perguntas e solicitações de recursos! Por favor, registre um problema do GitHub ou envie -nos uma solicitação de tração. Revise o Código de Conduta da Microsoft e saiba mais.
Participe do grupo TensorWatch no Facebook para se manter atualizado ou fazer qualquer pergunta.
O TensorWatch utiliza várias bibliotecas de código aberto para muitos de seus recursos. Isso inclui: HiddenLayer, Torchstat, visual-atribuição, PYZMQ, ReceptiveField, NBFformat. Consulte a seção install_requires no setup.py para a lista de data.
Este projeto é divulgado sob a licença do MIT. Revise o arquivo de licença para obter mais detalhes.


