tensorwatch
1.0.0
TensorWatch est un outil de débogage et de visualisation conçu pour la science des données, l'apprentissage en profondeur et l'apprentissage du renforcement de Microsoft Research. Il fonctionne dans Jupyter Notebook pour montrer des visualisations en temps réel de votre formation d'apprentissage automatique et effectuer plusieurs autres tâches d'analyse clés pour vos modèles et données.
TensorWatch est conçu pour être flexible et extensible afin que vous puissiez également créer vos propres visualisations, UIS et tableaux de bord personnalisés. Outre l'approche traditionnelle "ce que vous êtes-vous-vous-vous-vous", il a également une capacité unique d'exécuter des requêtes arbitraires contre votre processus de formation en direct ML, renvoyez un flux à la suite de la requête et visualisez ce flux en utilisant Votre choix de visualiseur (nous appelons ce mode de journalisation paresseux).
TensorWatch est en cours de développement lourd dans le but de fournir une plate-forme pour déboguer l'apprentissage automatique dans un package facile à utiliser, extensible et piratable.
pip install tensorwatch
TensorWatch prend en charge Python 3.x et est testé avec Pytorch 0.4-1.x. La plupart des fonctionnalités devraient également fonctionner avec des tenseurs tenaces tensorflow. TensorWatch utilise Graphviz pour créer des diagrammes de réseau et en fonction de votre plate-forme, vous devrez peut-être l'installer manuellement.
