advanced value counts
1.0.0
Advanced-Value-Counts는 Pandas ' .value_counts() , .groupby() 및 Seaborn을 사용하는 AdvancedValueCounts 클래스를 포함하는 Python-Package입니다. 이 패키지의 잠재력은 그룹화 후 열의 수에 대한 정보 df.groupby(groupby_col)[column].value_counts() 원할 때 정점에 달합니다. AdvancedValueCounts 사용 방법에 대한 사용법을 참조하십시오. 이 중간 기사를 읽 거나이 패키지의 부가 가치에 대한 설명을 보려면이 노트북에 문의하십시오.
목차 :
pip install advanced-value-counts
오류가 표면에 있으면 PIP 및 SetUptools를 업그레이드하십시오
python3 -m pip install --upgrade pip
python3 -m pip install --upgrade setuptools
git clone https://github.com/sTomerG/advanced-value-counts.git
cd advanced-value-counts
pip install -e .
# optional but potentially crucial
pip install -r requirements/requirements.txt
Advanced-Value-Counts 디렉토리에서 설치가 성공했는지 여부 를 테스트하려면
pytest
아래의 예는 Kaggle의 수정 된 타이타닉 데이터 세트를 사용합니다.이 gitrepo에서 볼 수 있습니다.
이 노트북의 코드는 여기에서 찾을 수 있습니다.
from advanced_value_counts . avc import AdvancedValueCounts
import pandas as pd
# read in the data file
df = pd . read_csv ( '../tests/data/titanic.csv' , usecols = [ 'CabinArea' , 'Title' ])
df . head ()| 캐비너리 | 제목 | |
|---|---|---|
| 0 | 난 | 씨. |
| 1 | 기음 | 부인 |
| 2 | 난 | 놓치다. |
| 3 | 기음 | 부인 |
| 4 | 난 | 씨. |
# create an instance of AdvancedValueCounts
avc = AdvancedValueCounts ( df = df , column = 'Title' )
# print the AdvancedValueCounts DataFrame
avc . avc_df| 비율 | 세다 | |
|---|---|---|
| 제목 | ||
| 씨. | 0.580247 | 517 |
| 놓치다. | 0.204265 | 182 |
| 부인 | 0.140292 | 125 |
| 주인. | 0.044893 | 40 |
| _na | 0.007856 | 7 |
| 회전. | 0.006734 | 6 |
| 주요한. | 0.002245 | 2 |
| 안부. | 0.002245 | 2 |
| mlle. | 0.002245 | 2 |
| 백작 부인. | 0.001122 | 1 |
| 캡틴 | 0.001122 | 1 |
| 미스 | 0.001122 | 1 |
| 선생님. | 0.001122 | 1 |
| 숙녀. | 0.001122 | 1 |
| mme. | 0.001122 | 1 |
| 두목. | 0.001122 | 1 |
| Jonkheer. | 0.001122 | 1 |
min_group_count 5로 설정하여 소그룹을 '_other' 그룹으로 그룹화하십시오.
avc . min_group_count = 5
avc . avc_df| 비율 | 세다 | |
|---|---|---|
| 제목 | ||
| 씨. | 0.580247 | 517 |
| 놓치다. | 0.204265 | 182 |
| 부인 | 0.140292 | 125 |
| 주인. | 0.044893 | 40 |
| _다른 | 0.015713 | 14 |
| _na | 0.007856 | 7 |
| 회전. | 0.006734 | 6 |
단일 열의 소규모 그룹에 맞게 조정하려면 AdvancedValueCounts 클래스의 매개 변수 :
dropna : bool = False
min_group_count : int = 1 # does not effect NA or the '_other' group
min_group_ratio : float = 0 # does not effect NA or the '_other' group df.groupby(groupby_col)[column].value_counts() 의 동작을 모방하기 위해 매개 변수 groupy_col: str = None 과 함께 column 사용할 수도 있습니다.