Voici un code simple qui enregistre un entier et son carré comme un tuple à chaque seconde à TensorWatch:
import tensorwatch as tw
import time
# streams will be stored in test.log file
w = tw.Watcher(filename='test.log')
# create a stream for logging
s = w.create_stream(name='metric1')
# generate Jupyter Notebook to view real-time streams
w.make_notebook()
for i in range(1000):
# write x,y pair we want to log
s.write((i, i*i))
time.sleep(1)
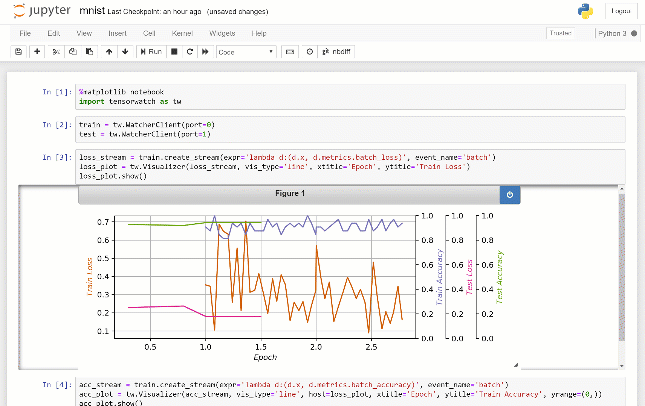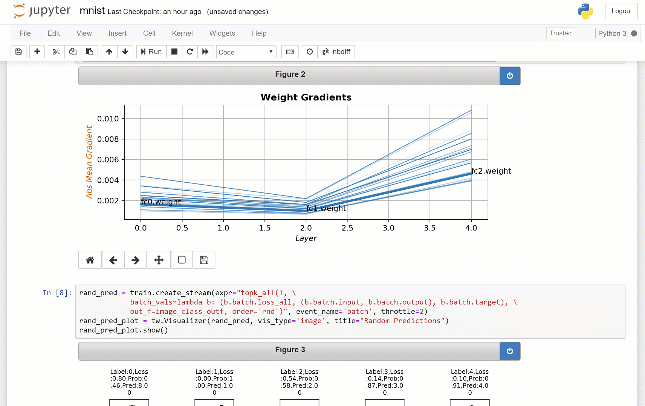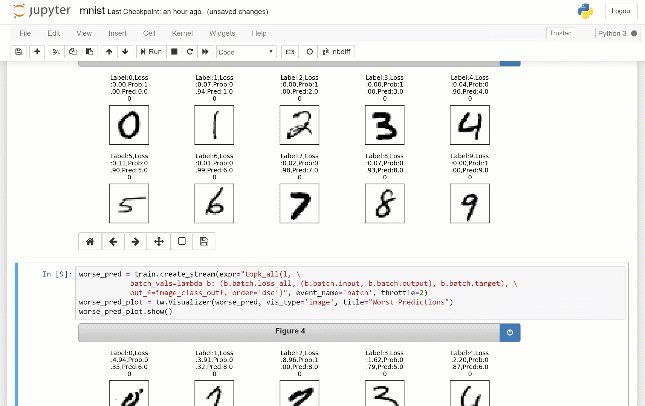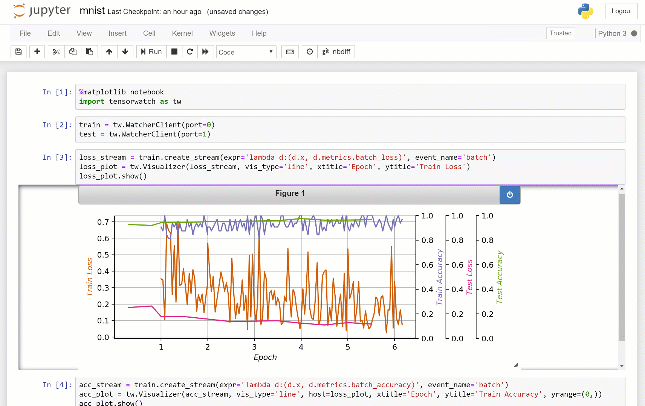
Lorsque vous exécutez ce code, vous remarquerez un fichier Jupyter Notebook test.ipynb est créé dans votre dossier de script. À partir d'un jupyter notebook de commande et sélectionnez test.ipynb . Choisissez Cell> Exécutez tout dans le menu pour voir le graphique de ligne en temps réel au fur et à mesure que les valeurs sont écrites dans votre script.
Voici la sortie que vous verrez dans Jupyter Notebook:
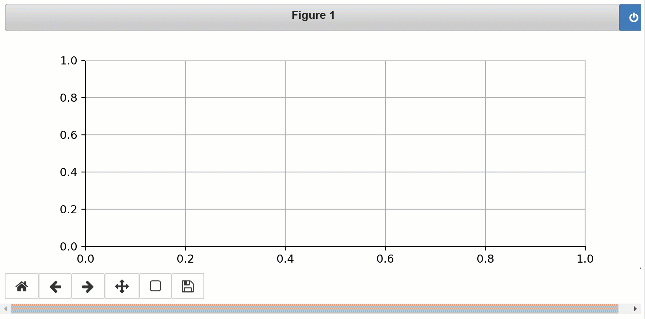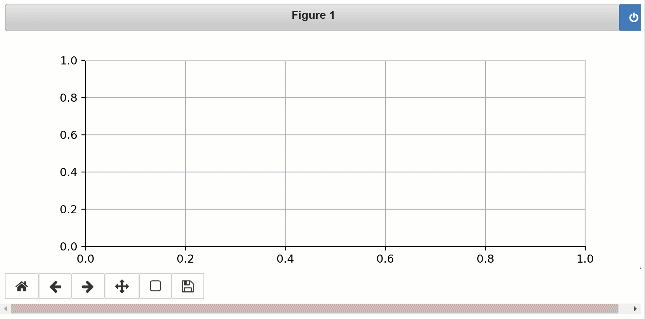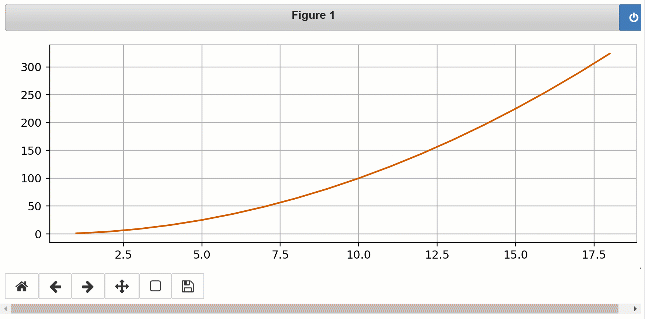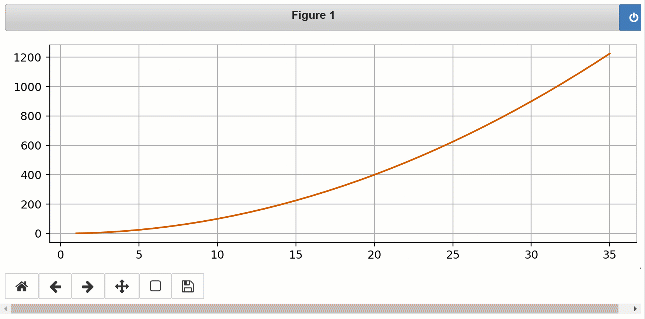
Pour plonger plus profondément dans les différentes autres fonctionnalités, veuillez consulter les tutoriels et les cahiers.
Lorsque vous écrivez dans un flux TensorWatch, les valeurs sont sérialisées et envoyées à une prise TCP / IP ainsi que le fichier que vous avez spécifié. À partir du cahier Jupyter, nous chargeons les valeurs précédemment enregistrées à partir du fichier, puis écoutons cette prise TCP / IP pour toutes les valeurs futures. Le visualiseur écoute le flux et rend les valeurs à leur arrivée.
Ok, c'est donc une description très simplifiée. L'architecture TensorWatch est en fait beaucoup plus puissante. Presque tout dans TensorWatch est un flux . Les fichiers, les prises, les consoles et même les visualiseurs sont eux-mêmes des flux. Une chose cool à propos des flux TensorWatch est qu'ils peuvent écouter d'autres flux. Cela permet à TensorWatch de créer un graphique de flux de données . Cela signifie qu'un visualiseur peut écouter de nombreux flux simultanément, chacun pourrait être un fichier, une prise ou un autre flux. Vous pouvez l'étendre récursivement pour créer des graphiques de flux de données arbitraires. TensorWatch Decouples diffuse de la façon dont ils sont stockés et de la façon dont ils sont visualisés.
Dans l'exemple ci-dessus, le graphique linéaire est utilisé comme visualisation par défaut. Cependant, TensorWatch prend en charge de nombreux autres types de diagrammes, notamment des histogrammes, des graphiques circulaires, des graphiques de dispersion, des graphiques à barres et des versions 3D de bon nombre de ces parcelles. Vous pouvez enregistrer vos données, spécifier le type de graphique souhaité et laisser TensorWatch s'occuper du reste.
L'une des forces importantes de TensorWatch est la capacité de combiner, composer et créer des visualisations personnalisées sans effort. Par exemple, vous pouvez choisir de visualiser un nombre arbitraire de flux dans le même tracé. Ou vous pouvez visualiser simultanément le même flux dans de nombreuses parcelles différentes. Ou vous pouvez placer un ensemble arbitraire de visualisations côte à côte. Vous pouvez même créer votre propre widget de visualisation personnalisé simplement en créant une nouvelle classe Python, implémentant quelques méthodes.
Chaque flux TensorWatch peut contenir une métrique de votre choix. Par défaut, TensorWatch enregistre tous les flux dans un seul fichier, mais vous pouvez également choisir d'enregistrer chaque flux dans des fichiers séparés ou de ne pas les enregistrer du tout (par exemple, en envoyant des flux sur des sockets ou dans la console directement, zéro hit to disk! ). Plus tard, vous pouvez ouvrir ces flux et les diriger vers une ou plusieurs visualisations. Cette conception vous permet de comparer rapidement les résultats de vos différentes expériences dans votre choix de visualisations facilement.
Souvent, vous pouvez préférer effectuer l'analyse des données, la formation ML et les tests - le tout à partir du cahier Jupyter plutôt que d'un script séparé. TensorWatch peut vous aider à faire des visualisations sophistiquées en temps réel sans effort à partir du code qui est exécuté dans un cahier Jupyter de bout en bout.