avc_grouped = AdvancedValueCounts ( df = df , column = 'Title' , groupby_col = 'CabinArea' )
avc_grouped . avc_df| 세다 | subgroup_ratio | subgr_r_diff_subgr_all | R_VS_TOTAL | ||
|---|---|---|---|---|---|
| 캐비너리 | 제목 | ||||
| 에이 | 안부. | 1 | 0.066667 | 0.064422 | 0.001122 |
| 숙녀. | 1 | 0.066667 | 0.065544 | 0.001122 | |
| 주인. | 1 | 0.066667 | 0.021773 | 0.001122 | |
| 씨. | 11 | 0.733333 | 0.153086 | 0.012346 | |
| 선생님. | 1 | 0.066667 | 0.065544 | 0.001122 | |
| ... | ... | ... | ... | ... | ... |
| _na | 부인 | 81 | 0.117904 | -0.022388 | 0.090909 |
| 미스 | 1 | 0.001456 | 0.000333 | 0.001122 | |
| 회전. | 6 | 0.008734 | 0.002000 | 0.006734 | |
| _na | 4 | 0.005822 | -0.002034 | 0.004489 | |
| _총 | 687 | 1.000000 | 0.000000 | 0.771044 |
74 행 × 4 열
데이터에 대한 더 나은 개요를 얻으려면 속성을 설정하여 그룹 크기를 조정하고 비율을 반올림합니다.
avc_grouped . min_group_ratio = 0.05
avc_grouped . min_subgroup_count = 5
avc_grouped . round_ratio = 3
avc_grouped . avc_df| 세다 | subgroup_ratio | subgr_r_diff_subgr_all | R_VS_TOTAL | ||
|---|---|---|---|---|---|
| 캐비너리 | 제목 | ||||
| 비 | 놓치다. | 14 | 0.298 | 0.094 | 0.016 |
| 씨. | 16 | 0.340 | -0.240 | 0.018 | |
| 부인 | 10 | 0.213 | 0.073 | 0.011 | |
| _na | 1 | 0.021 | 0.013 | 0.001 | |
| _다른 | 6 | 0.127 | 0.111 | 0.007 | |
| _총 | 47 | 1.000 | 0.000 | 0.053 | |
| 기음 | 놓치다. | 12 | 0.203 | -0.001 | 0.013 |
| 씨. | 29 | 0.492 | -0.088 | 0.033 | |
| 부인 | 14 | 0.237 | 0.097 | 0.016 | |
| _na | 1 | 0.017 | 0.009 | 0.001 | |
| _다른 | 3 | 0.051 | 0.035 | 0.003 | |
| _총 | 59 | 1.000 | 0.000 | 0.066 | |
| _모두 | 주인. | 40 | 0.045 | 난 | 0.045 |
| 놓치다. | 182 | 0.204 | 난 | 0.204 | |
| 씨. | 517 | 0.580 | 난 | 0.580 | |
| 부인 | 125 | 0.140 | 난 | 0.140 | |
| 회전. | 6 | 0.007 | 난 | 0.007 | |
| _na | 7 | 0.008 | 난 | 0.008 | |
| _다른 | 14 | 0.016 | 난 | 0.016 | |
| _총 | 891 | 1.000 | 난 | 1.000 | |
| _na | 주인. | 33 | 0.048 | 0.003 | 0.037 |
| 놓치다. | 135 | 0.197 | -0.007 | 0.152 | |
| 씨. | 424 | 0.617 | 0.037 | 0.476 | |
| 부인 | 81 | 0.118 | -0.022 | 0.091 | |
| 회전. | 6 | 0.009 | 0.002 | 0.007 | |
| _na | 4 | 0.006 | -0.002 | 0.004 | |
| _다른 | 4 | 0.006 | -0.010 | 0.004 | |
| _총 | 687 | 1.000 | 0.000 | 0.771 | |
| _다른 | 주인. | 5 | 0.051 | 0.006 | 0.006 |
| 놓치다. | 21 | 0.214 | 0.010 | 0.024 | |
| 씨. | 48 | 0.490 | -0.090 | 0.054 | |
| 부인 | 20 | 0.204 | 0.064 | 0.022 | |
| _na | 1 | 0.010 | 0.002 | 0.001 | |
| _다른 | 3 | 0.031 | 0.015 | 0.003 | |