Une fonctionnalité unique dans TensorWatch est la possibilité d'interroger le processus de fonctionnement en direct, de récupérer le résultat de cette requête en tant que flux et de diriger ce flux vers vos visualisations préférées. Vous n'avez pas besoin de enregistrer des données à l'avance. Nous appelons cette nouvelle façon de déboguer et de visualiser un mode de journalisation paresseux .
Par exemple, comme le montre ci-dessous, nous visualisons les paires d'images d'entrée et de sortie, échantillonnées au hasard lors de la formation d'un autoencoder sur un ensemble de données Fruits. Ces images n'ont pas été enregistrées au préalable dans le script. Au lieu de cela, l'utilisateur envoie une requête sous forme d'expression python lambda qui se traduit par un flux d'images qui s'affiche dans le cahier Jupyter:

Voir le tutoriel de journalisation paresseuse.
TensorWatch exploite plusieurs excellentes bibliothèques, notamment HiddenLayer, TorchStat, l'attribution visuelle pour permettre l'exécution des activités de débogage et d'analyse habituelles dans un package et une interface cohérents.
Par exemple, vous pouvez afficher le graphique du modèle avec des formes de tensor avec une seule ligne:
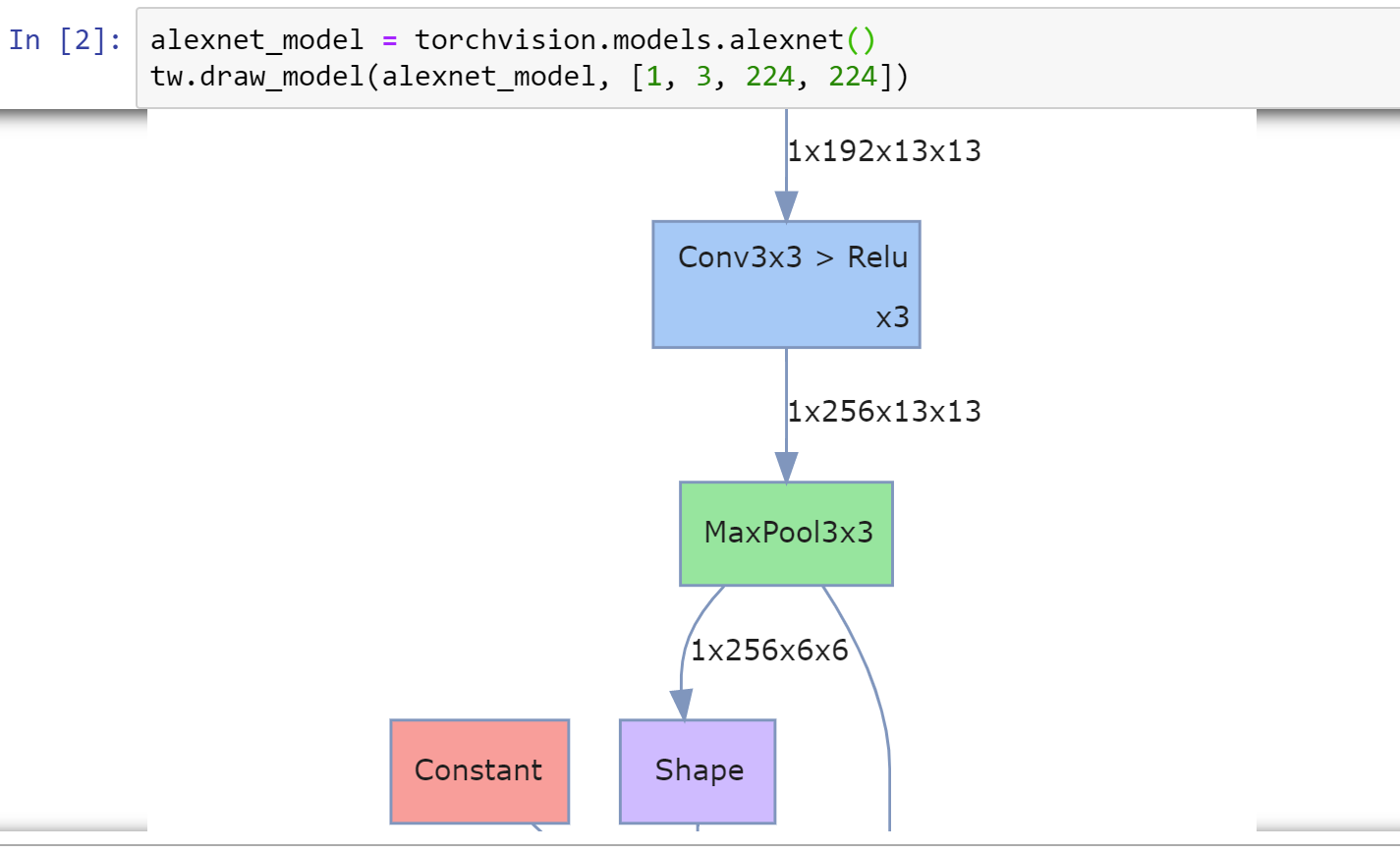
Vous pouvez afficher les statistiques pour différentes couches telles que les flops, le nombre de paramètres, etc.:
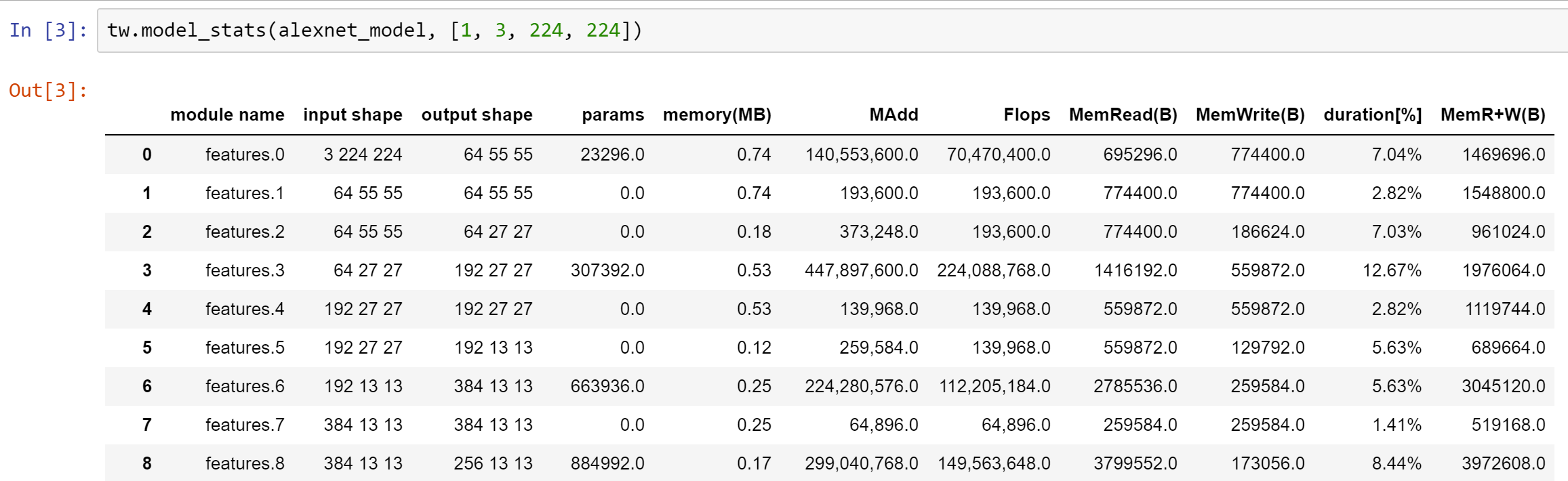
Voir Notebook.
Vous pouvez afficher l'ensemble de données dans un espace dimensionnel inférieur à l'aide de techniques telles que T-SNE:
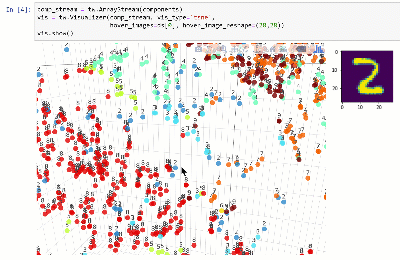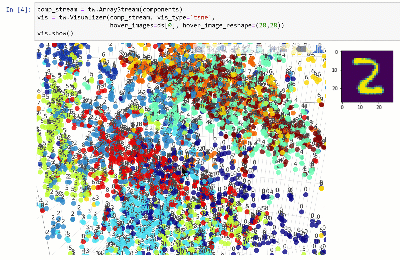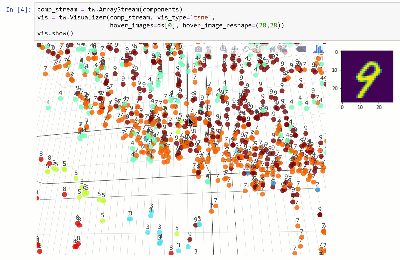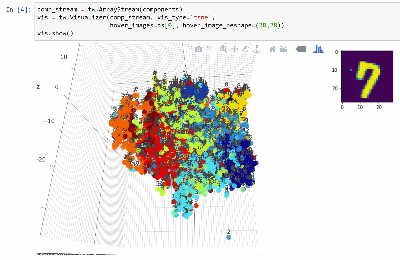
Voir le cahier.
Nous souhaitons fournir divers outils pour expliquer les prédictions pour aider à déboguer les modèles. Actuellement, nous proposons plusieurs explicateurs pour les réseaux convolutionnels, y compris la chaux. Par exemple, ce qui suit met en évidence les domaines qui font que le modèle RESNET50 fait une prédiction pour la classe 240 pour l'ensemble de données ImageNet:

Voir le cahier.
Tutoriel de journalisation simple
Tutoriel de journalisation paresseuse
Utilisation de TensorWatch pour la formation en profondeur (MNIST)
Utilisation de TensorWatch pour la formation en profondeur (Food360)
Exploration des données à l'aide de T-SNE
Explicateurs de prédication pour les réseaux de neurones convolutionnels
Affichage du graphique du modèle et des statistiques
Plus de détails techniques sont disponibles dans TensorWatch Paper (conférence EICS 2019). Veuillez citer ceci comme:
@inproceedings{tensorwatch2019eics,
author = {Shital Shah and Roland Fernandez and Steven M. Drucker},
title = {A system for real-time interactive analysis of deep learning training},
booktitle = {Proceedings of the {ACM} {SIGCHI} Symposium on Engineering Interactive
Computing Systems, {EICS} 2019, Valencia, Spain, June 18-21, 2019},
pages = {16:1--16:6},
year = {2019},
crossref = {DBLP:conf/eics/2019},
url = {https://arxiv.org/abs/2001.01215},
doi = {10.1145/3319499.3328231},
timestamp = {Fri, 31 May 2019 08:40:31 +0200},
biburl = {https://dblp.org/rec/bib/conf/eics/ShahFD19},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
Nous aimerions vos contributions, vos commentaires, vos questions et vos demandes de fonctionnalités! Veuillez déposer un problème GitHub ou nous envoyer une demande de traction. Veuillez consulter le code de conduite Microsoft et en savoir plus.
Rejoignez le groupe TensorWatch sur Facebook pour rester à jour ou poser des questions.
TensorWatch utilise plusieurs bibliothèques open source pour bon nombre de ses fonctionnalités. Ceux-ci incluent: Hiddenlayer, TorchStat, Visual-Attribution, PyZMQ, ReceptiveField, NBFormat. Veuillez consulter la section install_requires dans setup.py pour la liste de date.
Ce projet est publié sous la licence du MIT. Veuillez consulter le fichier de licence pour plus de détails.