| _총 | 98 | 1.000 | 0.000 | 0.110 |
그룹화 된 AdvancedValueCounts 에서 Groupsize를 조정하기 위해 AdvancedValueCounts 클래스의 매개 변수
# for groupby_col:
dropna : bool = False
max_groups : int = None # does not effect NA or the '_other' group
min_group_count : int = 1 # does not effect NA or the '_other' group
min_group_ratio : float = 0 # does not effect NA or the '_other' group
# for column:
dropna : bool = False
max_subgroups : int = None # does not effect NA or the '_other' group
min_subgroup_count : int = 1 # does not effect NA or the '_other' group
min_subgroup_ratio : float = 0 # does not effect NA or the '_other' group
min_subgroup_ratio_vs_total : float = 0 # does not effect NA or the '_other' group AdvancedValueCounts.avc_df 의 플롯을 얻으려면 :
avc_grouped . get_plot ( normalize = True ) # normalize = True is default value 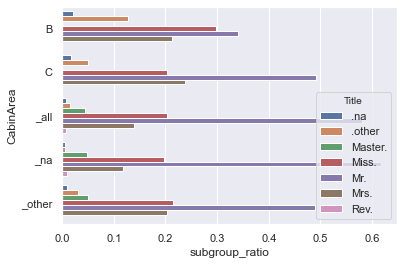
'_all' 및 '_total' 과 같은 summary_statistics없이 데이터 프레임을 얻으려면 :
avc_grouped . unsummerized_df| 세다 | subgroup_ratio | subgr_r_diff_subgr_all | R_VS_TOTAL | ||
|---|---|---|---|---|---|
| 캐비너리 | 제목 | ||||
| 비 | 놓치다. | 14 | 0.298 | 0.094 | 0.016 |
| 씨. | 16 | 0.340 | -0.240 | 0.018 | |
| 부인 | 10 | 0.213 | 0.073 | 0.011 | |
| _na | 1 | 0.021 | 0.013 | 0.001 | |
| _다른 | 6 | 0.127 | 0.111 | 0.007 | |
| 기음 | 놓치다. | 12 | 0.203 | -0.001 | 0.013 |
| 씨. | 29 | 0.492 | -0.088 | 0.033 | |
| 부인 | 14 | 0.237 | 0.097 | 0.016 | |
| _na | 1 | 0.017 | 0.009 | 0.001 | |
| _다른 | 3 | 0.051 | 0.035 | 0.003 | |
| _na | 주인. | 33 | 0.048 | 0.003 | 0.037 |
| 놓치다. | 135 | 0.197 | -0.007 | 0.152 | |
| 씨. | 424 | 0.617 | 0.037 | 0.476 | |
| 부인 | 81 | 0.118 | -0.022 | 0.091 | |
| 회전. | 6 | 0.009 | 0.002 | 0.007 | |
| _na | 4 | 0.006 | -0.002 | 0.004 | |
| _다른 | 4 | 0.006 | -0.010 | 0.004 | |
| _다른 | 주인. | 5 | 0.051 | 0.006 | 0.006 |
| 놓치다. | 21 | 0.214 | 0.010 | 0.024 | |
| 씨. | 48 | 0.490 | -0.090 | 0.054 | |
| 부인 | 20 | 0.204 | 0.064 | 0.022 | |
| _na | 1 | 0.010 | 0.002 | 0.001 | |
| _다른 | 3 | 0.031 | 0.015 | 0.003 |
git clone https://github.com/sTomerG/advanced-value-counts.git
cd advanced-value-counts
python3 -m venv .venv
가상 환경을 활성화하십시오
Windows :
..venvScriptsactivate
Linux / MacOS :
source .venv/bin/activate
요구 사항을 설치하십시오
python -m pip install --upgrade pip
pip install -r requirements/requirements.txt
모든 것이 제대로 작동하는지 테스트하십시오
( 감가 상각수가 예상됩니다)
Tox와 함께
tox
독소없이
pip install -e .
pytest


